iselect()
Here’s how to use iselect() function.
f. iselect()
Description:
Create a cursor based on an ordered file and return it.
Syntax:
|
f.iselect(A,x;Fi,…;s) |
Retrieve records from file f that is ordered by field/expression x, according to the criterion that the values of x should be members of sequence A |
|
f.iselect(a:b,x;Fi,…;s) |
Retrieve records from file f that is ordered by field/expression x, according to the criterion that the values of x should fall in the interval [a:b] |
Note:
The function retrieves records from file f that is ordered by field/field expression x, according to the criterion that values of x are members of sequence A, or fall in the interval [a:b], and returns the records as a cursor.
Parameter:
|
f |
A file object |
|
A |
A single value or a sequence |
|
[a:b] |
Value range of field name/expression x. Get values from the start when a is absent and get values until the end when b is absent |
|
x |
Field name/expression; the sign # is used to represent a field with a sequence number. |
|
Fi |
Fields to be retrieved, and all fields will be retrieved by default |
|
s |
User-defined separator. The default is tab. When the parameter is omitted, the comma preceding it can be omitted, too |
Option:
|
@t |
Use the first row of f as the field names. If omitted, then use_1,_2,… as the default field names |
|
@b |
Retrieve data from a binary file exported in the export method, with the support for parameters A, x and Fi, and with no support available for parameter s. Ignore options @t, @c, @r, @q, @o, @k, @d, @v and @n. Segments containing no records may appear if it is a file containing a small number of records; an error report will appear if the file isn’t segmented when being retrieved |
|
@c |
Use comma as the separator when parameter s is absent |
|
@r |
Find all records with the same value of x field; by default, x is distinct in the file f |
|
@q |
First remove quotation marks surrounding strings, including the headers, and then handle the escaping |
|
@o |
Use quotation marks as the escape character |
|
@k |
Retain white spaces on both sides of the data item; without it white spaces on both ends will be automatically deleted |
|
@e |
Return a null column if parameter Fi doesn’t exist; the default way of handling is to report error |
|
@d |
Perform type matching and delete a record if there is mismatching data type or format in it |
|
@v |
Throw an exception, terminate execution, and output the content of the current record when errors appear in @d check and @n check |
|
@n |
Discard a row whose number of columns doesn’t match the number in the first row |
Return value:
A cursor
Example:
|
|
A |
|
|
1 |
=to(1:10) |
|
|
2 |
=file("E:/files/employee.txt").iselect(A1,#1;;"|") |
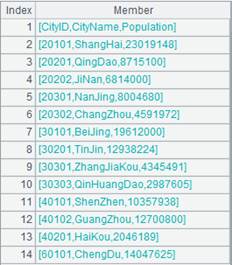
Below is the file employee.txt: The first column is ordered and is separated from the next column by "|". No fields are specified to be retrieved, so all will be retrieved – if the value of the first one is in sequence A1 – and returned as a cursor. |
|
3 |
=A2.fetch() |
|
|
4 |
=file("E:/files/employee1.txt").iselect@t(A1,EID;EID,SALARY) |
Below is the file employee1.txt:
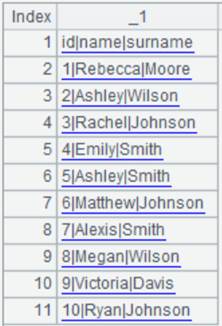
Retrieve corresponding EID and SALARY fields value – if EID value is in sequence A1 – and return them as a cursor. |
|
5 |
=A4.fetch() |
|
|
6 |
=file("E:/files/employee2.txt").iselect@tc(A1,EID) |
Below is the file employee2.txt:
Comma is used as the seperator. |
|
7 |
=A6.fetch() |
|
|
8 |
=file("E:/files/employee3.txt").iselect@b(A1,EID) |
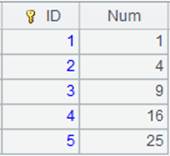
Retrieve the bin file employee3.txt exported through f.export@z(A,x:F,...;s) and get records where EID≤1 and ≥10. |
|
9 |
=A8.fetch() |
|
|
10 |
=file("E:/files/employee1.txt").iselect@t(1:10,EID;EID,SALARY) |
Retrieve EID field and SALARY field according to the condition that EID≤1 and ≥10. |
|
11 |
=A10.fetch() |
Same result as A5. |
|
12 |
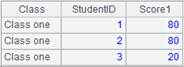
=file("D:/Sale2.txt").iselect@tr(7,ID;ID,ENAME) |
Retrieve all records where ID is 7 from Sales2.txt:
|
|
13 |
=A12.fetch() |
|
|
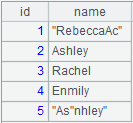
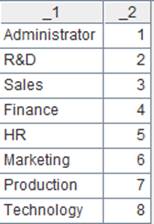
=file("D:/Department1.txt").iselect@t(1:5,id;id,name;"|").fetch() |
|
|
|
15 |
=file("D:/Department1.txt").iselect@tk(2,id;id,name;"|").fetch() |
Use @k option to retain whitespaces on both sides of the data item. |
|
16 |
=file("D:/Department1.txt").iselect@tq(1,id;id,name;"|").fetch() |
Remove quotation marks surrounding strings. |
|
17 |
=file("D:/Department1.txt").iselect@tqo(5,id;id,name;"|").fetch() |
|
|
18 |
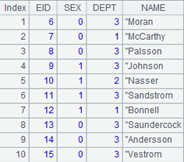
=file("D:/emp1.txt").iselect@et(2:5,EID;EID,SALARY,SEX).fetch() |
Below is the file emp1.txt:
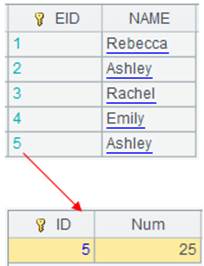
With @e option, the function returns an empty corresponding column since column SEX doesn’t exist in the file.
|
|
19 |
=file("D:/emp1.txt").iselect@tn(7:10,EID;EID,NAME,SALARY).fetch() |
Discard the row where EID is 10 since its number of columns isn’t the same as that in the first row.
|
|
20 |
=file("D:/emp2.txt ").iselect@t(A1,EID-5;;",").fetch() |
Get 10 records whose EIDs are from 5 to 15 and which satisfy the specified expression.
|
|
21 |
=file("D:/emp2.txt ").iselect@t(1:10,EID-5;;",").fetch() |
Use an interval to get the same result.
|