groupx()
Here’s how to use groupx() function.
ch.gr oupx()
Description:
Group records in a channel and return a channel.
Syntax:
ch.groupx(x:F,…;y:G…)
Note:
The function groups records in channel ch according to grouping expression xto get a channel having F,...G,… fields. The result table sequence in the channel is ordered by x.Values of G field are the results of computing expression y, which is an aggregate function executed on ch, over each group. It aims to fetch the grouping result set from the channel.
Option:
|
@n |
With the option the value of expression x is a group number, which points to the desired group |
Parameter:
|
ch |
Channel |
|
x |
Grouping expression |
|
F |
Field name in the resulting table sequence |
|
y |
An aggregate function on channel ch, which only supports sum/count/max/min/top /avg/iterate; the parameter Gi should be given up if function iterate(x,a;Gi,…) is used |
|
G |
The aggregate fields in the resulting table sequence |
Return value:
Channel
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from EMPLOYEE ") |
|
|
2 |
=channel() |
Create a channel. |
|
3 |
=channel() |
Create a channel. |
|
4 |
=A1.push(A2,A3) |
Be ready to push the data in A1’s cursor into A2’s channel and A3’s channel, but the action needs to wait. |
|
5 |
=A2.groupx(DEPT:dept;sum(SALARY):TotalSalary) |
Group and sort records by DEPT field. |
|
6 |
=A3.groupx@n(if(GENDER=="F",1,2):SubGroups;sum(SALARY):TotalSalary) |
The value of expression x is a group number; put records where GENDER is “F” into the first group and others into the second group, and then aggregate each group. |
|
7 |
=A1.select(month(BIRTHDAY)==2) |
|
|
8 |
=A1.fetch() |
Attach a fetch operation to A7’s cursor. |
|
9 |
=A2.result() |
Return the result as a cursor. |
|
10 |
=A3.result() |
Return the result as a cursor. |
cs.g roupx()
Description:
Group the ordered records in a cursor and return result as a cursor.
Syntax:
cs.groupx(x:F,…;y:G…;n)
Note:
The function groups records in a cursor by grouping expression x to create a new cursor consisting of fields F,...G,… sorted by the grouping field x. The G field gets values by computing y – the aggregate function with which records of cs is aggregated – on each group. The cursor the function returns is irreversible.
Option:
|
@n |
x gets assigned with group numbers which can be used to define the groups. |
|
@u |
Won’t sort the result set by parameter x; mutually exclusive with @n. |
|
@g |
Treat parameter n as the segmentation expression by which records are first segmented and then grouped and sorted. |
Parameter:
|
cs |
A cursor; when it is a multicursor, the function retrieves and groups records through multithreaded processing, and returns a unicursor. |
|
x |
Grouping expression. |
|
F |
Result field name. |
|
y |
Aggregate function on cs, which only supports sum/count/max/min/top/ avg/iterate. When the function works with the iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted. |
|
G |
Aggregate field name. |
|
n |
Number of buffer rows; if the number of groups reaches n, write the grouping result to a temporary file; its value is n times of the default, which is automatically calculated, if n<1. |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
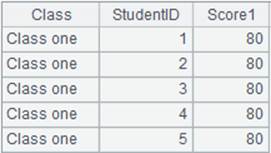
=demo.cursor("select * from SCORES where CLASS='Class one'") |
|
|
2 |
=A1.groupx(STUDENTID:ID;sum(SCORE):Scores).fetch() |
|
|
3 |
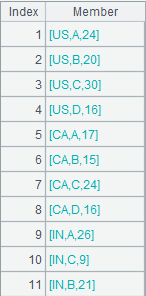
=demo .cursor("select * from FAMILY") |
|
|
4 |
=A3.groupx@n(if(GENDER=="Male",1,2):ID;sum(AGE):TotalAge).fetch() |
The value of grouping expression is a group number. Put records whose GENDER is "Male" to the first group, and others to the second group. Meanwhile, aggregate every group of records. |
|
5 |
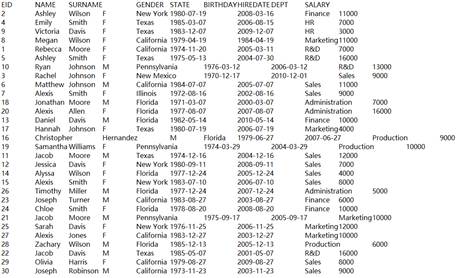
=demo.cursor("select * from EMPLOYEE") |
|
|
6 |
=A5.groupx@u(STATE:State;count(STATE):TotalScore).fetch() |
The result set isn’t sorted. |
|
7 |
=demo.cursor("select * from EMPLOYEE where EID <=20") |
|
|
8 |
=A7.groupx@g(GENDER;min(SALARY);EID>=10).fetch() |
Segment records by the segmentation condition EID>=10 and then calcualte min(SALARY); the last two records are the result of segmentation by EID>=10. |
|
9 |
=demo.cursor("select * from SCORES").groupx(STUDENTID:ID;sum(SCORE):Scores;3) |
Since the number of groups reaches 3, write the grouping result to a temporary file. |

Related function:
cs.groupx()
Description:
Group records in a cluster cursor and return a synchronously segmented cursor.
Syntax:
cs.groupx(x:F,…;y:G…;n)
Note:
The function groups records in cluster cursor cs by grouping expression x to create a new cluster cursor consisting of fields F,...G,… sorted by the grouping field x. G field gets values by computing y – the aggregate function with which records of cs is aggregated – on each group.
Parameter:
|
cs |
A cluster cursor |
|
x |
Grouping expression |
|
F |
Resulting field name |
|
y |
An aggregate function on cs, which only supports sum/count/max/min/top/avg/iterate; when the function works with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted |
|
G |
Aggregate field name |
|
n |
Number of buffer rows; if the number of groups reaches n, write the grouping result to a temporary file; its value is n times of the default, which is automatically calculated, if n<1 |
Return value:
A cluster cursor
Example:
|
|
A |
|
|
1 |
[192.168.31.72:8281, 192.168.31.72:8291] |
|
|
2 |
=file("orderpart.ctx":[1], A1) |
Open a cluster file. |
|
3 |
=A2. open () |
Open a cluster composite table. |
|
4 |
=A3.cursor() |
Return a cluster cursor. |
|
5 |
=A4.groupx(EID:ID;count(~):IdCount) |
Group A7 and perform count by EID, and return a cluster cursor. |
|
6 |
=A5.fetch() |
|
|
7 |
=A3.cursor() |
|
|
8 |
=A7.groupx(if(EID==4,1,2):ID;count(~):IdCount) |
Put records where EID is 4 into the first group and others into the second group, and then count the EID values. |
|
9 |
=A8.fetch() |
|
|
10 |
=A7.groupx(if(EID<=10):ID;count(~):IdCount;2) |
Since the number of groups reaches 2, write the grouping result to a temporary file. |