cursor()
Here’s how to use cursor() function.
cursor()
Description:
Call a cellset file and return the result set returned from the execution of the file as a cursor.
Syntax:
cursor(spl,…)
Note:
The function calls a cellset file and returns the result set returned from the execution of the file as a cursor. When there are multiple return statements in the spl file, first merge the result sets returned by the return statements, and then return the merge result as a cursor. These result sets of return must be of the same structure, or error will be reported. Use either an absolute path or a relative path to search for the spl file. With the relative path, the search order is Class path –> Search path –> Main directory. The cursor the function returns is irreversible.
Parameter:
|
spl |
Cellset file name |
|
… |
spl’s parameter |
Option:
|
@c |
The spl can be represented by a cell that corresponds to a subroutine defined by func() function |
Return value:
Cursor
Example:
Here’s test.splx cellset file under the main directory in which arg1 is the cellset parameter:
|
|
A |
B |
|
|
1 |
for arg1 |
|
|
|
2 |
|
=connect("demo").query("select * from GYMNASTICSWOMEN where ID=?",A1) |
|
|
3 |
|
=B2.derive(avg(VAULT,UNEVENBARS,BALANCEBEAM,FLOOR):Average) |
|
|
4 |
|
return B3 |
Perform a loop computation and return the result sets. |
|
|
A |
|
|
1 |
=[5,10,20,25] |
|
|
2 |
=cursor("test.splx",A1) |
Cll test.spl, pass A1’s sequence as the value of parameter arg1, and return result as a cursor. |
|
3 |
=A2.fetch() |
Fetch records from the cursor; the result is the union of returned result sets by the loop computation of test.splx. |
|
4 |
=call("test.splx",A1) |
Use call function to call test.splx but only the result set of the first loop is returned. |

|
|
A |
B |
|
|
1 |
func |
|
|
|
2 |
|
return A1.sum() |
|
|
3 |
=cursor@c(A1,[2,5,7]) |
|
Call the code block whose master cell is A1. |
|
4 |
=A3.fetch() |
|
14. |
cursor cs cursor … cursor
Description:
Define a channel for each cursor according to a specified cursor.
Syntax:
cursor cs
cursor
…
cursor
Note:
The statement defines a channel for each cursor according to cursor cs (the value of the cursor cell is a channel), traverses cs to perform a calculation over the channel in the code block and write the result into the cell of cursor.
Parameter:
|
cs |
A cursor |
|
… |
A code block |
Return value:
Result set of channel
Example:
|
|
A |
B |
|
|
1 |
=to(100000).new(rand(1000):f1,rand(1000):f2).cursor() |
|
Generate a cursor. |
|
2 |
cursor A1 |
=A2.groups(f1:count(1)) |
Traverse cursor A1, calculate A2’s channel in B2’s code block and write the result to A2. |
|
3 |
cursor |
=A3.groups(f2:count(1)) |
Same as the above. |
A.cursor()
Description:
Generate a cursor from a sequence.
Syntax:
A.cursor(k:n)
Note:
The function generates a cursor based on sequence A, divides the cursor data into n segments, and retrieves the kth segment.
Parameter:
|
A |
A sequence |
|
k |
Segment number |
|
n |
The number of data segments; retrieve all data out when both k and n are omitted |
Option:
|
@p |
Assume data is ordered by the first field and the division won’t put records having same first field to different segments |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
=demo.query("select * from SCORES") |
Return a sequence. |
|
2 |
=A1.cursor(1:3) |
Generate a cursor using A1’s sequence, divide the cursor into three segments, and retrieve the 1st segment to return. |
|
3 |
=A1.cursor() |
Generate a cursor using A1’s sequence; return all data of the cursor when parameters are absent. |
|
4 |
=demo.query("select CLASS,STUDENTID,SUBJECT,SCORE from SCORES").sort(CLASS) |
Return a sequence ordered by the 1st field. |
|
5 |
=A4.cursor@p(1:3) |
With @p option, put records having same Class value in one segment, during which records are not allocated strictly according to parameters k and n. |
A.cursor@m(n)
Description:
Generate a multicursor from a sequence.
Syntax:
A.cursor@m(n)
Note:
The function generates a multicursor using sequence A.
Parameter:
|
A |
A sequence |
|
n |
Number of subcursors; by default the value is【Default subcursor count in a multicursor】configured in the designer; when integrating esProc in a third-party application, its default value is cursorParallelNum value configured in raqsoftConfig.xml file |
Option:
|
@p |
Assume the sequence is ordered by the 1st field and records having same 1st field value won’t be put into two segments |
Return value:
Multicursor
Example:
|
|
A |
|
|
1 |
=demo.query("select CLASS,STUDENTID,SUBJECT,SCORE from SCORES") |
Return a sequence. |
|
2 |
=A1.cursor@m() |
Generate a multicursor from A1’s sequence; as parameters are absent, use value of【Default subcursor count in a multicursor】as the default number of subcursors. |
|
3 |
=demo.query("select CLASS,STUDENTID,SUBJECT,SCORE from SCORES").sort(CLASS) |
Return a sequence ordered by the 1st field. |
|
4 |
=A1.cursor@mp(3) |
Generate a multicursor having three subcursors; with @p option, the segmentation won’t put records having same CLASS value in two segments. |
A.cursor@m(mcs,K:K’,...)
Description:
Generate a multicursor segmented synchronously as an existing multicursor using a specified sequence.
Syntax:
A.cursor@m(mcs,K:K‘,...)
Note:
The function divides ordered sequence A into multiple segments according to multicursor mcs and returns a multicursor. Parameters K and K’ are segmentation keys of A and mcs respectively.
Parameter:
|
A |
An ordered sequence |
|
mcs |
A multicursor |
|
K |
A’s segmentation key |
|
K’ |
mcs’s segmentation key |
Option:
|
@p |
Ignore parameters K and K’ and divide ordered sequence A by comparing and matching the first fields of mcs and A |
Return value:
Multicursor
Example:
|
|
A |
|
|
1 |
=to(10000).new(#:c1,rand():c2).sort(c1) |
Generate a sequence. |
|
2 |
=A1.cursor@m(3) |
Generate a multicursor having three subcursors from A1’s table sequence. |
|
3 |
=to(10000).new(#:k1,rand(10000):k2,rand()*1000:k3).sort(k1) |
Generate a table sequence ordered by k1. |
|
4 |
=A3.cursor@m(A2,k1:c1) |
Generate a multicursor segmented synchronously as A2’s multicursor, whose segmentation key is c1, based on A3’s table sequence, whose segmentation key is k1. |
|
5 |
=A3.cursor@mp(A2) |
Generate a multicursor segmented synchronously as A2’s multicursorbased on A3’s table sequence; as @p option is present, perform the segmentation by comparing and matching the first fields of A3 and A2, and in this case segmentation key parameters are not needed in the expression. |
CS.cursor()
Description:
Generate a multicursor using a sequence of cursors.
CS.cursor()
Note:
The function generates a multicursor using the sequence of cursors CS, where members must have the same structure. When members of CS are multicursors, a multilayer multicursor will be generated.
Parameter:
|
CS |
A sequence of cursors. |
Return value:
Multicursor
Example:
test_mcs.splx is the deployment file for deploying remote node servers. The nodes are 【"192.168.0.204"," 192.168.0.205","192.168.0.206"】and port number is 8081. Below is content of the deployment file:
|
|
A |
|
1 |
=connect("demo").cursor("select * from SCORES where SUBJECT=?",arg1) |
|
2 |
return A1 |
|
|
A |
|
|
1 |
=callx("test_mcs.splx",["English","Math","PE"];["192.168.0.204:8081" ,"192.168.0.205:8081","192.168.0.206:8081"]) |
The three parallel node servers return three cursors to form a sequence. |
|
2 |
=A1.cursor() |
Generate a multicursor using A1’s sequence of cursors. |
|
3 |
=A2.fetch() |
Fetch all records from A2’s multicursor. |

cs.cursor@m()
Description:
Generate a multicursor using a unicursor.
Syntax:
cs.cursor@m(n)
Note:
The function generates a multicursor using a unicursor cs. It fetches data from cs and parallelly allocates them to n subcursors.
Parameter:
|
cs |
A unicursor. |
|
n |
The number of subcursors, whose default value is 【Default Number of Subcursors in a Multicursor】configured in the designer. When esProc is integrated into a third-party application, the default number of subcursors is cursorParallelNum value set up in raqsoftConfig.xml. When n =0, the function generates a buffer cursor, to which retrieval threads buffer data to it. This often happens when cursor data is being appended to a composite table. |
Return value:
Unicursor/Multicursor/Buffer cursor
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from EMPLOYEE") |
|
|
2 |
=A1.cursor@m(3) |
Generate a multicursor. |
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,GENDER,DEPT, SALARY from employee") |
|
|
2 |
=A1.cursor@m(0) |
Generate a buffer cursor. |
|
3 |
=file("emp.ctx").open() |
Open a composite table file. |
|
4 |
=A3.append(A2) |
Append data of cursor A2 to emp.ctx, during which the retrieval threads buffers data when cursor data is outputting. |
db.cursor()
Description:
Create a database cursor by executing an SQL statement.
Syntax:
db. cursor(sql {,args …})
Note:
The function creates a database cursor by executing SQL. The cursor will be automatically closed after a full data scan.
Parameter:
|
db |
Database connection |
|
sql |
A SQL query statement |
|
args |
Parameters passed to SQL, which can be values or names defined; separate multiple parameters with comma
|
Option:
|
@i |
If the result set has only one column, the content of the returned cursor is a sequence |
|
@d |
Convert the numeric data type to the double data type, instead of the decimal data type |
|
@x |
Disconnect from the database automatically when the cursor is closed; this option applies to connect -mode database connection only; with this option, the cursor the function returns is irreversible |
|
@v |
Generate a cursor of pure table sequence or pure sequence |
Return value:
A cursor
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES") |
Parameter db is data source name; this requires that demo data source is already connected. |
|
2 |
=connect("demo") |
|
|
3 |
=A2.cursor@x("select * from SCORES").fetch() |
With connect-mode database connection, @x is used. |
|
4 |
=A2.cursor("select * from STUDENTS") |
Error is reported: Data Source demo is shutdown or wrong setup., which prompts you that data source isn’t started as database is automatically disconnected when A3’s cursor is closed. |
When the SQL query statement contains parameters:
|
|
A |
|
|
1 |
>arg2="R&D" |
Define parameter name as arg2 and parameter value as "R&D". |
|
2 |
=demo.cursor("select EID,NAME,DEPT,GENDER from employee where EID<? and DEPT=? and GENDER=?",arg1,arg2,"M") |
Query employee table, where arg1 is a cellset parameter whose value is 100 and arg2 is a parameter defined in A1, and the 3rd parameter receives value “M” directly. |
|
3 |
=A2.fetch() |
Fetch data from A2’s cursor.
|
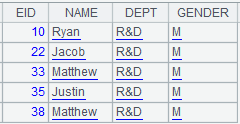
Return cursor containing other types of data:
|
|
A |
|
|
1 |
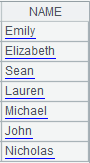
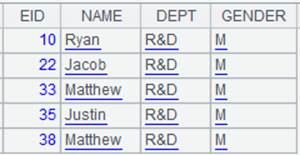
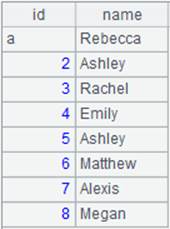
=demo.cursor("select NAME from STUDENTS") |
Query NAME field of STUDENTS table from demo data source and return a cursor whose content is as follows:
|
|
2 |
=demo.cursor@i("select NAME from STUDENTS") |
When the result set contains only one column, use @i option to return content of the cursor as a sequence.
|
|
3 |
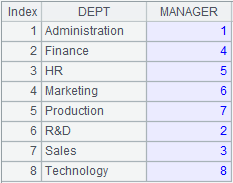
=demo.cursor@v("select * from STUDENTS") |
Return a cursor of pure table sequence. |
|
4 |
=demo.cursor@iv("select NAME from STUDENTS") |
Return a cursor of pure sequence. |
|
5 |
=mysql.cursor@d("select * from ta") |
As @d option is present, numeric data is converted to double type.
|
Related function:
f.cursor()
Description:
Create a cursor based on a file.
Syntax:
f.cursor()
f.cursor(Fi:type,…; k:n,s)
Note:
The function creates a cursor based on file f and returns it. The cursor will be automatically closed after a full data scan.
Parameter:
|
f |
File object, only supporting the textual file object |
|
Fi |
Fields to be retrieved; all fields will be retrieved by default. The to-be-retrieved field(s) can be represented by their sequence numbers headed by the sign # |
|
type |
Field types, including bool, int, long, float, decimal, string, date, time and datetime. Data type of the first row will be used by default |
|
s |
User-defined separator. The default is tab. When the parameter is omitted, the comma preceding it can be omitted, too |
|
k |
The segment number |
|
n |
The number of segments. Retrieve the whole file when both k and n are omitted |
Option:
|
@t |
Use the first row of f as the field names. If omitted, use_1,_2,… as the default field names |
|
@b |
Retrieve data from a binary file written in the method of export, with the support of parameters Fi, k and n, and without support of parameters type and s. Ignore options @t, @s, @i, @q, @a, @n, @k, @p, @f, @l, @m, @c, @o, @d, @v and @r. The segmental retrieval could result in empty segment in cases when a file has only a very small number of records |
|
@e |
Make the function return null when Fi doesn’t exist in the file; raise an error when the option is absent |
|
@x |
Delete the source file automatically on closing the cursor; the cursor that the function returns is irreversible when this option works |
|
@s |
Not split the to-be-retrieved field when it is imported as a cursor whose content is a table sequence consisting of strings of a single field; in this case the parameters will be ignored. |
|
@i |
If the result set has only one column, the content of the returned cursor will be a sequence. |
|
@q |
Remove the quotation marks, if any, from both ends of data items, including the field names, and handle escape sequences; but will keep quotation marks within the data item |
|
@c |
Use comma as the separator when parameter s is absent |
|
@m |
With the option, the f.cursor@m(Fi:type,…;n,s) function returns a multicursor; here parameter n is the number of segments; use the value of 【Default subcursor count in a multicursor】defined in the designer as the number subcursors if the option is absent; when integrating esProc into a third-party application, use cursorParallelNum value configured in raqsoftConfig.xml file as the default |
|
@o |
Use quotation marks as the escape character |
|
@k |
Retain white spaces on both sides of the data item; without it white spaces on both ends will be automatically deleted |
|
@d |
Delete a record if it contains unmatching data types or data formats and start examining data by type, or if the parentheses and the quotation marks in it do not match when @p option and @q option respectively are present |
|
@n |
Ignore and discard rows whose number of columns don’t match the first row |
|
@v
|
Throw an exception, terminate the execution and output the content of the problem record when errors appear in @d check and @n check |
|
@w |
Read each row, including the column headers row, as a sequence and return a cursor of sequence made up of sequences |
|
@a |
Treat single quotes as what they are; left not handled by default , and can work with @q@p |
|
@p |
Enable handling the matching of parentheses (not including the separators within the parentheses) and quotes, as well as the escape sequences outside of the quotes |
|
@f |
Split the file content into a string by the separator without parsing |
|
@l |
Allow line continuation if there is an escape character \ at the end of the line |
Return value:
Cursor/Multicursor
Example:
|
|
A |
B |
C |
|
|
|
1 |
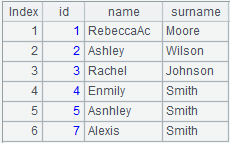
=file("D://Student.txt").cursor@tx() |
|
|
Return the cursor for retrieving data, take the record in the first row as field names, and delete the file automatically when closing the cursor. |
|
|
2 |
=create(CLASS,STUDENTID,SUBJECT,SCORE) |
|
|
Construct a new table sequence. |
|
|
3 |
for |
|
|
|
|
|
4 |
|
if A3==1 |
=A1.skip(5) |
If the loop number is 1, then skip 5 consecutive rows. |
|
|
5 |
|
=A1.fetch(3) |
|
Retrieve data from cursorA1, 3 rows each time. |
|
|
6 |
|
if B5==null |
|
Jump out from the loop when B5 is null. |
|
|
7 |
|
|
Break |
|
|
|
8 |
|
else |
|
|
|
|
9 |
|
|
>A2.insert(0:B5,CLASS,STUDENTID,SUBJECT,SCORE) |
Insert records in B5 into A2. |
|
|
10 |
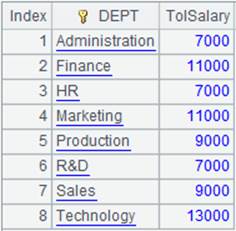
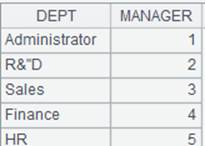
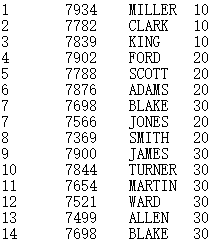
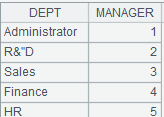
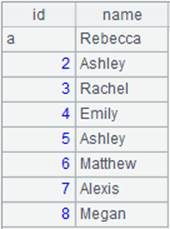
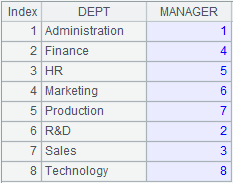
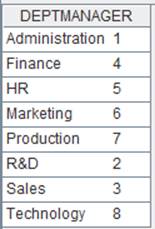
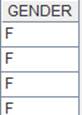
=file("D://Department.txt").cursor@t(Dept,Manager;,"/") |
|
=A10.fetch() |
Below is Department.txt:
Contents of Department. txt are separated with the slashes and read out according to the specified fields of DEPT and MANAGER.
|
|
|
11 |
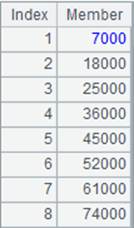
=file("D://Department5.txt").cursor@t(;1:2) |
|
=A11.fetch() |
With Fi and s omitted, the function separates the cursor into 2 segments and retrieves the first one. |
|
|
12 |
=file("D:// EMPLOYEE. btx").cursor@b(GENDER;1:2) |
|
=A12.fetch() |
Retrieve the GENDER field of the bin file, EMPLOYEE.btx(a segmented binary file) exported through f.export@z(); by default the exported binary file includes field names. |
|
|
13 |
=file("D://EMPLOYEE.btx").cursor@b(;1:2) |
|
=A13.fetch() |
Retrieve the segmented binary file, EMPLOYEE1.btx, exported by f.export@b(), divide the file contents into 2 parts, and get the first part. |
|
|
14 |
=file("D://Department.txt").cursor@ts() |
|
= A14.fetch() |
Won’t split fields, the cursor contains a table sequence consisting of a single string field. |
|
|
15 |
=file("D://StuName.txt").cursor@i() |
|
=A15.fetch() |
StuName.txt is a file containing only one field, so the content of the cursor is a sequence. |
|
|
16 |
=file("D://EMPLOYEE1.txt").cursor@tc() |
|
=A16.fetch() |
|
|
|
17 |
=file("D://Department3.txt").cursor@e(EID) |
|
=A17.fetch() |
Return null since EID field can’t be found in Department3.txt; without @e option, error will be reported, saying EID: field is not found. |
|
|
18 |
=file("D://Department2.txt").cursor@tq(;,"|") |
|
=A18.fetch() |
Below is Department2.txt:
B19’s result:
|
|
|
19 |
=file("D://Department.txt").cursor@tm(DEPT:string,MANAGER:int;3,"/") |
|
|
The cursor is devided into 3 segments and the result of A19 is returned as a multicursor. |
|
|
20 |
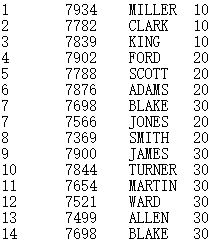
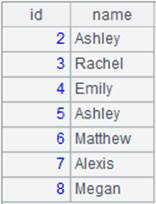
=file("D://Sale1.txt").cursor(#1,#3) |
|
=A20.fetch() |
Below is the Sale1.txt file:
Below is the result of B20:
|
|
|
21 |
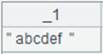
=file("D:/Dep3.txt").cursor@cqo() |
|
=A21.fetch() |
With @o option, two double quotation marks are treated as one and return the result as follows:
|
|
|
22 |
=file("D:/Dep1.txt").cursor@k() |
|
=A22.fetch() |
Retain the whitespace characters on both sides of the data item.
|
|
|
23 |
=file("D:/Department1.txt").cursor@t(id:int,name;,"|") |
|
=A23.fetch() |
Return id and name fields of Department1.txt.
|
|
|
24 |
=file("D:/Department1.txt").cursor@td(id:int,name;,"|") |
|
=A24.fetch() |
Delete a record containing unmatching data types; rows where id value is a are deleted. |
|
|
25 |
=file("D:/Department1.txt").cursor@tv(id:int,name;,"|") |
|
=A25.fetch() |
Verify data type matching, and, and if error reports, throw an exception, terminate the execution and output the content of the problem record; data type doesn’t match with rows where id value is a.
|
|
|
26 |
=file("D:/Dep2.txt").cursor@tdn(id:int,name,surname;,"|") |
|
=A26.fetch() |
Here’s the file Dep2.txt: Ignore row 6 and row 8 because the number of columns doesn’t match that in row 1.
|
|
|
27 |
=file("D:/Desktop/DemoData/txt/City.txt").cursor@w() |
|
=A27.fetch() |
Use @w option to read each row as a sequence and return a cursor of sequence whose members are sequences.
|
|
|
28 |
=file("D://t1.txt").cursor@c() |
|
=A28.fetch() |
Below is t1.txt:
With @c option, use the comma as the default separator and return result as follows:
|
|
|
29 |
=file("D://t1.txt").cursor@cp() |
|
=A29.fetch() |
With @p option, parentheses and quotation marks matching will be handled during parsing.
|
|
|
30 |
=file("D://t1.txt").cursor@cpa() |
|
=A30.fetch() |
With @a option, single quotes are treated as quotes.
|
|
|
31 |
=file("D://t2.txt").cursor@l() |
|
=A31.fetch() |
Below is t2.txt:
With @1 option, allow line continuation when there is an escape character at the end of the line.
|
|
|
32 |
=file("D://t3.txt").cursor@f() |
|
=A32.fetch() |
With @f option, just splt the file as a string using the separator.
|
|






Related functions:
T.cursor(x:C,…;wi…;k:n)
Description:
Segment an entity table or an in-memory table or a multizone composite table and return the cursor of a specified segment.
Syntax:
T.cursor(x:C,…;wi,…;k:n)
Note:
The function computes expression x over data in entity table/in-memory table/multizone composite table T, filters the result table according to filtering expression wi, splits it into n segment and returns the kth segment as a cursor, where C is the field name. If T is an attached table, the queried data is allowed to include a primary table field.
Segment all zone tables synchronously and merge the result when T is a multizone composite table.
Option:
|
@m |
The T.cursor@m(x:C…;wi,...;n) function with this option generates a multicursor segmented into n parts. n is an integer; the function returns an ordinary cursor if n<2; use the value of【Default number of subcursors in a multicursor】 set in【Tool】-【Options】if n is absent. |
|
@v |
Generate a pure table sequence-based columnwise cursor, which has higher performance than regular cursors. |
|
@x |
Automatically close the entity table/in-memory table after data in the cursor is fetched. |
|
@g |
When T is a multizone composite table and if group() operation will be executed on the result cursor, use this option to speed up the computation. |
|
@w |
Used on a multizone composite table with update mark; Perform update merge; when zone tables share a same key value, ignore the record contained in the zone table with a smaller number; segmentation is performed according to the way zone table 1 is split; Handle the update mark and do not return records with a deletion mark to the cursor; but if the key value of a record with the deletion mark is unique in the multizone composite table, just retain it; This option enables retrieving key field(s) as well as the deletion mark field, if there is one, forcefully. |
|
@z |
Get data in the inverse order; do not support segmentation in this case. |
|
@p |
Perform MERGE by the first field when parameter T is a multizone composite table. |
Parameter:
|
T |
An entity table or an in-memory table or a multizone composite table |
|
x |
Expression; by default, all fields of T will be returned to the cursor |
|
C |
Column alias; can be omitted |
|
wi |
Filtering condition; separate multiple conditions by comma(s) and their relationships are AND; besides regular filtering expressions, you can also use the following five types of syntax in a filtering condition, where K is a field in the entity table: 1.K=w w usually uses expression Ti.find(K) or Ti.pfind(K), where Ti is a table sequence. When value of w is null or false, the corresponding record in the entity table will be filtered away; when w is expression Ti.find(K) and the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K; when w is expression Ti.pfind(K) and the to-be-selected fields C,... contain K, sequence numbers of K values in Ti will be assigned to K. 2.(K1=w1,…Ki=wi,w) Ki=wi is an assignment expression. Generally, parameter wi can use expression Ti.find(Ki) or Ti.pfind(K), where Ti is a table sequence; when wi is expression Ti.find(K) and the to-be-selected fields C,... contain Ki, Ti’s referencing field will be assigned to Ki correspondingly; when wi is expression Ti.pfind(Ki) and the to-be-selected fields C,... contain Ki, sequence numbers of Ki values in Ti will be assigned to Ki. w is a filter expression; you can reference Ki in w. 3.K:Ti Ti is a table sequence. Compare Ki value in the entity table with key values of Ti and discard records whose Ki value does not match; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K. 4.K:Ti:null Filter away all records that satisfy K:Ti. 5.K:Ti:# Locate records according to sequence numbers, compare sequence numbers of records in table sequence Ti according to the entity table’s K values, and discard non-matching records; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K |
|
k |
A positive integer (k≤n) representing the kth segment |
|
n |
A positive integer representing the number of segments; return all records when parameters k:n are absent |
Return value:
Unicursor/Multicursor
Example:
|
|
A |
|
|
1 |
for 100 |
|
|
2 |
=to(10000).new(#:k1,rand():c1).sort@o(k1) |
Return a table sequence:
|
|
3 |
=to(10000).new(#:k1,rand(10000):c2,rand()*1000:c3).sort@o(k1) |
Return a table sequence:
|
|
4 |
=A2.cursor() |
Return a cursor. |
|
5 |
=A3.cursor() |
Return a cursor. |
|
6 |
=file("D:\\tb4.ctx") |
Generate a composite table file. |
|
7 |
=A6.create(#k1,c1) |
Create A6’s base table whose key is k1. |
|
8 |
=A7.append(A4) |
Append data of A4’s cursor to A7’s base table. |
|
9 |
=A7.attach(table4,c2,c3) |
Create an attached table table4 for the base table. |
|
10 |
=A9.append(A5) |
Append data of A5’s cursor to attached table table4. |
|
11 |
=A9.cursor(;c2<1000;2:3) |
Divide records meeting c2<1000 in the attached table into 3 segments and return a cursor of all columns of the second segment. |
|
12 |
=A11.fetch() |
Fetch data from A11’s cursor.
|
|
13 |
=A7.cursor(;c1>0.99) |
Get records meeting c1>0.99 from A7’s base table |
|
14 |
=A13.fetch() |
Fetch data from A13’s cursor.
|
|
15 |
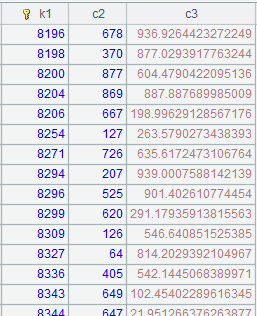
=A9.cursor(k1,c1:b,c3;c3>999) |
Get the base table’s k1 field and c1 field from attached table table4, as well as c3 field of the attached table, according to condition c3>999, and rename c1 b. |
|
16 |
=A15.fetch() |
Fetch data from A15’s cursor.
|
|
17 |
=A9.cursor@m(;;3) |
Use @m option to generate a multicursor from attached table table4. |
 b
b
|
|
A |
|
|
1 |
=file("employee1.ctx") |
Generate composite table file employee1.ctx. |
|
2 |
=A1.create@y(#EID,NAME,GENDER,SALARY) |
Create the base table of composite table employee1.ctx, which contains columns EID, NAME, GENDER and SALARY and where EID is the dimension. |
|
3 |
=connect("demo").cursor("select EID,NAME,GENDER,SALARY from employee") |
Return a cursor. |
|
4 |
=A2.append@i(A3) |
Append records of A3’s cursor to A2’s base table. |
|
5 |
=A2.cursor@v(;SALARY>1000;) |
Return a column-wise cursor, and automatically close A2’s composite table after data is fetched from it.
|
|
6 |
=A5.groups(GENDER;avg(SALARY):SALARY_AVG) |
Perform grouping & aggregation operation on A5’s cursor.
|
|
7 |
=A2.cursor(;SALARY>2000) |
Error is reported, prompting“Stream Closed” . |

When T is a multizone composite table:
|
|
A |
|
|
1 |
=100000.new(~:ID,rand(2):FM).cursor() |
|
|
2 |
=file("nc.ctx":[1,2]) |
Generate a homo-names files group. |
|
3 |
=A2.create@y(#ID,FM;if(FM==1,1,2)) |
Return a multizone composite table. |
|
4 |
=A3.append@x(A1) |
Append cursor A1’s data to the multizone composite table; below is content of the multizone composite table: 1.nc.ctx 2.nc.ctx
|
|
5 |
=A3.cursor(;;1:3) |
Split the multizone composite table into three segments, return the first segment of each zone table, merge them and return result as a cursor:
Data in zone table 1 and that in zone table 2 has been merged by their dimensions. |


Use special types of filtering conditions:
|
|
A |
|
|
1 |
=file("emp.ctx") |
|
|
2 |
=A1.open() |
Open the composite table file. |
|
3 |
=A2.import() |
As no parameters are present, return all data in the entity table.
|
|
4 |
=5.new(~:ID,~*~:Num).keys(ID) |
Generate a table sequence using ID as the key.
|
|
5 |
=A2.cursor(EID,NAME;EID=A4.find(EID)) |
Use K=w filtering mode; in this case w is Ti.find(K) and entity table records making EID=A4.find(EID) get null or false are discarded; EID is the selected field, to which table sequence A4’s referencing field are assigned.
|
|
6 |
=A2.cursor(EID,NAME;EID=A4.pfind(EID)) |
Use K=w filtering mode; in this case w is Ti.pfind(K) and entity table records making EID=A4.pfind(EID) get null or false are discarded; EID is the selected field, to which its sequence numbers in table sequence A4 is assigned.
|
|
7 |
=A2.cursor(EID,NAME;EID:A4) |
Use K:Ti filtering mode; compare the entity table’s EID values with the table sequence’s key values and discard entity table records that cannot match.
|
|
8 |
=A2.cursor(NAME,SALARY;EID:A4) |
This is a case where K isn’t selected; EID isn’t the selected field, so only filtering is performed.
|
|
9 |
=A2.cursor(EID,NAME;EID:A4:null) |
Use K:Ti:null filtering mode; compare the entity table’s EID values with the table sequence’s key values and discard entity table records that can match.
|
|
10 |
=A2.cursor(EID,NAME;EID:A4:#) |
Use K:Ti:# filtering mode; compare with sequence numbers of table sequence’s records according to the entity table’s EID values, and discard records that cannot match.
|
|
11 |
=connect("demo").query("select top 2 NAME,GENDER from employee").keys(NAME) |
Return a table sequence using NAME as the key.
|
|
12 |
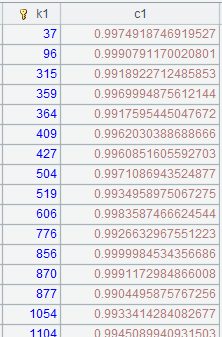
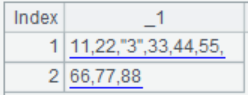
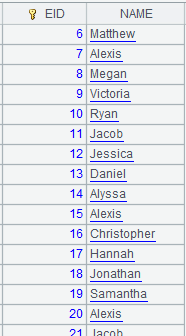
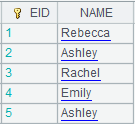
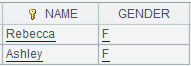
=A2.cursor(EID,NAME;(EID=A4.find(EID),NAME=A11.find(NAME),EID!=null&&NAME!=null)) |
Use
(K1=w1,…Ki=wi,w) filtring mode; return records that
meet all conditions |
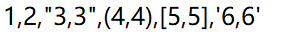

Use @z option to get data in the inverse order:
|
|
A |
|
|
1 |
=100000.new(~:ID,rand(2):FM) |
|
|
2 |
=file("curz.ctx") |
|
|
3 |
=A2.create@y(#ID,FM) |
Create a composite table. |
|
4 |
=A3.append@i(A1) |
|
|
5 |
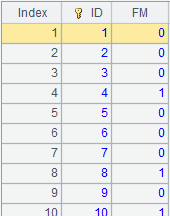
=A4.cursor().fetch() |
Return the composite table as a cursor and fetch data from the cursor:
|
|
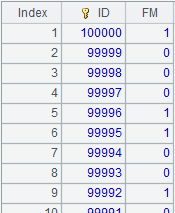
6 |
=A4.cursor@z().fetch() |
Use @z option to get data in the inverse order and fetch data from the cursor as follows:
|
Use @w option to recognize update mark:
|
|
A |
|
|
1 |
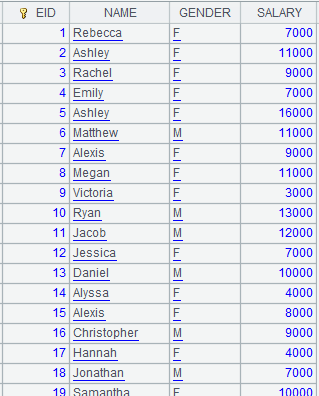
=connect("demo").cursor("select EID,NAME,GENDER from employee") |
|
|
2 |
=A1.derive(:Defiled) |
|
|
3 |
=A2.new(EID,Defiled,NAME,GENDER) |
Return a cursor whose content is as follows:
|
|
4 |
=file("ecd.ctx":[1,2]) |
Define a homo-name files group: 1.ecd.ctx and 2.ecd.ctx. |
|
5 |
=A4.create@yd(#EID,Defiled,NAME,GENDER;if(GENDER=="F",1,2)) |
Create a multizone composite table, set EID as the key, use @d option to make Defiled field the update mark and put records where GENDER is F to 1.ed.ctx and the other records to 2.ed.ctx. |
|
6 |
=A5.append@ix(A3) |
Append cursor A3’s data to the multizone composite table. |
|
7 |
=create(EID,Defiled,NAME,GENDER).record([0,true,,,1,true,,, 2,false,"BBB","F"]) |
Return a table sequence whose content is as follows:
|
|
8 |
=file("ecd.ctx":[3]) |
|
|
9 |
=A8.create@yd(#EID,Defiled,NAME,GENDER;3) |
Add zone table 3.ecd.ctx and make Defiled the update mark field. |
|
10 |
=A9.append@i(A7) |
Append table sequence A7’s records to zone table 3.ecd.ctx. |
|
11 |
=file("ecd.ctx":[1,2,3]).open() |
Open composite table file ecd.ctx. |
|
12 |
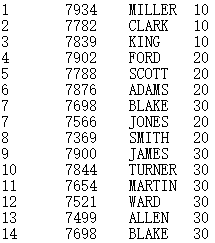
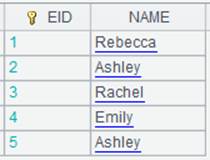
=A11.cursor().fetch() |
Return all data in the multizone composite table ecd.ctx to the cursor; below is the returned content:
|
|
13 |
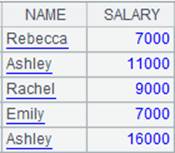
=A11.cursor@w().fetch() |
With @w option, return data in multizone composite table ecd.ctx as a cursor and recognize the update mark: Do not return the record whose EID value is 2 and where the update mark value is true (meaning to-be-deleted) to the cursor; Update the record where EID value is 2 and marked by false (meaning to-be-modified); Retain the record where EID value is 0, marked by true (meaning to-be-deleted), and whose key value is unique, and return it to the cursor; Below is content of the returned cursor:
|

T.cursor(x,…;wi,...)
Description:
Return the specified column(s) in a cluster entity table/cluster in-memory table as a cluster cursor.
Syntax:
T.cursor(x,…;wi,...)
Note:
The function computes data in a cluster entity table/cluster in-memory table with expression x and the filtering condition w and returns the results as a cluster cursor.
Option:
|
@m |
The function with this option generates a cluster multicursor synchronously segmented into n parts. n is a positive integer representing the number of segments to be divided; the function returns an ordinary cursor if n<2; use the value of【Default number of subcursors in a multicursor】set in【Tool】-【Options】if n is absent |
Parameter:
|
T |
A cluster entity table/cluster in-memory table; cannot be a duplicate table |
|
x |
An expression |
|
wi |
Filtering condition; multiple conditions are separated by comma(s) and their relationships are AND |
Return value:
A cluster (multi)cursor
Example:
|
|
A |
|
|
1 |
=file(“D:/tb4.ctx”:[1],“169.254.121.62:8281”) |
Open a cluster table file. |
|
2 |
=A1.open() |
Return a cluster composite table. |
|
3 |
=A2.attach(table3) |
Retrieve cluster entity table table3. |
|
4 |
=A2.cursor() |
Return a cluster cursor. |
|
5 |
=A3.cursor(NAME,GENDER;EID<6) |
Return NAME field and GENER field where EID<6 as a cluster cursor. |
|
6 |
=file(“tb5.ctx”:[2],“192.168.31.72:8281”) |
|
|
7 |
=A6.open() |
|
|
8 |
=A7.cursor@m(;;3) |
Generate a cluster multicursor that is segmented into 3 parts. |
|
9 |
=A7.cursor() |
|
|
10 |
=A9.memory() |
Generate a cluster in-memory table. |
|
11 |
=A10.cursor() |
Return a cluster cursor. |
T.cursor(x:C,…;wi,...;mcs)
Description:
Synchronously segment an entity table/in-memory table/multizone composite table according to a multicursor and return a multicursor.
Syntax:
T.cursor(x:C,…;wi,...;mcs)
Note:
The function synchronously segments entity table/in-memory table/multizone composite table T according to multicursor mcs, during which T’s first field and mcs’s first field will be matched, and returns a multicursor. When T is a multizone composite table, merge zone tables by their dimensions.
Parameter:
|
T |
An entity table/in-memory table/multizone composite table; should not be composite table stored in row-wise. |
|
x |
An expression. |
|
C |
The column alias. |
|
wi |
Filtering condition; retrieve the whole set when this parameter is absent; separate multiple conditions by comma(s) and their relationships are AND. Besides regular filtering expressions, you can also use the following five types of syntax in a filtering condition, where K is a field in the entity table: 1.K=w w usually uses expression Ti.find(K) or Ti.pfind(K), where Ti is a table sequence. When value of w is null or false, the corresponding record in the entity table will be filtered away; when w is expression Ti.find(K) and the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K; when w is expression Ti.pfind(K) and the to-be-selected fields C,... contain K, sequence numbers of K values in Ti will be assigned to K. 2.(K1=w1,…Ki=wi,w) Ki=wi is an assignment expression. Generally, parameter wi can use expression Ti.find(Ki) or Ti.pfind(K), where Ti is a table sequence; when wi is expression Ti.find(Ki) and the to-be-selected fields C,... contain Ki, Ti’s referencing field will be assigned to Ki correspondingly; when wi is expression Ti.pfind(Ki) and the to-be-selected fields C,... contain Ki, sequence numbers of Ki values in Ti will be assigned to Ki. w is a filter expression; you can reference Ki in w. 3.K:Ti Ti is a table sequence. Compare Ki value in the entity table with key values of Ti and discard records whose Ki value does not match; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K. 4.K:Ti:null Filter away all records that satisfy K: Ti. 5.K:Ti:# Locate records according to sequence numbers, compare sequence numbers of records in table sequence Ti according to the entity table’s K values, and discard non-matching records; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K.
|
|
mcs |
A multicursor generated from an entity table |
Option:
|
@k |
Perform matching using the multicursor’s first field of the key |
|
@v |
Generate a pure table sequence-based column-wise cursor, which has higher performance than regular cursors |
|
@x |
Automatically close the entity table after data is fetched from the cursor |
|
@g |
When T is a multizone composite table and if group() operation will be executed on the result cursor, use this option to speed up the computation. |
|
@w |
Used on a multizone composite table with the update mark; Perform update merge; when zone tables share a same key value, ignore the record contained in the zone table with a smaller number; segmentation is performed according to the way zone table 1 is split; Handle the update mark and do not return records with a deletion mark to the cursor; but if the key value of a record with the deletion mark is unique in the multizone composite table, just retain it; This option enables retrieving key field(s) as well as the deletion mark field, if there is one, forcefully |
|
@p |
Perform MERGE by the first field when parameter T is a multizone composite table. |
Return value:
Multicursor
Example:
|
|
A |
|
|
1 |
for 100 |
|
|
2 |
Return a table sequence:
|
|
|
3 |
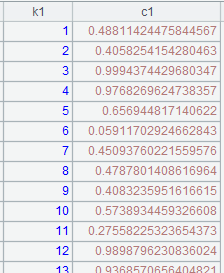
=to(10000).new(#:k1,rand(10000):c2).sort@o(k1) |
Return a table sequence:
|
|
4 |
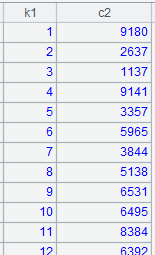
=to(10000).new(#:k1,rand()*1000:c3).sort@o(k1) |
Return a table sequence:
|
|
5 |
=A2.cursor() |
Return a cursor. |
|
6 |
=A3.cursor() |
Return a cursor. |
|
7 |
=A4.cursor() |
Return a cursor. |
|
8 |
=file("D:\\cs1.ctx") |
Generate a composite table file. |
|
9 |
=A8.create(#k1,c1) |
Create the composite table’s base table. |
|
10 |
=A9.append(A5) |
Append data in A5’s cursor to the base table. |
|
11 |
=A9.attach(table1,c2) |
Create attached table table1 on base table. |
|
12 |
=A11.append(A6) |
Append data in A6’s cursor to table1. |
|
13 |
=A11.cursor@m(;;2) |
Segment the attached table and return a multicursor. |
|
14 |
=A9.attach(table2,c3) |
Create attached table table2 on base table. |
|
15 |
=A14.append(A7) |
Append data in A7’s cursor to table2. |
|
16 |
=A14.cursor@v(;;A13) |
Segment table2 according to A13’s multicursor. |

When T is a multizone composite table:
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME from employee") |
|
|
2 |
=file("emp.ctx") |
Generate a composite table file. |
|
3 |
=A2.create@y(#EID,NAME) |
Create the composite table’s base table. |
|
4 |
=A3.append(A1) |
Append data in A1’s cursor to the composite table’s base table. |
|
5 |
=A4.cursor@m(;;3) |
Generate a multicursor having 3 subcursors according to the composite table. |
|
6 |
=connect("demo").cursor("select EID,NAME,GENDER,SALARY from employee") |
|
|
7 |
=file("emp.ctx":[1,2]) |
Generate a homo-name files group. |
|
8 |
=A7.create@y(#EID,NAME,GENDER,SALARY;if(GENDER=="F",1,2)) |
Create a multizone composite table. |
|
9 |
=A8.append@x(A6) |
Append data in A6’s cursor to the multizone composite table and its content is as follows:
|
|
10 |
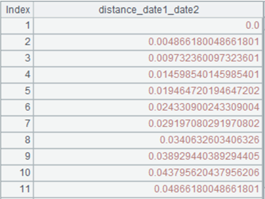
=A8.cursor(EID,NAME,GENDER,SALARY;SALARY>5000;A5) |
Split A8’s multizone composite table synchronously according to A5’s multicursor, perform merge by default and return a cursor as follows:
We can see that data in two zone tables are merged by their dimensions. |
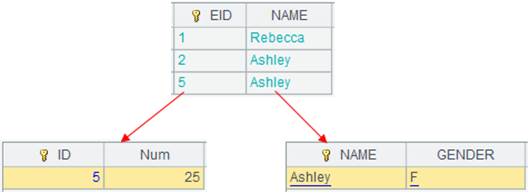
Use special types of filtering conditions:
|
|
A |
|
|
1 |
=file("emp.ctx") |
|
|
2 |
=A1.open() |
Open the composite table file. |
|
3 |
=A2.import() |
As no parameters are present, return all data in the entity table.
|
|
4 |
=file("emp1.ctx").open().cursor@m(;;2) |
Return a multicursor. |
|
5 |
=5.new(~:ID,~*~:Num).keys(ID) |
Generate a table sequence using ID as the key.
|
|
6 |
=A2.cursor(EID,NAME;EID=A5.find(EID);A4) |
Use K=w filtering mode; in this case w is Ti.find(K) and entity table records making EID=A4.find(EID) get null or false are discarded; EID is the selected field, to which table sequence A5’s referencing field is assigned.
|
|
7 |
=A2.cursor(EID,NAME;EID=A5.pfind(EID);A4) |
Use K=w filtering mode; in this case w is Ti.pfind(K) and entity table records making EID=A4.pfind(EID) get null or false are discarded; EID is the selected field, to which its sequence numbers in table sequence A5 are assigned.
|
|
8 |
=A2.cursor(EID,NAME;EID:A5;A4) |
Use K:Ti filtering mode; compare the entity table’s EID values with the table sequence’s key values and discard entity table records that cannot match.
|
|
9 |
=A2.cursor(NAME,SALARY;EID:A5;A4) |
This is a case where K isn’t selected; EID isn’t the selected field, so only filtering is performed.
|
|
10 |
=A2.cursor(EID,NAME;EID:A5:null;A4) |
Use K:Ti:null filtering mode; compare the entity table’s EID values with the table sequence’s key values and discard entity table records that can match.
|
|
11 |
=A2.cursor(EID,NAME;EID:A5:#;A4) |
Use K:Ti:# filtering mode; compare with sequence numbers of table sequence’s records according to the entity table’s EID values, and discard records that cannot match.
|
|
12 |
=connect("demo").query("select top 2 NAME,GENDER from employee").keys(NAME) |
Return a table sequence using NAME as the key.
|
|
13 |
=A2.cursor(EID,NAME;(EID=A5.find(EID),NAME=A12.find(NAME),EID!=null &&NAME!=null);A4) |
Use (K1=w1,…Ki=wi,w) filtering mode; return records that meet all conditions.
|
Use @w option to recognize update mark:
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME from employee") |
|
|
2 |
=file("e-mcs.ctx") |
Generate a composite table file. |
|
3 |
=A2.create@y(#EID,NAME) |
Create the composite table’s base table. |
|
4 |
=A3.append(A1) |
Append cursor A1’s data to the composite table’s base table. |
|
5 |
=A4.cursor@m(;;3) |
Create a 3-subcursor multicursor based on the composite table. |
|
6 |
=connect("demo").cursor("select EID,NAME,GENDER from employee") |
|
|
7 |
=A6.derive(:Defiled) |
|
|
8 |
=A7.new(EID,Defiled,NAME,GENDER) |
Return a cursor whose content is as follows:
|
|
9 |
=file("ecd.ctx":[1,2]) |
Define a homo-name files group: 1.ec.ctx and 2.ec.ctx. |
|
10 |
=A9.create@yd(#EID,Defiled,NAME,GENDER;if(GENDER=="F",1,2)) |
Create a multizone composite table, set EID as its key, use @d option to make Defiled as the update mark field, and put records where GENDER is F to 1.ed.ctx and the other records to 2.ed.ctx. |
|
11 |
=A10.append@ix(A8) |
Append cursor A8’s data to A10’s multizone composite table. |
|
12 |
=create(EID,Defiled,NAME,GENDER).record([0,true,,,1,true,,, 2,false,"BBB","F"]) |
Return a table sequence whose content is as follows:
|
|
13 |
=file("ecd.ctx":[3]) |
|
|
14 |
=A13.create@yd(#EID,Defiled,NAME,GENDER;3) |
Add a new zone table 3.ecd.ctx, where Defiled is the update mark field. |
|
15 |
=A14.append@i(A12) |
Append table sequence A12’s records to zone table 3.ecd.ctx. |
|
16 |
=file("ecd.ctx":[1,2,3]).open() |
|
|
17 |
=A16.cursor(;;A5) |
Split A16’s multizone composite table synchronously according to multicursor A5, and return a multicursor. |
|
18 |
=A17.fetch() |
Fetch data from cursor A17.
|
|
19 |
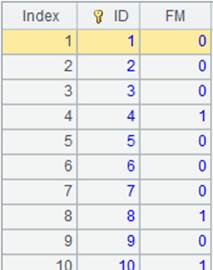
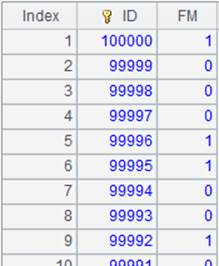
=A16.cursor@w(;;A5) |
Use @w option to split multizone composite table ecd.ctx into multiple segments according to multicursor A5, return the segmented composite table as a multicursor, recognize the update mark – that is: won’t return the record whose EID value is 1 and whose update mark is true (meaning to-be-deleted) to the result multicursor; Modify the record whose EID value is 2 and whose update mark is false (meaning to-be-modified); Retain the record whose primary key value is unique though it is marked by a deletion mark – that is, return the record whose EID value is 0 to the result multicursor. |
|
20 |
=A19.fetch() |
Fetch data from cursor A19.
|
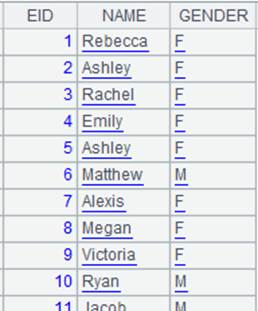
T.cursor(x:C,…;wi,...;mcs)
Description:
Synchronously segment a cluster entity table according to a cluster multicursor and return a cluster multicursor.
Syntax:
T.cursor(x;C,…;wi;mcs)
Note:
The function synchronously segments cluster entity table T according to cluster multicursor mcs, during which T’s dimension and mcs’s key will be matched, and returns a cluster multicursor; the way of distributing T and mcs among nodes must be the same and the fields for segmenting T and mcs should be consistent. If multiple cluster entity tables are involved, use a cluster multicursor as a reference to make sure the segmentation is synchronous.
Parameter:
|
T |
A cluster entity table |
|
x |
Expression |
|
wi |
Filtering condition; retrieve the whole set when this parameter is absent; separate multiple conditions by comma(s) and their relationships are AND |
|
mcs |
A cluster multicursor generated from a cluster entity table |
Return value:
A cluster multicursor
Example:
|
|
A |
|
|
1 |
=file("cs1.ctx":[1],"169.254.121.62:8281") |
|
|
2 |
=A1.open() |
Open a cluster composite table. |
|
3 |
=A2.attach(table1) |
Retrieve cluster entity table table1. |
|
4 |
=A3.cursor@m(;;2) |
Return a cluster multicursor. |
|
5 |
=A2.attach(table2) |
Retrieve cluster entity table table2. |
|
6 |
=A5.cursor(;;A4) |
Segment cluster entity table table2 according to table1’s multicursor; the two tables should use same segmenting field. |
T.cursor()
Description:
Get a cursor based on a pseudo table object.
Syntax:
T.cursor(xi:Ci,…)
Note:
The function gets a cursor based on pseudo table T by specifying field expressions xi and field names Ci, which, by default, field names in the pseudo table. It gets a cursor using all fields of the pseudo table when paramters xi:Ci are absent.
Parameter:
|
T |
A pseudo table |
|
xi |
A field expression |
|
Ci |
Field name in a result table sequence |
Option:
|
@v |
Store the composite table in the column-wise format when loading it the first time, which helps to increase performance |
Return value:
A cursor
Example:
|
|
A |
|
|
1 |
=create(file).record(["D:/file/pseudo/empT.ctx"]) |
|
|
2 |
=pseudo(A1) |
Generate a pseudo table object. |
|
3 |
=A2.cursor() |
Generate a cursor from A2’s pseudo table using all its fields, since no parameters are present. |
|
4 |
=A3.fetch() |
Below is data in A3’s cursor:
|
|
5 |
=A2.cursor(EID:eid,NAME,SALARY:salary) |
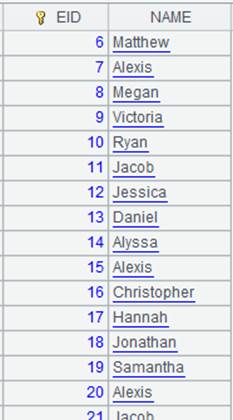
Retrieve fields EID, NAME and SALARY from the pseudo table to generate a cursor with new field names eid, NAME and salary respectively. |
|
6 |
=A5.fetch() |
Below is data in A5’s cursor:
|


Description:
Merge subcursors in a multicursor into a unicursor or a new multicursor with a smaller number of parallel subcursors.
Syntax:
mcs.cursor(n)
Note:
The function merges subcursors in a multicursor into a unicursor, which is the default, or a new multicursor with a smaller number, which is specified by parameter n, of parallel subcursors.
Parameter:
|
mcs |
A multicursor |
|
n |
Subcursor column name |
Return value:
A common cursor or a multicursor
Example:
|
|
A |
|
|
1 |
=demo.query("select * from EMPLOYEE").cursor@m(5) |
Return a multicursor having 5 subcursors. |
|
2 |
=A1.cursor(3) |
Merge subcursors in the multicursor and convert it to a 3-subcursor multicursor. |
|
3 |
=A2.cursor() |
Convert a multicursor to a unicursor. |