groupc()
Here are how to use groupc() functions.
A.groupc( g ; v )
Description:
Perform row-to-column/column-to-row transposition on member sequences of a sequence.
Syntax:
A.groupc(g;v)
Note:
The function performs row-to-column/column-to-row transposition on member sequences of sequence A; default is row-to-column transposition.
Members of sequence A are also sequences. Both g and v are sequences consisting of sequence numbers of certain members of member sequences of A. Use syntax ~(i) or ~i to reference a member of the member sequence of A.
Group members of sequence A according to g and put members of v to corresponding sequences in each group and return a sequence of sequences.
Parameter:
|
A |
A sequence of sequences |
|
g |
A sequence consisting of sequence numbers of certain members of member sequences of A |
|
v |
A sequence consisting of sequence numbers of certain members of member sequences of A |
Option:
|
@r(g;v;k) |
Perform column-to-row transposition. k is an integer; group v every k members, concatenate each group with g to form a new sequence, and return a sequence consisting of these new sequences |
Return value:
Sequence of sequences
Example:
|
|
A |
|
|
1 |
=file("t3.txt").cursor@w().fetch() |
Return a sequence of sequences:
|
|
2 |
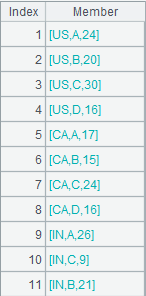
=A1.groupc(~(1);[(~2),(~3)]) |
Perform row-to-column transposition on A1’s members: group A1 by the 1st member of its member sequences, put the 2nd and the 3rd members of the member sequences to corresponding sequences in each group, and return the following result:
|
|
3 |
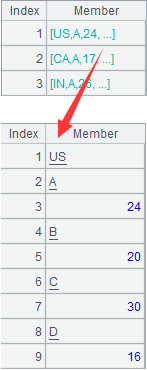
=A2.groupc@r(~1;[~2,~3,~4,~5,~6,~7];2) |
@r option enables column-to-row transposition on A2: put every two members from the 2nd to the 7th in order in each member sequence of A2 in one group, combine each group with the 1st member of A2’s member sequences to form a new member sequence, and return the following result:
|
|
4 |
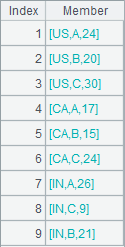
=A2.groupc@r(~1;~.to(2,);2) |
@r option enables column-to-row transposition on A2: put every two members from the 2nd to the last in order in each member sequence of A2 in one group, combine each group with the 1st member of A2’s member sequences to form a new member sequence, and return a result same as A1. |
When parameter g has multiple members:
|
|
A |
|
|
1 |
=connect("demo").query("select top 9 * from scores").array@b() |
Return a sequence of sequences:
|
|
2 |
=A1.groupc([~1,~2];[~3,~4]) |
Perform row-to-column transposition on A1’s members: group A1 by the 1st and 2nd members of its member sequences, put the 3rd and the 4th members of the member sequences to corresponding sequences in each group, and return the following result:
|
|
3 |
=A2.groupc@r([~1,~2];~.to(3,);2) |
@r option enables column-to-row transposition on A2: put every two members from the 3rd to the last in order in each member sequence of A2 in one group, combine each group with the 1st and the 2nd members of A2’s member sequences to form a new member sequence, and return a result same as A1. |

Related concept:
P.groupc( g:G , … ; F ,…; N ,… )
Description:
Perform row-to-column/column-to-row transposition on multiple columns of a table sequence.
Syntax:
P.groupc(g:G,…;F,…;N,…)
Note:
The function performs row-to-column/column-to-row transposition on multiple columns of table sequence/record sequence P; default is row-to-column transposition.
Group table sequence/record sequence P by grouping field/grouping expression g, whose name is G. N,… are names of the new columns. Put values of fields F,… in each group under corresponding new columns N,… in order while ignoring extra new columns.
Parameter:
|
P |
A table sequence/record sequence |
|
g |
The grouping field/grouping expression |
|
G |
Field names of the result set; by default, it is name of grouping field g |
|
F |
Field names of P; by default use all fields of P except for g,… |
|
N |
Names of new columns; by default, use sequence numbers to represent the column names |
Option:
|
@r |
Perform column-to-row transposition. Put values of fields F,… in each group under corresponding new columns N,… in order and discard rows where N values are empty |
Return value:
Table sequence
Example:
Transpose rows to columns:
|
|
A |
|
|
1 |
=file("t1.txt").import@t() |
Return a table sequence:
|
|
2 |
=A1.groupc(Country:COUNTRY;Label,Total;L1,T1,L2,T2,L3,T3,L4,T4,L5,T5) |
Group table sequence A1 by Country field and define new field name as COUNTRY; put values of Label field and Total field under corresponding new columns L1, T1, L2, T2, L3, T3, L4, T4, L5 and T5 in order and return the following result:
Ignore the extra columns L5 adn T5. |
|
3 |
=A1.groupc(Country;Label,Total;) |
Use sequence numbers as new column names as parameter N,… is absent, and use name of g field as parameter G is absent; and return the following result:
|
|
4 |
=A1.groupc(Country;;) |
Use all fields except for Country as parameter F,… is absent and retrun same result as A3. |
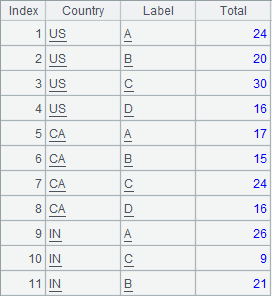


Transpose columns to rows:
|
|
A |
|
|
1 |
=file("t2.txt").import@t() |
Return a table sequence:
|
|
2 |
=A1.groupc@r(Country;Label1,Total1,Label2,Total2,Label3,Total3,Label4,Total4;Label,Total) |
@r option enables column-to-row transposition: group A1 by Country, put values of Label1, Total1, Label2, Total2, Label3, Total3, Label4 and Total4 fields in each group under corresponding new columns Label and Total in order and return the following result:
|
|
3 |
=A1.groupc@r(Country;;Label,Total) |
Use all fields of A1 except for Country as parameter F,… is absent and retrun same result as A2. |


Related concept: