A.derive()
Description:
Add one or more fields to a table sequence or a record sequence.
Syntax:
A.derive(xi:Fi,…)
Note:
The function adds Fi,… field(s) to table sequence/record sequence A, traverses each record of A, assigns each Fi with value xi and returns a new table sequence consisting of the original fields and the new field(s) Fi.
Parameter:
|
Fi |
Field name, which shouldn’t have the same name as any of the original fields in A |
|
xi |
Expression, whose results are used as the values of the derived fields |
|
A |
A table sequence/record sequence |
Option:
|
@m |
Use parallel algorithm to handle data-intensive or computation-intensive tasks to enhance performance; and no definite order for the records in the result set |
|
@i |
Won’t generate a record if there is expression xi and its result is null |
|
@x(…;n) |
Unfold original fields whose values are records into n levels; default of n is 2 |
|
@o |
When parameter A is a pure table sequence, add columns directly to it instead of generating a new table sequence |
|
@z |
Perform the inverse operation; only applies to non-pure sequences |
Return value:
Table sequence
Example:
|
|
A |
|
|
1 |
=demo.query("select NAME,BIRTHDAY,HIREDATE from EMPLOYEE") |
|
|
2 |
=A1.derive(interval@y(BIRTHDAY, HIREDATE):EntryAge, age(HIREDATE):WorkAge) |
|
|
3 |
=A1.derive@m(age(HIREDATE):WorkAge) |
Use the @m option to increase performance of big data handling. |
|
4 |
=file("D:\\txt_files\\data1.txt").import@t() |
Below is the file data1.txt:
|
|
5 |
=A4.derive@i(SCORE:score_not_null) |
If the SCORE value is null, the corresponding record won’t be generated.
|
|
6 |
=demo.query("select * from DEPARTMENT") |
|
|
7 |
=demo.query("select NAME,GENDER,DEPT,SALARY from EMPLOYEE") |
|
|
8 |
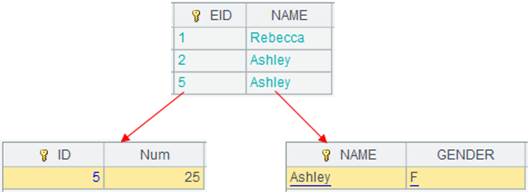
>A7.switch(DEPT,A6:DEPT) |
Switch values of DEPT of A7’s table over with corresponding records. |
|
9 |
=A7.derive(SALARY*5:BONUS) |
Add a new field:BONUS.
|
|
10 |
=A7.derive@x(SALARY*5:BONUS) |
Use @x option to unfold the DEPT field whose values are records; the default unfolding levels are 2.
|
|
11 |
=demo.query("select NAME,BIRTHDAY,HIREDATE from EMPLOYEE").i() |
Return a pure table sequence. |
|
12 |
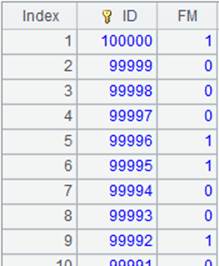
=A11.derive@o(age(HIREDATE):WorkAge) |
Add the new column directly to the original table sequence rather than generating a new one; here the function returns same result as A11. Following is the result:
|





Perform the inverse operation:
|
|
A |
|
|
1 |
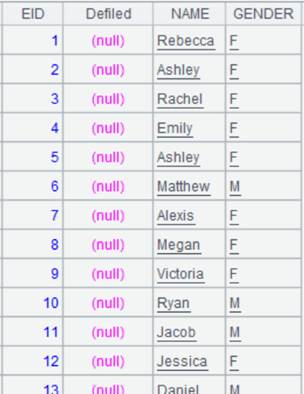
=demo.query("select * from SCORES ") |
Return a table sequence:
|
|
2 |
=A1.derive(cum(SCORE;CLASS,STUDENTID):F1) |
Add F1 field and perform iterative operation in a loop function to cumulatively sum SCORE values in records having same CLASS and STUDENTID values, and use the result sums as F1 values:
|
|
3 |
=A1.derive@z(cum(SCORE;CLASS,STUDENTID):F1) |
Use @z option to perform the inverse operation:
|



Note:
The difference between new() and derive(): The new() constructs a new table sequence without changing the original one. By comparison, the derive() copies the original fields and then adds new fields.