merge()
Here’s how to use merge() function.
A. merge()
Description:
Merge multiple table sequences/record sequences.
Syntax:
A.merge (xi,…)
Note:
The function merges members of sequence A according to xi field in order.
By default, A(i) is treated as ordered by [xi,…]; when xi is absent and when no primary key is set for A(i) or A(i) is unordered, use @o option to simply concatenate members.
Parameter:
|
A |
A sequence made up of multiple table sequences/record sequences of the same structure. |
|
xi |
A field of A(i); if performing merge by multiple fields, use the comma to separate them, for example, x1,x2...; xi is by default the primary key of为A(i) . |
Option:
|
@u |
Remove the duplicates from the table sequence/record sequence generated from unioning members of A(i)s in certain order; records with same xi have same corresponding members of A(i). |
|
@i |
Return a table sequence/record sequence composed of the common members of A(i)s. |
|
@d |
Generate a new table sequence/record sequence by removing members of A(2)&…A(n) from A(1). |
|
@o |
Do not assume that A(i) is ordered by [xi,…], and thus simply concatenate members instead of performing the merge operation. |
|
@0 |
Put records with null values at the end. |
|
@x |
Remove common members of A(i) and union the other members to generate a new table sequence/sequence. |
Return value:
Table sequence/record sequence
Example:
Order-based MERGE:
|
|
A |
|
|
1 |
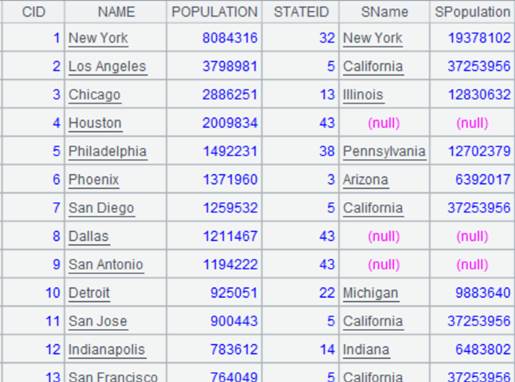
=demo.query("select top 6 * from DEPT order by FATHER ").sort(DEPTID,DEPTNAME) |
Return a table sequence ordered by DEPTID and DEPTNAME:
|
|
2 |
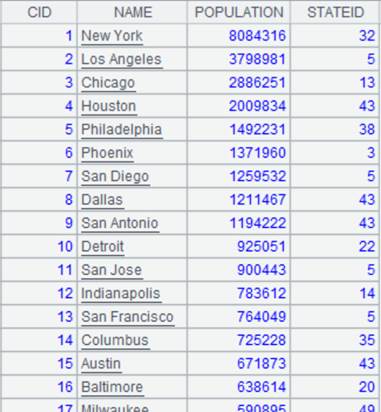
=demo.query("select * from DEPT where DEPTID <8 order by FATHER").sort(DEPTID,DEPTNAME) |
Return a table sequence ordered by DEPTID and DEPTNAME:
|
|
3 |
=[A1,A2].merge(DEPTID,DEPTNAME) |
Merge A1 and A2 according to DEPTID and DEPTNAME in order:
|

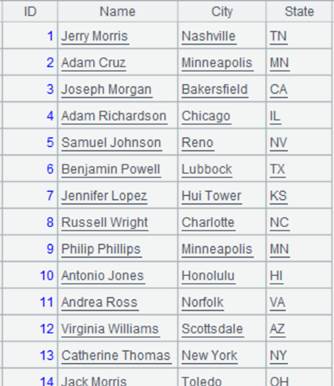

MERGE by the primary key when xi is by default the primary key of A(i):
|
|
A |
|
|
1 |
=connect("demo").query("select top 6 * from DEPT order by FATHER ").keys(DEPTID).sort(DEPTID) |
Return a table sequence using DEPTID as the primary key:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER").keys(DEPTID).sort(DEPTID) |
Return a table sequence using DEPTID as the primary key:
|
|
3 |
=[A1,A2].merge() |
Merge A1 and A2 according to primary key DEPTID as parameter xi is absent:
|
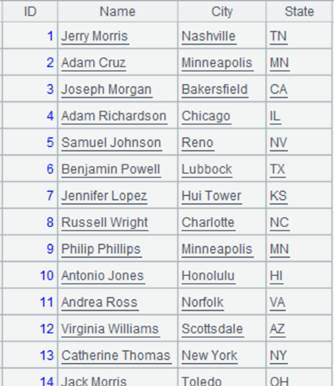
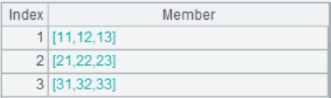
Other methods of MERGE:
|
|
A |
|
|
1 |
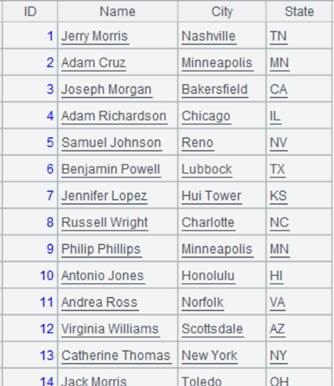
=connect("demo").query("select top 6 * from DEPT order by FATHER ").keys(DEPTID).sort(DEPTID) |
Return a table sequence using DEPTID as the primary key:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER").keys(DEPTID).sort(DEPTID) |
Return a table sequence using DEPTID as the primary key:
|
|
3 |
=[A1,A2].merge@u() |
Merge A1 and A2 according to primary key DEPTID as parameter xi is absent, and use @u option to remove duplicate records having same DEPTID:
|
|
4 |
=[A1,A2].merge@i() |
Merge A1 and A2 according to primary key DEPTID as parameter xi is absent, and use @i option to retain only common members of A1 and A2:
|
|
5 |
=[A1,A2].merge@d() |
Merge A1 and A2 according to primary key DEPTID as parameter xi is absent, and use @d option to return a sequence of members of A2 from which members of A1 is removed:
|
|
6 |
=[A1,A2].merge@x() |
Merge A1 and A2 according to primary key DEPTID as parameter xi is absent, and use @x option to return a sequence of members of both A1 and A2 from which their common members are removed:
|
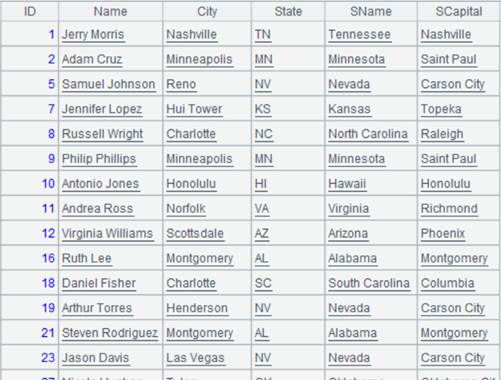
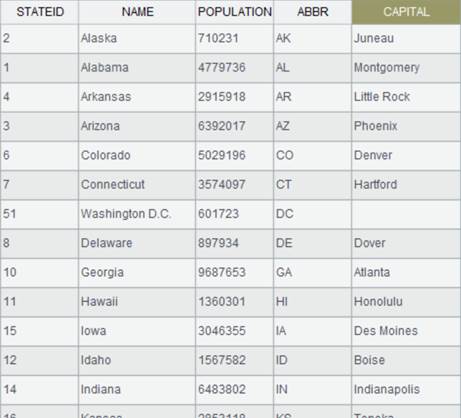
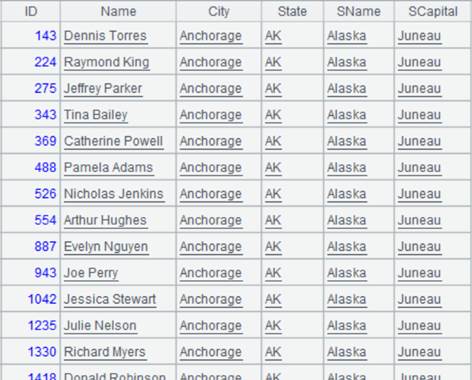

Use @o option to simply concatenate records instead of performing the order-based MERGE:
|
|
A |
|
|
1 |
=connect("demo").query("select top 6 * from DEPT order by FATHER ") |
Return a table sequence:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER") |
Return a table sequence:
|
|
3 |
=[A1,A2].merge@o() |
Records of A1 and A2 are unordered; use @o option to simly concatenate them without sorting:
|
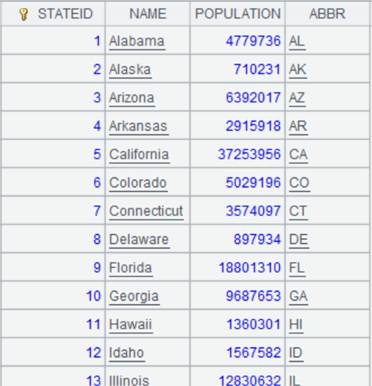

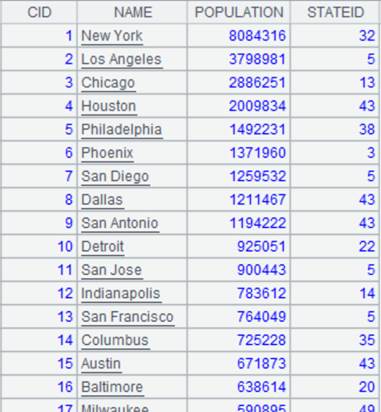
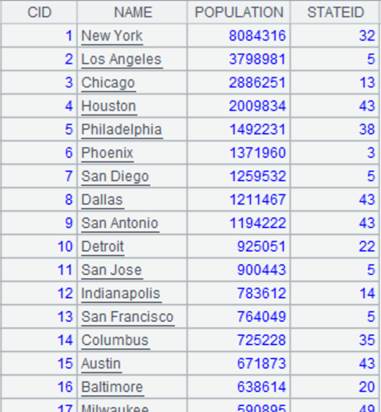
Use @0 option to place records whose primary keys are null at the end:
|
|
A |
|
|
1 |
=connect("demo").query("select top 6 * from DEPT order by FATHER ").keys(DEPTID).sort(DEPTID) |
Return a table sequence:
|
|
2 |
=connect("demo").query("select * from DEPT where DEPTID <8 order by FATHER").keys(DEPTID).sort(DEPTID) |
|
|
3 |
=A2(7).modify(null:DEPTID) |
Now this is data of A2’s table sequence:
|
|
4 |
=[A1,A2].merge() |
|
|
5 |
=[A1,A2].merge@0() |
Merge A1 and A2 according to primary key DEPTID as parameter xi is absent, and use @0 option to place records where DEPTID is null at the end:
|


CS.merge()
Description:
Merge data of the member cursors of a sequence of cursors and return a multicursor.
Syntax:
CS.merge(xi,…)
Note:
CS is a sequence of cursors ordered by [xi,…], and from each cursor a sequence of records can be output. The function merges the records of these cursors by the expression xi and returns a multicursor.
Members of the cursor sequence must be of the same structure. If members are multicursors, they must have the same number of parallel cursors and be segmented synchronically.
This is a delayed function.
Parameter:
|
CS |
A sequence of cursors. |
|
xi |
An expression. If performing merge by multiple fields, use comma to separate them, for example, x1,x2... |
Option:
|
@u |
Union operation. Remove the duplicate records from the resulting cursor obtained by unioning the cursor members of CS in certain order. By default, the duplicate records are included. |
|
@i |
Intersection operation. Return a cursor composed of common members of members of CS, the sequence of cursors. |
|
@d |
Difference operation. Create a new cursor by removing members of CS2&…CSn from CS1. |
|
@0 |
Put records with null values at the end. |
|
@x |
Only merge distinct records in member cursors. |
Return value:
Multicursor
Example:
|
|
A |
|
|
1 |
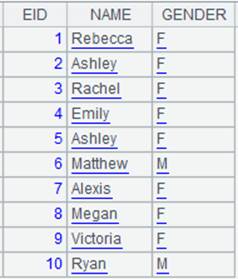
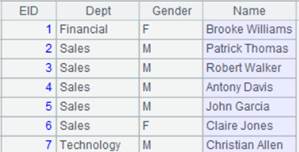
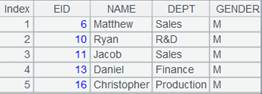
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
Return a cursor whose data is as follows:
|
|
2 |
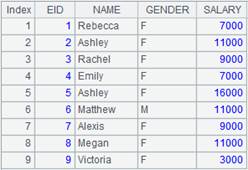
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
Return a cursor whose data is as follows:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
Return a cursor whose data is as follows:
|
|
4 |
=[A1,A2,A3] |
Return a sequence of cursors. |
|
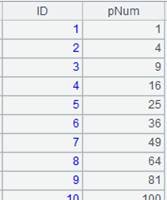
5 |
=A4.merge(EID) |
Merge records in the cursor members of the sequence in order according to EID field. |
|
6 |
=A5.fetch() |
Fetch data from cursor A5 (it would be better to fetch data in batches when a huge amount of data is involved):
|

Use @u option to perform union operation:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
Return a cursor whose data is as follows:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
Return a cursor whose data is as follows:
|
|
4 |
=[A1,A2,A3] |
Return a sequence of cursors. |
|
5 |
=A4.merge@u(EID) |
Use @u option to merge records of member cursors in the sequence in order according to EID field, during which dulicate members are discarded. |
|
6 |
=A5.fetch() |
Fetch data from cursor A5:
|

Use @i option to perform intersection operation:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
Return a cursor whose data is as follows:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
Return a cursor whose data is as follows:
|
|
4 |
=[A1,A2,A3] |
Return a sequence of cursors. |
|
5 |
=A4.merge@i(EID) |
Use @i option to get the intersection and returna cursor containing common records of the member cursors in the sequence. |
|
6 |
=A5.fetch() |
Fetch data from cursor A5:
|

Use @d option to perform difference operation:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
Return a cursor whose data is as follows:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
Return a cursor whose data is as follows:
|
|
4 |
=[A1,A2,A3] |
Return a sequence of cursors. |
|
5 |
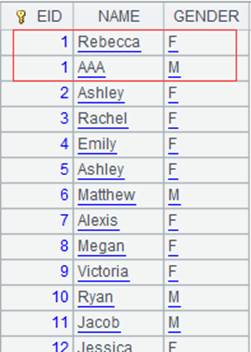
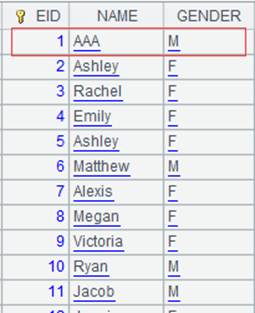
=A4.merge@d(EID) |
Use @d option to perform the difference operation that removes records of cursor A2 and cursor A3 from cursor A1 and forms a new cursor. |
|
6 |
=A5.fetch() |
Fetch data from cursor A5:
|
Use @x option to get non-duplicate members from the sequence of cursors to form a new sequence:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 EID,NAME,DEPT,GENDER FROM employee ") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where GENDER='M' ") |
Return a cursor whose data is as follows:
|
|
3 |
=connect("demo").cursor("SELECT top 5 EID,NAME,DEPT,GENDER FROM employee where DEPT='Sales' ") |
Return a cursor whose data is as follows:
|
|
4 |
=[A1,A2,A3] |
Return a sequence of cursors. |
|
5 |
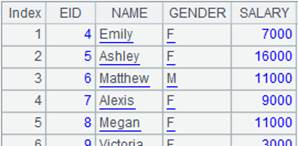
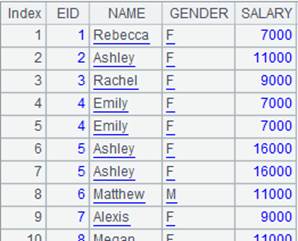
=A4.merge@x(EID) |
Use @x option to perform the difference operation that gets non-duplicate records from members cursors of the sequence to form a new sequence. |
|
6 |
=A5.fetch() |
Fetch data from cursor A5:
|
Related function: