htmlparse()
Description:
Get text data under a specified tag in an html file.
Syntax:
s.htmlparse(tag:i:j,…)
Note:
The function gets the jth text file under the ith tag from html file s.
Retrieve the first text file under the ith tag when parameter j is absent; get all text data under all tags when parameter i is absent; get all text data in the html file when there aren’t parameters.
Parameter:
|
s |
Content of an html file |
|
tag |
A tag in an html file; if the tag’s value is “table”, get all data under it |
|
i |
An integer |
|
j |
An integer |
Option:
|
@0 |
Retain null values; null values will be removed by default. |
|
@p |
Parse the html file as numbers of corresponding data type. |
Return value:
Sequence
Example:
|
|
A |
|
|
1 |
=file("D:/test.html").read() |
Read the content of an html file. |
|
2 |
=A1.htmlparse("a":11:0) |
Get the 1st text file under the 12th <a> from A1’s html file. |
|
3 |
=A1.htmlparse("a":11:0, "span":8:0) |
Get text files under two tags from A1’s html file. |
|
4 |
=A1.htmlparse("table":7) |
Get all content under the 8th <table>. |
|
|
A |
|
|
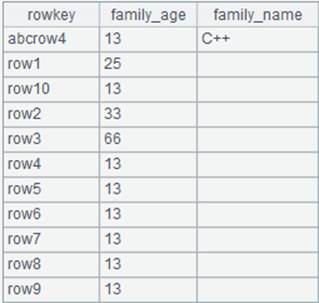
1 |
=file("rq.html").read() |
Read content of the html file and return the following result:
|
|
2 |
=A1.htmlparse("p":5) |
Get the 1st text file under the 5th <p> tag from A1:
|
|
3 |
=A1.htmlparse("p") |
Get text files under all <p> tags from A1:
|
|
4 |
=A1.htmlparse@0("p") |
Get text files under all <p> tags from A1; @0 option works to retain null values:
|
|
5 |
=A1.htmlparse@p("p") |
Get text files under all <p> tags from A1; @p option works to parse them as numbers of corresponding data types:
|