cs.pjoin ()
Description:
Attach the join-key-based association with another cursor or a record sequence to a cursor and return the original cursor.
cs.pjoin(K:..,x:F,…; csi/Ai:z,Ki:…,xi:Fi,…; …) .
Note:
The function attaches a computation to cursor cs, which associates cursor/record sequence cs and cursor/record sequence csi through the join key and forms a sequence consisting of x:F,… and xi:Fi,… to return to the original cursor.
cs and csi can be cursors or record sequences, and both should be ordered by the join key. By default, x:F,… involves all fields of cs.
When relationship between cs and csi is one-to-many, xi is an aggregate expression.
When relationship between cs and csi is many-to-one, records of csi/Ai will appear repeatedly in the result set.
Parameter z specifies the join type. It can be absent or null. Perform an inner join when z is absent, and a left join when z is null; and only retain records of cs that cannot find matches when z is null and both parameters xi:Fi are absent.
When both cs and csi are composite table cursors, the latter will by default follows the former to filter blocks. The process is this: retrieve data from cs and then retrieve data from csi according to the value range of the retrieved cs data. The method filters csi and helps to increase computing efficiency.
This is a delayed function.
Parameter:
|
cs |
A cursor /record sequence. |
|
K |
cs’s join key. |
|
x |
cs’s expression. |
|
F |
Field name corresponding to expression x. |
|
csi |
A cursor/composite table cursor/record sequence. |
|
z |
Join type. |
|
Ki |
Join key of csc:/Ai. |
|
xi |
Expression of csc:/Ai. |
|
Fi |
Field name corresponding to expression xi. |
Return value:
Cursor
Option:
|
@r |
Use this option to perform block filtering on cs1 according to cs and increase efficiency when both cs and cs1, cs2,...csi are table cursors and cs1 has a relatively small amount of data. |
|
@f |
Enable full join while ignoring parameter z; do not work with @r option. |
|
@t |
Use this option to make the time key the join key when both cs and csi are composite table-based cursors and csi has the time key; do not work with @f option. |
Example:
Homo-dimension table join:
|
|
A |
|
|
1 |
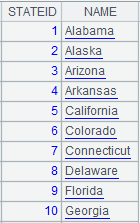
=connect("demo").cursor("select STATEID,NAME from STATENAME").sortx(STATEID) |
Return a cursor ordered by STATEID; below is the data:
|
|
2 |
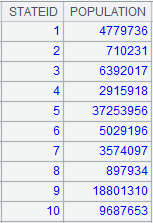
=connect("demo").query("select STATEID,POPULATION from STATEINFO").sort(STATEID) |
Return a record sequence ordered by STATEID.
|
|
3 |
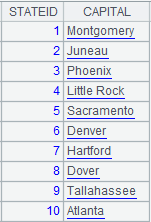
=connect("demo").query("select STATEID,CAPITAL from STATECAPITAL").sort(STATEID) |
Return a record sequence ordered by STATEID.
|
|
4 |
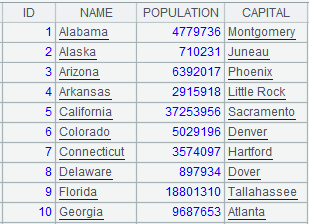
=A1.pjoin(STATEID,STATEID:ID,NAME;A2,STATEID,POPULATION;A3,STATEID,CAPITAL) |
Attach a computation to cursor A1, which associates cursor A1 and record sequences A2 and A3 through join key STATEID, renames STATEID field ID and returns the original cursor A1; below is data in cursor A1 after the attached computation is executed on the cursor A1:
|
When A and Ai has a one-to-many relationship:
|
|
A |
|
|
1 |
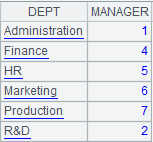
=demo.cursor("select top 6 DEPT,MANAGER from DEPARTMENT") |
Return a cursor; below is the content:
|
|
2 |
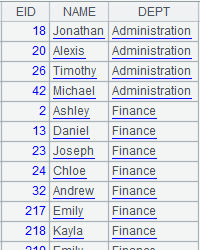
=demo.cursor("select EID,NAME,DEPT from EMPLOYEE").sortx(DEPT) |
Return a cursor; below is the content:
|
|
3 |
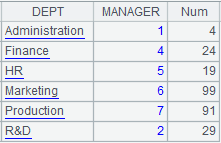
=A1.pjoin(DEPT;A2,DEPT,count(EID):Num) |
Relationship between A1 and A2 is one-to-many; attach a computation to cursor A1, which associates cursors A1 and A2 through DEPT, finds the number of EID values under each DEPT value and makes the computing result a new filed v and returns the original cursor A1; below is data in cursor A1 after the attached computation is executed on the cursor A1:
|
When A and Ai has a many-to-one relationship:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
Return a cursor; below is the content:
|
|
2 |
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
Return a cursor; below is the content:
|
|
3 |
=A1.pjoin(STATEID,CID,NAME,POPULATION;A2,STATEID,CAPITAL ) |
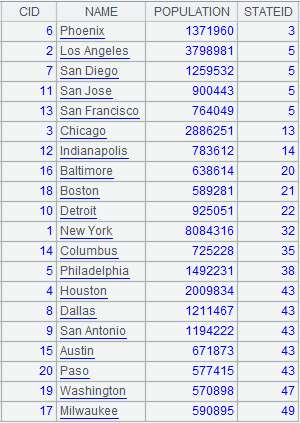
Relationship between A1 and A2 is many-to-one; attach a computation to cursor A1, which associates them through STATEID, during which A2’s field values appear repeatedly in the result set and returns the original cursor A1; below is data in cursor A1 after the attached computation is executed on the cursor A1:
|

Full join:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
Return a cursor; below is the content:
|
|
2 |
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
Return a cursor; below is the content:
|
|
3 |
=A1.pjoin@f(STATEID,CID,NAME,POPULATION;A2,STATEID,CAPITAL ) |
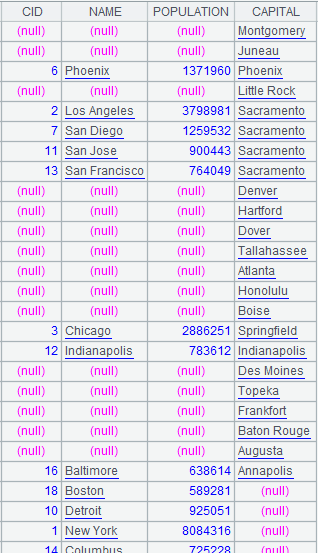
Attach a computation to cursor A1, which, uses @f to perform full join, during which non-matching field values of records are displayed as nulls and returns the original cursor A1; below is data in cursor A1 after the attached computation is executed on the cursor A1:
|
Method 1 for left join:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
Return a cursor; below is the content:
|
|
2 |
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
Return a cursor; below is the content:
|
|
3 |
=A1.pjoin(STATEID,CID,NAME,POPULATION;A2:null,STATEID,CAPITAL ) |
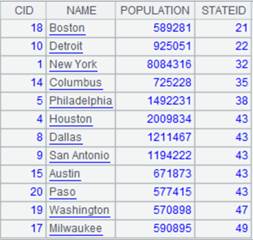
Attach a computation to cursor A1. As parameter z is null, perform left join to list all records of A1 while displaying non-matching field values in A2 as nulls and return the original cursor A1; below is data in cursor A1 after the attached computation is executed on the cursor A1:
|

Method 2 for left join:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
Return a cursor; below is the content:
|
|
2 |
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
Return a cursor; below is the content:
|
|
3 |
=A1.pjoin(STATEID;A2:null,STATEID) |
Attach a computation to cursor A1. Parameter z is null and parameters xi:Fi are absent, so only the non-matching records of A1 are retained and return the original cursor A1; below is data in cursor A1 after the attached computation is executed on the cursor A1:
|
Join between composite table cursor:
|
|
A |
|
|
1 |
=file("DEPARTMENT.ctx").open().cursor() |
Return a composite table cursor; below is the content:
|
|
2 |
=file("EMPLOYEE.ctx").open().cursor() |
Return a composite table cursor; below is the content:
|
|
3 |
=A1.pjoin@r(DEPT;A2,DEPT,count(EID):Num) |
The relationship between A1 and A2 is one-to-many; Attach a computation to associate them according to DEPT, find the number of EID values under each DEPT and use the results to form Num field while using @r option and return the original cursor A1; below is data in cursor A1 after the attached computation is executed on the cursor A1:
|
When csi has the time key:
|
|
A |
|
|
1 |
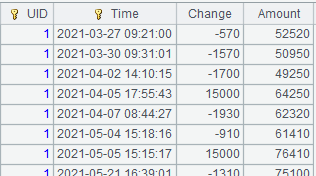
=file("transaction.btx").cursor@b() |
Return a cursor ordered by UID and Time. |
|
2 |
=file("trap.ctx") |
|
|
3 |
=A2.create@ty(#UID,#Time,Change,Amount) |
Create a composite table where UID is the basic key and Time is the time key. |
|
4 |
=A3.append@i(A1) |
Append cursor A1’s records to composite table file trap.ctx. |
|
5 |
=A4.cursor() |
Return a composite table-based cursor, whose content is as follows:
… …
|
|
6 |
=demo.cursor("select top 5 EID, NAME, DEPT from EMPLOYEE ") |
Return a cursor. |
|
7 |
=file("ep.ctx") |
|
|
8 |
=A7.create@y(#EID, NAME, DEPT) |
Generate a composite table and set EID as the key. |
|
9 |
=A8.append@i(A6) |
Append cursor A6’s records to composite table file ep.ctx. |
|
10 |
=A9.cursor() |
Return a composite table-based cursor, whose content is as follows:
|
|
11 |
=A10.pjoin@t(EID:date(2021,5,1),NAME,DEPT;A5,UID:Time,UID,Time,Change,Amount) |
Attach a computation to cusor A10. Join two composite table-based cursors: A5 and A10, as composite table trap.ctx has the time key, use @t option to return the record where UID is equal to ID and that has the largest Time value before 2021-05-01, and return the original cursor A10: |
|
12 |
=A10.fetch() |
Fetch data from cursor A10:
|