cs.gr oups()
Description:
Group records in a cluster cursor, sort them by the grouping field and perform aggregation over each group and add each aggregate to the result set.
Syntax:
cs.groups(x:F,…;y:G…;n)
Note:
The function groups records in a cluster cursor by expression x, sorts result by the grouping field, and calculates the aggregate value on each group.
This creates a new table sequence consisting of fields F,...G,… and sorted by the grouping field x.The G field gets values by computing y on each group.
Option:
|
@c |
Perform the group operation over data in every node and compose the result sets into a cluster in-memory table in the segmentation way of the cursor; support a cluster dimension table |
Parameter:
|
cs |
Records in a cluster cursor |
|
x |
Grouping expression; if omitting parameters x:F, aggregate the whole set; in this case, the semicolon “;” must not be omitted |
|
F |
Field name in the result table sequence |
|
y |
An aggregate function on cs, which only supports sum/count/max/min/top /avg/iterate/concat/var; when the function works with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted |
|
G |
Aggregate field name in the result table sequence |
|
n |
The specified maximum number of groups; stop executing the function when the number of data groups is bigger than n to prevent memory overflow; the parameter is used in scenarios when it is predicted that data will be divided into a large number of groups that are greater than n |
Return value:
A table sequence/cluster in-memory table
Example:
|
|
A |
|
|
1 |
=file("emp1.ctx","192.168.0.111:8281") |
Below is emp1.ctx:
|
|
2 |
=A1.open() |
Open a cluster composite table. |
|
3 |
=A2.cursor() |
Return a cluster cursor. |
|
4 |
=A3.groups(Dept:dept;count(Name):count) |
Group data by DEPT and perform aggregation. |


|
|
A |
|
|
1 |
[192.168.0.110:8281,192.168.18.143:8281] |
|
|
2 |
=file("emp.ctx":[1,2], A1) |
|
|
3 |
=A2. open () |
Open a cluster composite table. |
|
4 |
=A3.cursor() |
Create a cluster cursor. |
|
5 |
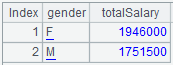
=A4.groups(GENDER:gender;sum(SALARY):totalSalary) |
Group data by GENDER and perform aggregation and return result as a table sequence.
|
|
6 |
=A3.cursor() |
|
|
7 |
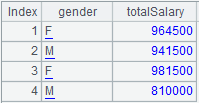
=A6.groups@c(GENDER:gender;sum(SALARY):totalSalary).dup() |
Retain the way of segmentation of the distributed cursor and return a cluster in-memory table.
|
Related function: