export()
Here’s how to use export() function.
A.export()
Description:
Convert a sequence into a string.
Syntax:
A.export(x:F,…;s)
Note:
The function separates each selected fields x of records in table sequence/record sequence/sequence A with the user-defined separator and returns the result as a string. The name of the resulting field in the string is F. If x isn’t specified, then export all fields. Return a one-field string without a field name if A is a simple sequence; use separator when A's members are sequences. A serial byte value is stored as an integer.
If parameters x:F are absent and if A is a sequence of record, then these records should be of same structure.
The function returns JSON strings when members of each member of A is record, sequence or table sequence; and returns a hexadecimal string when records or members of A are serial byte keys.
Note: In the returned string, use line break to separate records and custom delimiter to separate fields. By default, use TAB to separate both.
Parameter:
|
A |
A table sequence/record sequence/sequence to be exported |
|
x |
Fields to be exported; if omitted, then export all fields of A |
|
F |
Name of the resulting field in the string; if omitted, then use the original field name |
|
s |
User-defined field separator; default is TAB |
Option:
|
@t |
The column names will be written to the string as the first record |
|
@c |
Use comma as the separator when parameter s is absent |
|
@w |
Use Windows-style \r\n line break; by default, the line break is specified by the operating system |
|
@q |
Enclose the exported text field values and headers with quotation marks |
|
@o |
Perform escaping according to the Excel rule, which treats two double quotation marks as one and does not escape the other characters; need to work with @q |
Return value:
String
Example:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME from EMPLOYEE") |
|
|
2 |
=A1.export() |
Parameters x, F, and s are omitted. |
|
3 |
=A1.export(;"|") |
Specify the separator as "|". |
|
4 |
=A1.export@t(EID:id,NAME:name;",") |
Specify to-be-exported fields and the separator; make column names the first record and write it at the beginning of the exported string. |
|
5 |
[1,23,34,45] |
A sequence. |
|
6 |
=A5.export() |
|
|
7 |
=A1.export@c() |
|
|
8 |
=A1.export@w() |
|
|
9 |
=["12\r34","aa\nbb"] |
|
|
10 |
=A9.export() |
|
|
11 |
=A9.export@q() |
|
|
12 |
<xml><row><DEPTID>1</DEPTID><DEPTNAME>sale</DEPTNAME> <FATHER>12</FATHER></row><row><DEPTID>10</DEPTID> <DEPTNAME>create</DEPTNAME><FATHER>12</FATHER></row></xml> |
|
|
13 |
=xml(A12) |
Return a sequence of table sequences:
Expand members of the sequence as follows:
Then expand sub-members of the sequence as follows:
|
|
14 |
=A13.export() |
Return JSON strings.
|
|
15 |
=file("D://t4.txt").import@coq() |
Below is content of t4.txt:
A15’s result:
|
|
16 |
=A15.export@coq() |
With @o option, two double quotation marks are treated as one.
|



Related function:
f.export(A/cs,x:F,…;s)
Description:
Write data of a sequence/cursor to a file.
Syntax:
f.export(A/cs, x:F,…;s)
Note:
The function computes expression x on sequence/cursor A/cs and writes the data to file f in the form of text.
Write all fields to the file when parameter x is absent; if values of a to-be-exported field are referenced records, just write their primary key values to f. F is the field name of x in the result set.
When file f does not exist, automatically create the file (cannot automatically create the path directory). The created file is of text format by default.
When A is a sequence and parameter x is absent, write data to file f in the form of single-column text without field name.
By default, write data as JSON strings when members of each member of A are sequences/records/table sequences.
If A contains a serial byte field, write the serial byte values as hexadecimal strings; use the original data type with the binary export. The unexportable fields (such as images) in A can’t be written into file f.
Format of the txt file: separate records by carriage return; separate fields by the custom delimiter, which is tab by default.
Parameter:
|
f |
A file |
|
A/cs |
The sequence/cursor to be exported; use separators to export when members are sequences |
|
x |
The field to be exported; if omitted, all the fields of A that can be textualized will be exported; the sign # is used to represent a field with a sequence number |
|
F |
Result field name; if omitted, then use x |
|
s |
The user-defined separator used in the text file, and the default separator is tab |
Option:
|
@t |
Export field description, or the headers, as the first row of the file |
|
@a |
Append. The appended records and the original records should be of the same structure, otherwise error will be reported. Ignore @t option if there is data in the original file; overwrite the original file by default |
|
@b |
Convert into binary file to speed up the processing and ignore @t options; won’t segment A if it is small enough, otherwise it will be segmented when being converted into the binary format; With the option, parameter s represents a field or field expression of sequence A; when parameter s is present, A is regarded as ordered by s and create a segment only when s is changed; s should be different for the newly-added data at append |
|
@c |
Use comma as the separator when parameter s is absent |
|
@w |
Use Windows-style \r\n line break; by default, the line break is specified by the operating system; export a sequence of sequences as structured data where the first row is field names when @b option is also present |
|
@q |
Enclose the exported text field values and headers with quotation marks |
|
@o |
Perform escaping according to the Excel rule, which identifies two double quotation marks as one and does not escape the other characters |
Example:
Write a table sequence to txt file:
|
|
A |
|
|
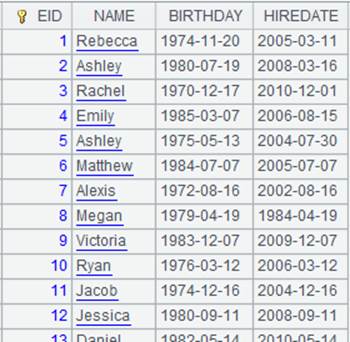
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
=file("Dep.txt").export(A1;"|") |
Write all fields in table sequence A1 to file, use | as the separator, and generate a file as follows:
|

Use @t option to write the first row as the title:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
=file("Dep.txt").export@t(A1)
|
Generate a file as follows:
|

Use @a option to append data to file:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
=file("Dep.txt").export@a(A1) |
Append A1’s content to its end.
|
Export specified fields:
|
|
A |
|
|
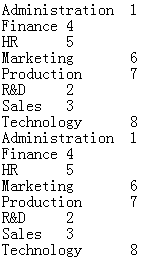
1 |
=demo.cursor("select EID,NAME,BIRTHDAY,SALARY from EMPLOYEE") |
|
|
2 |
=file("emp.txt").export@t(A1,NAME,age(BIRTHDAY):Age) |
Export cursor A1’s NAME field and BIRTHDAY field; set Age as the result field name for computing BIRTHDAY field expression.
|
|
3 |
=file("emp2.txt").export@t(A1,#1,#2) |
Use #1 and #2 to represent the first and the second fields in A1.
|

Use @b option to write data to bin file:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
=file("Dep.btx").export@b(A1) |
The bin file to which data is written has column titles by default.
|
Use @b option to export as a segmented bin file:
|
|
A |
|
|
1 |
=10000.new(~:id,rand(10):xb).sort(xb) |
Generate a table sequence ordered by xb field. |
|
2 |
=file("stest.btx").export@b(A1;xb) |
Write data as a bin file segmented by xb field, during which a new segment is created when xb field value is changed. |
Write data of a sequence and parameter x is absent:
|
|
A |
|
|
1 |
[a,s,d,f] |
|
|
2 |
=file("myfile.txt").export(A1) |
Generate a single-column file without the field name.
|
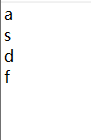
When values of the to-be-exported field in the table sequence are referenced records:
|
|
A |
|
|
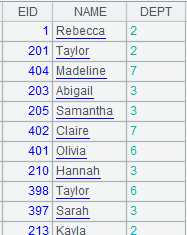
1 |
=demo.query("select EID,NAME,DEPT from EMPLOYEE order by GENDER") |
|
|
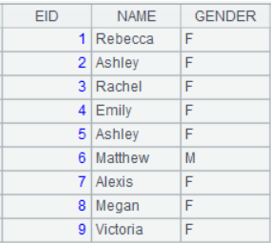
2 |
=demo.query("select DEPT,MANAGER from DEPARTMENT").keys(MANAGER) |
|
|
3 |
=A1.switch(DEPT,A2:DEPT) |
DEPT values are referenced records.
|
|
4 |
=file("empswtich.txt").export@t(A3) |
The exported file is as follows:
|
Write data as JSON string:
|
|
A |
|
|
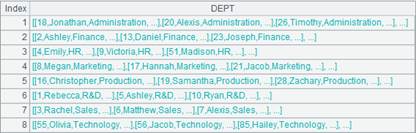
1 |
=demo.query("select EID,NAME,DEPT,SALARY from EMPLOYEE") |
|
|
2 |
=A1.group(DEPT).new(~:DEPT) |
Return a sequence whose members are records:
|
|
3 |
=file("empj.txt").export(A2) |
Export the file as JSON strings:
|
Use @q option to generate a text file where both field values and column headers are quoted:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
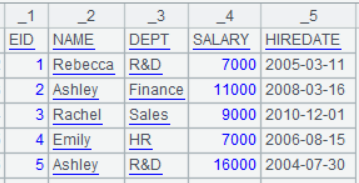
=file("Dep.txt").export@qt(A1,#1) |
|
Use @o option to treat two continuous quotation marks as one:
|
|
A |
|
|
1 |
f1,f2,f3 2,"dd""ff",3 |
|
|
2 |
=A1.import@coq() |
|
|
|
=file("o.txt").export@coq(A2) |
As @o option is present, treat the two quotation marks in the string as one and the exported t5.txt is as follows:
|


Related function: