A.group(x:F,...;y:G,… )
Description:
Group a sequence and then perform aggregate operations.
Syntax:
A.group(x:F,...;y:G,…)
Note:
The function groups a sequence according to a single or multiple fields/expressions x, aggregates each group of data and generates a new table sequence made up of fields F,... G,… and ordered by grouping expression x. G field gets values by computing y over each group.
Option:
|
@o |
Group records by comparing adjacent ones, which is equal to the merging operation, and the result set won’t be sorted |
|
@n |
x gets assigned with group numbers which can be used to define the groups. @n and @o are mutually exclusive |
|
@u |
Do not sort the result set by x. It doesn’t work with @o/@n |
|
@i |
x is a Boolean expression. If the result of x is true, then start a new group. There is only one x |
|
@0 |
Discard the group over which the result of grouping expression x is null |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@t |
Return an empty table sequence with data structure if the grouping and aggregate operation over the sequence returns null |
|
@s |
Summarize data cumulatively |
Parameter:
|
A |
A sequence |
|
x |
Grouping expression. If omitting x:F, aggregate the whole set without grouping; in this case “;” must not be omitted |
|
F |
Field name of the result table sequence |
|
G |
Names of summary fields in the result table sequence |
|
y |
Aggregate expression in which ~ is used to reference a group |
Return value:
Sequence
Example:
|
|
A |
|
|
1 |
=demo.query("select * from SCORES") |
|
|
2 |
=A1.group(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
|
|
3 |
=A1.group@o(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
Only the adjacent ones will be compared and group them together if they are the same. The result set won’t be sorted. |
|
4 |
=demo.query("select * from STOCKRECORDS where STOCKID<'002242'") |
|
|
5 |
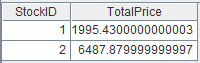
=A4.group@n(if(STOCKID=="000062",1,2):StockID;~.sum(CLOSING):TotalPrice) |
x gets assigned with group numbers. |
|
6 |
=A1.group(;~.sum(SCORE):TotalScore) |
Parameters x:F are omitted, so compute the total score of all the students. |
|
7 |
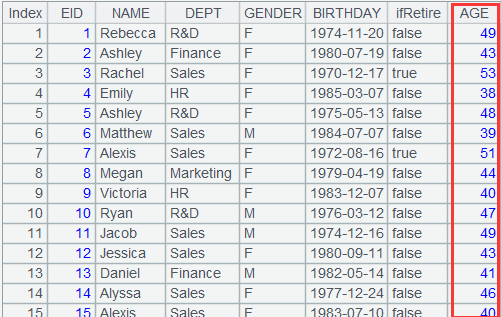
=demo.query("select * from EMPLOYEE") |
|
|
8 |
=A7.group@u(STATE:State;~.count(STATE):TotalScore) |
Do not sort result set by the sorting field. |
|
9 |
=A7.group@i((GENDER=="F"):IsF;~.count():Number) |
Start a new group when GENDER=="F". |
|
10 |
=file("D:\\Salesman.txt").import@t() |
|
|
11 |
=A10.group@0(Gender:Gender;~.sum(Age):Total) |
Discard the groups where GENDER values are null. |
|
12 |
=file("D:/emp10.txt").import@t() |
For
data file emp10.txt, every 10
records are ordered by DEPT |
|
13 |
=A12.group@h(DEPT:dept;~.sum(SALARY):bouns) |
As A12 are segmented and ordered by DEPT, @h option is used to speed up grouping.
|
|
14 |
=demo.query("select * from EMPLOYEE where EID > 500") |
Return an empty table sequence. |
|
15 |
=A14.group@t(STATE:State;~.count(STATE):TotalScore) |
Return an empty table sequence with the data structure.
|
|
16 |
=demo.query("select * from employee").group@s(DEPT;sum(SALARY):TotalSalary) |
Perform aggregation cumulatively.
|








Related functions: