cs.groups()
Description:
Group records in a cursor.
Syntax:
cs.groups(x:F,…;y:G…)
Note:
The function groups records in a cluster cursor by expression x, sorts result by the grouping field, and calculates the aggregate value on each group. This creates a new table sequence consisting of fields F,...G,… and sorted by the grouping field x. The values of F field are the value of x field of the first record in each group and G field gets values by computing yon each group. The aggregation over a cluster cursor will first be performed by the main process on the local machine and the result will then be returned to the machine that initiates the invocation; the process is called reduce.
Option:
|
@n |
The value of grouping expression is group number used to locate the group; you can use n to specify the number of groups and generate corresponding number of zones first |
|
@u |
Do not sort the result set by the grouping expression; it doesn’t work with @n |
|
@o |
Compare each record only with its neighboring record to group, which is equivalent to the merge operation, and won’t sort the result set |
|
@i |
With this option, the function only has one parameter x that is a Boolean expression; start a new group if its result is true |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@0 |
Discard groups on which expression x gets empty result |
|
@t |
When empty data is obtained from the cursor, the function returns an empty table sequence having only the data structure |
|
@z(…;…;n) |
Split the sequence according to groups during parallel computation, and the multiple threads share a same result set; in this case HASH space will not be dynamically adjusted; parameter n is HASH space size, whose value can be default |
|
@e |
Return a table sequence consisting of results of computing function y; expression x is a field of cursor cs and y is a function on cs; the result of y must be one record of cs and y only supports maxp, minp and top@1 when it is an aggregate function |
Parameter:
|
cs |
Records in a cursor |
|
x |
Grouping expression; if omitting parameters x:F, aggregate the whole set; in this case, the semicolon “;” must not be omitted |
|
F |
Field name in the result table sequence |
|
y |
An aggregate function on cs, which only supports sum/count/max/min/top/avg/iterate/concat/var; when the function works with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted |
|
G |
Aggregate field name in the result table sequence |
Return value:
Table sequence
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES where CLASS = 'Class one'") |
|
|
2 |
=A1.groups(;sum(SCORE):TotalScore) |
As parameters x:F absent, calculate the total score of all students. |
|
3 |
=demo.cursor("select * from FAMILY") |
|
|
4 |
=A3.groups(GENDER:gender;sum(AGE):TotalAge) |
Group and order data by specified fields. |
|
5 |
=demo.cursor("select * from STOCKRECORDS where STOCKID<'002242'") |
|
|
6 |
=A5.groups@n(if(STOCKID=="000062",1,2):SubGroups;sum(CLOSING):ClosingPrice) |
The value of grouping expression is group number; put records whose STOCKID is “000062” to the first group and others to the second group; and meanwhile aggregate each group. |
|
7 |
=demo.cursor("select * from EMPLOYEE") |
|
|
8 |
=A7.groups@u(STATE:State;count(STATE):Total) |
The result set won’t be sorted by the grouping field. |
|
9 |
=demo.cursor("select * from EMPLOYEE") |
|
|
10 |
=A9.groups@o(STATE:State;count(STATE):Total) |
Compare each record with its next neighbor and won’t sort the result set.
|
|
11 |
=demo.cursor("select * from EMPLOYEE") |
|
|
12 |
=A11.groups@i(STATE=="California":IsCalifornia;count(STATE):count) |
Start a new group if the current record meets the condition STATE=="California". |
|
13 |
=file("D:/emp10.txt").cursor@t() |
For
data file emp10.txt, every 10
records are ordered by DEPT |
|
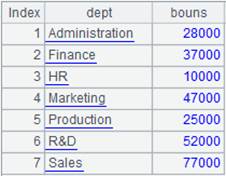
14 |
=A13.groups@h(DEPT:DEPT;sum(SALARY):bouns) |
As A13 is grouped and ordered by DEPT, use @h option to speed up grouping.
|
|
15 |
=demo.query("select * from employee") |
|
|
16 |
=A15.cursor@m(3) |
Return a multicursor. |
|
17 |
=A16.groups(STATE:state;sum(SALARY):salary) |
Group the multicursor with groups function.
|



|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES where CLASS = 'Class three'") |
|
|
2 |
=A1.groups@t(STUDENTID:StudentID;sum(SCORE):TotalScore) |
Return an empty table sequence with the original data structure.
|
|
3 |
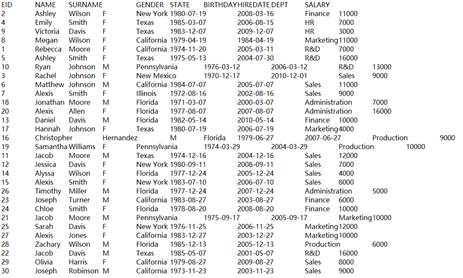
=demo.cursor("select * from DEPT") |
Below is content of DEPT table:
|
|
4 |
=A3.groups@0(FATHER) |
Discard groups on which Father field expression gets empty value.
|



Use @z option to enable parallel processing:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES") |
|
|
2 |
=A1.groups@z(STUDENTID:StudentID;sum(SCORE):TotalScore;5) |
Split A1’s sequence according to groups during parallel computation; HASH space size is 5. |
Use @e option to return a table sequence consisting of results of computing function y:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES") |
|
|
2 |
=A1.groups@e(SUBJECT;maxp(SCORE)) |
Return a table sequence consisting of result records of computing maxp(SCORE) . |
