T.cursor(x:C,…;wi,...;mcs)
Description:
Synchronously segment an entity table/in-memory table/multizone composite table according to a multicursor and return a multicursor.
Syntax:
T.cursor(x:C,…;wi,...;mcs)
Note:
The function synchronously segments entity table/in-memory table/multizone composite table T according to multicursor mcs, during which T’s first field and mcs’s first field will be matched, and returns a multicursor. When T is a multizone composite table, merge zone tables by their dimensions.
Parameter:
|
T |
An entity table/in-memory table/multizone composite table; should not be composite table stored in row-wise. |
|
x |
An expression. |
|
C |
The column alias. |
|
wi |
Filtering condition; retrieve the whole set when this parameter is absent; separate multiple conditions by comma(s) and their relationships are AND. Besides regular filtering expressions, you can also use the following five types of syntax in a filtering condition, where K is a field in the entity table: 1.K=w w usually uses expression Ti.find(K) or Ti.pfind(K), where Ti is a table sequence. When value of w is null or false, the corresponding record in the entity table will be filtered away; when w is expression Ti.find(K) and the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K; when w is expression Ti.pfind(K) and the to-be-selected fields C,... contain K, sequence numbers of K values in Ti will be assigned to K. 2.(K1=w1,…Ki=wi,w) Ki=wi is an assignment expression. Generally, parameter wi can use expression Ti.find(Ki) or Ti.pfind(K), where Ti is a table sequence; when wi is expression Ti.find(Ki) and the to-be-selected fields C,... contain Ki, Ti’s referencing field will be assigned to Ki correspondingly; when wi is expression Ti.pfind(Ki) and the to-be-selected fields C,... contain Ki, sequence numbers of Ki values in Ti will be assigned to Ki. w is a filter expression; you can reference Ki in w. 3.K:Ti Ti is a table sequence. Compare Ki value in the entity table with key values of Ti and discard records whose Ki value does not match; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K. 4.K:Ti:null Filter away all records that satisfy K: Ti. 5.K:Ti:# Locate records according to sequence numbers, compare sequence numbers of records in table sequence Ti according to the entity table’s K values, and discard non-matching records; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K.
|
|
mcs |
A multicursor generated from an entity table |
Option:
|
@k |
Perform matching using the multicursor’s first field of the key |
|
@v |
Generate a pure table sequence-based column-wise cursor, which has higher performance than regular cursors |
|
@x |
Automatically close the entity table after data is fetched from the cursor |
|
@g |
When T is a multizone composite table and if group() operation will be executed on the result cursor, use this option to speed up the computation. |
|
@w |
Used on a multizone composite table with the update mark; Perform update merge; when zone tables share a same key value, ignore the record contained in the zone table with a smaller number; segmentation is performed according to the way zone table 1 is split; Handle the update mark and do not return records with a deletion mark to the cursor; but if the key value of a record with the deletion mark is unique in the multizone composite table, just retain it; This option enables retrieving key field(s) as well as the deletion mark field, if there is one, forcefully |
|
@p |
Perform MERGE by the first field when parameter T is a multizone composite table. |
Return value:
Multicursor
Example:
|
|
A |
|
|
1 |
for 100 |
|
|
2 |
Return a table sequence:
|
|
|
3 |
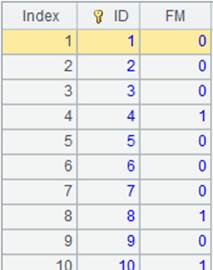
=to(10000).new(#:k1,rand(10000):c2).sort@o(k1) |
Return a table sequence:
|
|
4 |
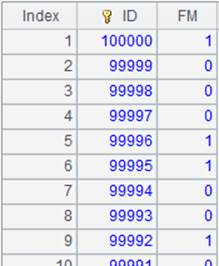
=to(10000).new(#:k1,rand()*1000:c3).sort@o(k1) |
Return a table sequence:
|
|
5 |
=A2.cursor() |
Return a cursor. |
|
6 |
=A3.cursor() |
Return a cursor. |
|
7 |
=A4.cursor() |
Return a cursor. |
|
8 |
=file("D:\\cs1.ctx") |
Generate a composite table file. |
|
9 |
=A8.create(#k1,c1) |
Create the composite table’s base table. |
|
10 |
=A9.append(A5) |
Append data in A5’s cursor to the base table. |
|
11 |
=A9.attach(table1,c2) |
Create attached table table1 on base table. |
|
12 |
=A11.append(A6) |
Append data in A6’s cursor to table1. |
|
13 |
=A11.cursor@m(;;2) |
Segment the attached table and return a multicursor. |
|
14 |
=A9.attach(table2,c3) |
Create attached table table2 on base table. |
|
15 |
=A14.append(A7) |
Append data in A7’s cursor to table2. |
|
16 |
=A14.cursor@v(;;A13) |
Segment table2 according to A13’s multicursor. |

When T is a multizone composite table:
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME from employee") |
|
|
2 |
=file("emp.ctx") |
Generate a composite table file. |
|
3 |
=A2.create@y(#EID,NAME) |
Create the composite table’s base table. |
|
4 |
=A3.append(A1) |
Append data in A1’s cursor to the composite table’s base table. |
|
5 |
=A4.cursor@m(;;3) |
Generate a multicursor having 3 subcursors according to the composite table. |
|
6 |
=connect("demo").cursor("select EID,NAME,GENDER,SALARY from employee") |
|
|
7 |
=file("emp.ctx":[1,2]) |
Generate a homo-name files group. |
|
8 |
=A7.create@y(#EID,NAME,GENDER,SALARY;if(GENDER=="F",1,2)) |
Create a multizone composite table. |
|
9 |
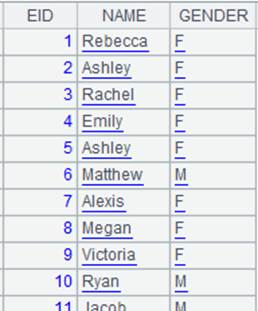
=A8.append@x(A6) |
Append data in A6’s cursor to the multizone composite table and its content is as follows:
|
|
10 |
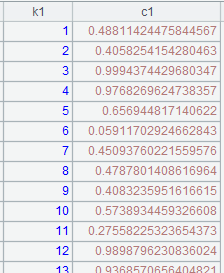
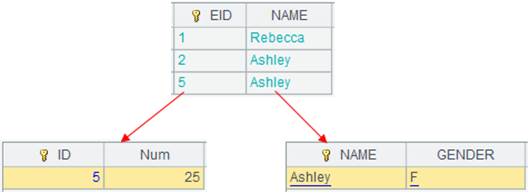
=A8.cursor(EID,NAME,GENDER,SALARY;SALARY>5000;A5) |
Split A8’s multizone composite table synchronously according to A5’s multicursor, perform merge by default and return a cursor as follows:
We can see that data in two zone tables are merged by their dimensions. |
Use special types of filtering conditions:
|
|
A |
|
|
1 |
=file("emp.ctx") |
|
|
2 |
=A1.open() |
Open the composite table file. |
|
3 |
=A2.import() |
As no parameters are present, return all data in the entity table.
|
|
4 |
=file("emp1.ctx").open().cursor@m(;;2) |
Return a multicursor. |
|
5 |
=5.new(~:ID,~*~:Num).keys(ID) |
Generate a table sequence using ID as the key.
|
|
6 |
=A2.cursor(EID,NAME;EID=A5.find(EID);A4) |
Use K=w filtering mode; in this case w is Ti.find(K) and entity table records making EID=A4.find(EID) get null or false are discarded; EID is the selected field, to which table sequence A5’s referencing field is assigned.
|
|
7 |
=A2.cursor(EID,NAME;EID=A5.pfind(EID);A4) |
Use K=w filtering mode; in this case w is Ti.pfind(K) and entity table records making EID=A4.pfind(EID) get null or false are discarded; EID is the selected field, to which its sequence numbers in table sequence A5 are assigned.
|
|
8 |
=A2.cursor(EID,NAME;EID:A5;A4) |
Use K:Ti filtering mode; compare the entity table’s EID values with the table sequence’s key values and discard entity table records that cannot match.
|
|
9 |
=A2.cursor(NAME,SALARY;EID:A5;A4) |
This is a case where K isn’t selected; EID isn’t the selected field, so only filtering is performed.
|
|
10 |
=A2.cursor(EID,NAME;EID:A5:null;A4) |
Use K:Ti:null filtering mode; compare the entity table’s EID values with the table sequence’s key values and discard entity table records that can match.
|
|
11 |
=A2.cursor(EID,NAME;EID:A5:#;A4) |
Use K:Ti:# filtering mode; compare with sequence numbers of table sequence’s records according to the entity table’s EID values, and discard records that cannot match.
|
|
12 |
=connect("demo").query("select top 2 NAME,GENDER from employee").keys(NAME) |
Return a table sequence using NAME as the key.
|
|
13 |
=A2.cursor(EID,NAME;(EID=A5.find(EID),NAME=A12.find(NAME),EID!=null &&NAME!=null);A4) |
Use (K1=w1,…Ki=wi,w) filtering mode; return records that meet all conditions.
|
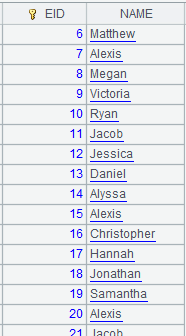
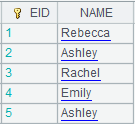
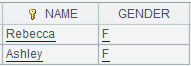
Use @w option to recognize update mark:
|
|
A |
|
|
1 |
=connect("demo").cursor("select EID,NAME from employee") |
|
|
2 |
=file("e-mcs.ctx") |
Generate a composite table file. |
|
3 |
=A2.create@y(#EID,NAME) |
Create the composite table’s base table. |
|
4 |
=A3.append(A1) |
Append cursor A1’s data to the composite table’s base table. |
|
5 |
=A4.cursor@m(;;3) |
Create a 3-subcursor multicursor based on the composite table. |
|
6 |
=connect("demo").cursor("select EID,NAME,GENDER from employee") |
|
|
7 |
=A6.derive(:Defiled) |
|
|
8 |
=A7.new(EID,Defiled,NAME,GENDER) |
Return a cursor whose content is as follows:
|
|
9 |
=file("ecd.ctx":[1,2]) |
Define a homo-name files group: 1.ec.ctx and 2.ec.ctx. |
|
10 |
=A9.create@yd(#EID,Defiled,NAME,GENDER;if(GENDER=="F",1,2)) |
Create a multizone composite table, set EID as its key, use @d option to make Defiled as the update mark field, and put records where GENDER is F to 1.ed.ctx and the other records to 2.ed.ctx. |
|
11 |
=A10.append@ix(A8) |
Append cursor A8’s data to A10’s multizone composite table. |
|
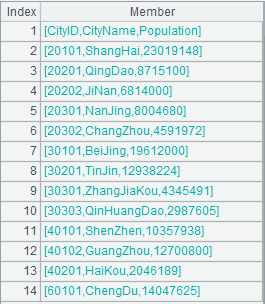
12 |
=create(EID,Defiled,NAME,GENDER).record([0,true,,,1,true,,, 2,false,"BBB","F"]) |
Return a table sequence whose content is as follows:
|
|
13 |
=file("ecd.ctx":[3]) |
|
|
14 |
=A13.create@yd(#EID,Defiled,NAME,GENDER;3) |
Add a new zone table 3.ecd.ctx, where Defiled is the update mark field. |
|
15 |
=A14.append@i(A12) |
Append table sequence A12’s records to zone table 3.ecd.ctx. |
|
16 |
=file("ecd.ctx":[1,2,3]).open() |
|
|
17 |
=A16.cursor(;;A5) |
Split A16’s multizone composite table synchronously according to multicursor A5, and return a multicursor. |
|
18 |
=A17.fetch() |
Fetch data from cursor A17.
|
|
19 |
=A16.cursor@w(;;A5) |
Use @w option to split multizone composite table ecd.ctx into multiple segments according to multicursor A5, return the segmented composite table as a multicursor, recognize the update mark – that is: won’t return the record whose EID value is 1 and whose update mark is true (meaning to-be-deleted) to the result multicursor; Modify the record whose EID value is 2 and whose update mark is false (meaning to-be-modified); Retain the record whose primary key value is unique though it is marked by a deletion mark – that is, return the record whose EID value is 0 to the result multicursor. |
|
20 |
=A19.fetch() |
Fetch data from cursor A19.
|