- esProc
- YModel
- ReportLite
- Official Website
- http://doc.raqsoft.com:8888/WEB-INF/layout/application.jsp1
- Overview
- Data Type
- Operators
- Mathematical Functions
- String Functions
- Date/Time Functions
- Sequence Functions
- Table Sequence Functions
- Loop Functions
- Functions for Associative Operations
- File-handling Functions
- Database Functions
- Cursor Functions
- Statements
- System- & interface-related Functions
- Cluster Computing Functions
- Chart-plotting Functions
- External Library Functions
- Composite-Table-Related Functions
- Remote-service-related functions
- Simple SQL
-
Functions
- #arg
- #@
- #c
- $(d)dql...
- $(db)sql;…
- ${macroExp}
- =expression
- >statement
- [a:b]
- @
- @x:…
- ~( i )
- A()
- A.( x,... )
- [a1,...an]
- abs()
- acos()
- acosh()
- aes()
- age()
- align()
- ali_open()
- ali_close()
- ali_query()
- alter()
- and()
- append()
- argpost
- array()
- asc()
- asin()
- asinh()
- atan()
- atanh()
- attach()
- avg()
- base64()
- between()
- bi()
- bits()
- bit1(x)
- bit1(x,y)
- blob()
- bool()
- break {a}
- C
- Cr()
- calc()
- call()
- call path/spl(…)
- calls path/spl(…)
- callx()
- cand()
- canvas()
- case()
- cdc_collect()
- cdc_merge()
- ceil()
- cellname()
- cgroups()
- ch.()
- channel()
- char()
- chardetect()
- charencode()
- chi_p()
- chi2inv()
- chn()
- clear()
- clipboard()
- close()
- cmp()
- cmps()
- cor()
- comabs()
- comangle()
- combin()
- comconj()
- comexp()
- comimage()
- commit()
- compair()
- complex()
- comreal()
- comsign()
- comstr()
- comunwrap()
- concat()
- conj()
- connect()
- contain()
- corskew()
- cos()
- cosh()
- count()
- cov()
- covm()
- create()
- cs.(x)
- cuboid()
- cum()
- cumulate()
- cursor()
- date()
- datederive()
- dateinterval()
- datetime()
- day()
- days()
- decimal()
- delete()
- deq()
- des()
- desede()
- derive()
- det()
- diff()
- digits()
- directory()
- dis()
- dism()
- dql()
- dup()
- dynadb.close()
- dynadb.execute()
- dyna_open()
- dynadb.query()
- dynadb.table()
- E()
- E()
- elapse()
- elasticnet()
- end s
- enum()
- env()
- eq()
- error()
- eval()
- es_close()
- es_delete()
- es_export()
- es_head()
- es_open()
- es_get()
- es_post()
- es_put()
- exec()
- execute()
- exists()
- exp()
- export()
- exportavro()
- eye()
- f@o(…)
- Faccrint()
- Faccrintm()
- fact()
- false
- Fcoupcd()
- Fcoups()
- Fdb()
- Fddb()
- Fdisc()
- Fduration()
- fetch()
- field()
- file()
- filename()
- fill()
- fillcons()
- fillfun()
- fillmthd()
- find()
- Fintrate()
- finv()
- Firr()
- fisher_p()
- fjoin()
- float()
- floor()
- Fmirr()
- fname()
- fno()
- Fnper()
- Fnpv()
- for
- fork
- format()
- Fpmt()
- Fprice()
- Frate()
- Freceived()
- freq ()
- Fsln()
- Fsyd()
- ftp_cd()
- ftp_open()
- ftp_close()
- ftp_dir()
- ftp_get()
- ftp_mget()
- ftp_mput()
- ftp_put()
- func()
- Fv()
- Fvdb()
- Fyield()
- get()
- gcd()
- gcs_bucket()
- gcs_close()
- gcs_copy()
- gcs_file()
- gcs_list()
- gcs_open()
- goto C
- group()
- groupc()
- groupi()
- groupn()
- groups()
- groupx()
- hash()
- hbase_close()
- hbase_cmp()
- hbase_filter()
- hbase_filterlist()
- hbase_get()
- hbase_open()
- hbase_rest()
- hbase_scan()
- hdfs_open()
- hdfs_close()
- hdfs_dir()
- hdfs_download()
- hdfs_exists()
- hdfs_file()
- hdfs_import()
- hdfs_upload()
- hdfs_write()
- hive_open()
- hive_close()
- hive_cursor()
- hive_db()
- hive_execute()
- hive_query()
- hive_table()
- hosts()
- hour()
- htmlparse()
- httpfile()
- I()
- i()
- icursor()
- icount()
- id()
- if
- if()
- ifa()
- ifdate()
- ifind()
- ifn()
- ifnumber()
- ifpure()
- ifr()
- ifstring()
- ift()
- iftime()
- ifv()
- ifx_close()
- ifx_conn()
- ifx_cursor()
- ifx_listfrag()
- ifx_savefrag()
- ifx_setfrag()
- ifx_takefrag()
- import()
- importavro()
- impute()
- index()
- inf()
- influx_close()
- influx_insert()
- influx_open()
- influx_query()
- influx2_close()
- influx2_delete()
- influx2_open()
- influx2_query()
- influx2_rest()
- insert()
- int()
- interval()
- inv()
- inverse()
- invoke()
- isalpha()
- isdigit()
- isect()
- iselect()
- islower()
- ismiss()
- ismissm()
- isolate()
- isupper()
- iterate()
- j()
- join()
- joinx()
- json()
- jvm()
- k()
- kafka_close()
- kafka_commit()
- kafka_offset()
- kafka_open()
- kafka_poll()
- kafka_send()
- key()
- keys()
- kmeans()
- lasso()
- lcm()
- left()
- len()
- lg()
- like()
- linefit()
- lineplan()
- ln()
- load()
- lock()
- long()
- lower()
- m()
- mae()
- makimamthd()
- max()
- maxp()
- mcumsum()
- md5()
- median()
- memory()
- merge()
- mergex()
- mfind()
- mi()
- mid()
- millisecond()
- min()
- minp()
- minute()
- mmean()
- mnorm()
- mode()
- modify()
- mongo_close()
- mongo_open()
- mongo_shell()
- month()
- movefile()
- movmthd()
- mul()
- mse()
- mstd()
- msum()
- mvp()
- n.f(x)
- name()
- new()
- news()
- next{a}
- nodes()
- norm()
- norminv()
- not()
- now()
- ntile()
- null
- number()
- numnorm()
- nvl()
- o()
- olap_close()
- olap_open()
- olap_query()
- ones()
- open()
- or()
- oss_bucket()
- oss_close()
- oss_copy()
- oss_file()
- oss_list()
- oss_open()
- output()
- p()
- pad()
- parse()
- paste()
- pca()
- pchipmthd()
- pdate()
- pearson()
- penum()
- periods()
- permut()
- pfind()
- pi()
- pivot()
- pjoin()
- pls()
- pmax()
- pmin()
- polyfit()
- pos()
- power()
- prior()
- proc()
- product()
- proportion()
- property()
- pseg()
- pselect()
- pseudo()
- psort()
- ptop()
- push()
- Qconnect()
- Qdirectory()
- Qenv()
- Qfile()
- Qload()
- Qlock()
- Qmove()
- query()
- r.(x,...)
- r.F
- r.F=x
- r2dbc_close()
- r2dbc_exec()
- r2dbc_open()
- r2dbc_query()
- rand()
- rands()
- range()
- rank()
- ranki()
- rankm()
- ranks()
- read()
- record()
- redis_close()
- redis_command()
- redis_open()
- regex()
- register()
- remainder()
- rename()
- replace()
- report_config()
- report_export()
- report_open()
- report_run()
- reportlite_config()
- reportlite_export()
- reportlite_open()
- reportlite_run()
- reset()
- result
- return xi
- rgb()
- ridge()
- right()
- rmmiss()
- rmmissdim()
- rollback()
- round()
- rsa()
- run()
- rvs()
- s3_bucket()
- s3_close()
- s3_copy()
- s3_file()
- s3_list()
- s3_open()
- sap_client()
- sap_close()
- sap_cursor()
- sap_execute()
- sap_getparam()
- sap_table()
- savepoint()
- sbs()
- scriptsave()
- se()
- second()
- segp()
- select()
- seq()
- sert()
- setenum()
- sf_close()
- sf_open()
- sf_query()
- sf_wsdlclose()
- sf_wsdlopen()
- sf_wsdlquery()
- sf_wsdlview()
- sg()
- shift()
- sign()
- sin()
- sinh()
- size()
- skew()
- skip()
- sleep()
- smooth()
- sort()
- sortx()
- spark_open()
- spark_close()
- spark_cursor()
- spark_query()
- spark_read()
- spearman()
- splinemthd()
- split()
- splserver()
- sqlparse()
- sqltranslate()
- substr()
- stax_close()
- stax_open()
- stax_cursor()
- stax_query()
- sqrt()
- step()
- string()
- structure
- sum()
- svm()
- swap()
- switch()
- syncfile(hs,p)
- system()
- T()
- tarcorskew()
- tan()
- tanh()
- time()
- tinv()
- to()
- top()
- total()
- transpose()
- trim()
- true
- try
- ttest_p()
- typeof(x)
- union()
- update()
- upper()
- urlencode()
- uuid()
- v()
- var()
- var(V)
- var(x)
- was_bucket()
- was_close()
- was_copy()
- was_file()
- was_list()
- was_open()
- web_crawl()
- webhdfs()
- webhdfs_file()
- words()
- workday()
- workdays()
- write()
- ws_call()
- ws_client()
- xjoin()
- xjoinx()
- xlscell()
- xlsclose()
- xlsexport()
- xlsimport()
- xlsmove()
- xlsopen()
- xlswrite()
- xml()
- xor()
- xunion()
- year()
- ym2_close()
- ym2_env()
- ym2_mcfload()
- ym2_model()
- ym2_pcfload()
- ym2_pcfsave()
- ym2_predict()
- ym2_result()
- zeros()
- zip()
- zip_add()
- zip_close()
- zip_compress()
- zip_del()
- zip_encrypt()
- zip_extract()
- zip_open()
- Intersection of sequences
- Comparison operation
- Hexadecimal long integer
- Modulus
- Concatenation of sequences
- Arithmetic operations
- Compound assignment
- String
- String concatenation
- Alignment arithmetic operations
- Difference between sequences
- Union of sequences
- Multiplication of sequences
- Table sequence constant
- Record constant
- XOR-enabled sequence
- The writing rules for expression x in loop functions
- Batch Computation
- Identifier
- Opposite Number
- Empty Sequence
- Assignment
- Value Computation and Assignment
- Escape Character
- Logical Operations
- Long Integer
- Cell type
- Code block type
- Chart Elements
A.bi()
Description:
Split a low-frequency categorical enumerated sequence variable that contains a number of categories not greater than 6 into multiple binary variables during modeling.
Syntax:
|
A.bi() |
During modeling, split low-frequency categorical enumerated variable A that contains a number of categories not greater than 6 into multiple binary variables, and return a binary sequence consisting of a table sequence of splitting result and a sequence of splitting process records Rec. |
|
A.bi@r(Rec) |
During scoring, split low-frequency categorical enumerated variable A that contains a number of categories not greater than 6 into multiple binary variables according to the sequence of splitting process records Rec, and return result as a table sequence. |
Note:
The external library function (See External Library Guide) splits a low-frequency categorical enumerated sequence variable that contains a number of categories not greater than 6 into multiple binary variables during modeling.
Parameter:
|
A |
A sequence, which is a low-frequency categorical enumerated variable that contains a number of categories no greater than 6. |
|
Rec |
A sequence of splitting process records. |
Return value:
Sequence/Table sequence
Example:
|
|
A |
|
|
1 |
=T("D://house_prices_train.csv") |
|
|
2 |
=A1.(MSZoning) |
A variable containing a number of categories no greater than 6. |
|
3 |
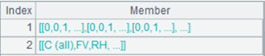
=A2.bi() |
A3(1) A table sequence of splitting result; A3(2) A sequence of splitting process records Rec. |
|
4 |
=A2.bi@r(A3(2)) |
Split A2’s variable into multiple variables according to A3’s sequence of splitting process records Rec. |