A.group(x i ,… )
Description:
Perform equi-grouping according one or more fields or expressions.
Syntax:
A.group(xi,…)
Note:
The function performs equi-grouping on a sequence according to expression xi,…. The result is a sequence/record sequence consisting of groups.
Option:
|
@o |
Group records by comparing adjacent ones, which is equal to the merging operation, and the result set won’t be sorted |
|
@1 |
Get the first record of each group to form a record sequence and return it (Please note that 1 is a number instead of a letter); can work with @v option |
|
@n |
x gets assigned with group numbers which can be used to define the groups; discard groups that make x<1. @n and @0 are mutually exclusive |
|
@u |
Do not sort the result set by x. It doesn’t work with @o/@n |
|
@i |
x is a Boolean expression. If the result of x is true, then start a new group. This option is equivalent to A.group@o(a+=if(x,1,0)), in which a=0 and there is only one x |
|
@0 |
Discard the group over which the result of grouping expression x is null; discard empty groups when @n is also present. Use it when there’s only one expression x |
|
@s |
Perform a concatenation of sequences/records sequences after the grouping. It is equivalent to A.group(xi,…).conj(); can work with @v option |
|
@p |
Return a sequence of integer sequences, each of which contains the positions of members in each group in sequence A |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@v |
When parameter A is a pure table sequence, return a set of pure table sequences |
Parameter:
|
A |
A sequence |
|
xi |
Grouping expression |
Return value:
Sequence / Record sequence
Example:
Group a sequence:
|
|
A |
|
|
1 |
[6,9,12,15,16,5,1,7,8] |
|
|
2 |
=A1.group(~%2) |
[[6,12,16,8],[ 9,15,5,1,7]] The series is divided into two groups. Divide the number of members in both groups by 2, one of the remainders is 0 and the other is 1. |
|
3 |
=A1.group(~%2,~%3) |
[[6,12],[16],[8],[9,15],[1,7],[5]]. Group the series according to multiple expressions. |
|
4 |
=[6,9,16,5,1,7,8].group@s(~%2) |
Divide the sequence into a group of odd numbers and a group of even numbers, and then concatenate them.
|
|
5 |
=A1.group((#-1)\3) |
Group sequence A1 every 3 members.
|
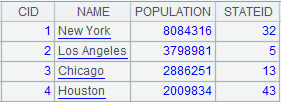

Reuse the grouping result:
|
|
A |
|
|
1 |
=demo.query("select NAME,BIRTHDAY,GENDER from EMPLOYEE") |
|
|
2 |
=A1.group(GENDER) |
Group A1’s table sequence by GENDER:
[Each group is a sequence:
|
|
3 |
=A2.new(GENDER:Gender,~.count():Number) |
Count members of each group. |
|
4 |
=A2.new(GENDER:Gender,~.avg(age(BIRTHDAY)):Average) |
Get different statistical results using the same grouping result. |



Group data by multiple fields:
|
|
A |
|
|
1 |
=demo.query("select NAME,GENDER,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
=A1.group(GENDER,DEPT) |
Group records by multiple fields. |
|
3 |
=A1.group@o(GENDER) |
Records won’t be sorted; only the adjacent ones will be compared and group them together if they match. Same records that are not adjacent may be put into different groups, so there may be overlapped groups and the returned result is a set of sequences.
|
|
4 |
=A1.group@1(GENDER) |
Return the first record of each group.
|
|
5 |
=A1.group@n(if(GENDER=="F",1,2)) |
x gets assigned with group numbers which can be used to define the groups directly. [[Rebecca,Ashley,Rachel,…],[Matthew,Ryan,Jacob,…]] |
|
6 |
=A1.group@u(GENDER,DEPT) |
Do not sort result set by the sorting field. |
|
7 |
=A1.group@i(GENDER=="F") |
Start a new group when GENDER=="F". |
|
8 |
=A1.group@p(GENDER,DEPT) |
Return a sequence of integer sequences, each of which contains the positions of records in a group (grouped by GENDER field and DEPT field) in the original table sequence. |
|
9 |
=file("D:\\Salesman.txt").import@t() |
|
|
10 |
=A9.group@0(Gender) |
Group the table sequence by GENDER field, while discarding groups with null values. |
|
11 |
=file("D:/emp10.txt").import@t() |
For data fiel emp10.txt, every 10 records are ordered by DEPT.
|
|
12 |
=A11.group@h(DEPT) |
As A11 is segmented and ordered by DEPT, @h option is used to speed up grouping.
|
|
13 |
=A1.group@n(if(DEPT=="HR":1,DEPT=="Sales":2;0)) |
Use @n option to discard groups of records that make the grouping expression less than 1. That is, give up those where DEPT is neither HR nor Sales.
|





When parameter A is a table sequence:
|
|
A |
|
|
1 |
=demo.query@v("select * from EMPLOYEE order by GENDER,DEPT ") |
Return a pure table sequence. |
|
2 |
=A1.group@v(GENDER,DEPT) |
@v option enables returning a set of pure table sequences. |
Related functions: