A.new( x i : F i ,… )
Description:
Perform computation on a sequence to generate a new table sequence.
Syntax:
A.new(xi:Fi,…)
Note:
The function computes expression xi on each member of sequence A and generate a new table sequence having same number of records as A and using xi as field values and Fi as field names.
Parameter:
|
Fi |
Field names of the result table sequence; use xi when the parameter is absent; use the original field names when xi is #i. |
|
xi |
An expression whose results are field values; if omitted, field values will be nulls a, and when is absent, :Fi must not be omitted. |
|
A |
A sequence. |
Option:
|
@m |
Use parallel processing to speed up computation. |
|
@i |
Won’t generate a record if the result of expression xi is null. |
|
@o |
When parameter A is a pure table sequence, directly reference an old column if it is unmodified instead of generating a new column; sequence A will also be updated when the result table sequence is updated. |
|
@z |
Perform an inverse operation; only apply to non-pure sequences. |
Return value:
Table sequence
Example:
Ø Generate from an individual table sequence
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
=A1.new(EID:EmployeeID,NAME, #3:dept) |
Generate a new table sequence directly. If the field names are the same as those of A1, Fi can be omitted. |
|
3 |
=A1.new(NAME,age(BIRTHDAY):AGE) |
Generate the new table sequence by computing new field values. |
|
4 |
=A1.new@m(NAME,age(BIRTHDAY):AGE) |
Use @m option to increase performance of big data handling. |
|
5 |
=file("D:\\txt_files\\data1.txt").import@t() |
Below is the file data1.txt:
|
|
6 |
=A5.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
If the SCORE value is null, the corresponding record won’t be generated.
|



Ø Generate from a pure table sequence
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE").i() |
Return a pure table sequence. |
|
2 |
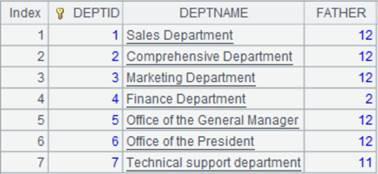
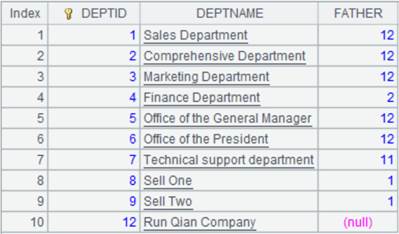
=A1.new@o(EID,NAME, #3:dept) |
With @o option, directly reference the unmodified old columns instead of generating new ones. |
|
3 |
=A2(1).NAME="aaa" |
Modifying column values results in the modification of source table; below is A2’s result after execution:
And A1’s result is as follows:
|


Ø Generate from multiple table sequences of the same order
|
|
A |
|
|
1 |
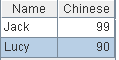
=create(Name,Chinese).record(["Jack",99,"Lucy",90]) |
|
|
2 |
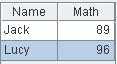
=create(Name,Math).record(["Jack",89,"Lucy",96]) |
|
|
3 |
=A1.new(Name:Name,Chinese:Chinese,A2(#).Math:Math) |
Use A2(#) to get the record from A2 in the same position.
|

Ø Perform the inverse operation:
|
|
A |
|
|
1 |
=demo.query("select * from SCORES ") |
Return a table sequence:
|
|
2 |
=A1.new(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
Perform iterative operation in a loop function to get cumulative total on SCORE values of records having same CLASS value and STUDENTID value, use the results as values of F1 column and return a new table sequence as follows:
|
|
3 |
=A1.new@z(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
Use @z option to perform an inverse operation:
|



Related function: