words()
Here’s how to use words() functions.
s. words()
Description:
Extract English words from a string.
Syntax:
s.words()
Note:
The function returns a string sequence consisting of English words extracted from string s while other characters are ignored.
Option:
|
@d |
Select digits from string s |
|
@a |
Select both English words and substrings of digits from string s |
|
@w |
Extract all characters: a string in Chinese /a sign will be extracted as individual characters and a string of English letters/a number as words |
|
@p |
Use with @w option to identify the beginning part of a number or a datetime data as a part of it |
|
@i |
Treat English letters in a row and continuous English letters plus digits as a whole |
Parameter:
|
s |
A string |
Return value:
A sequence of strings
Example:
|
|
A |
|
|
1 |
4,23,a,test?my_file 57 |
|
|
2 |
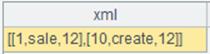
=A1.words() |
Extract English words form the string:
|
|
3 |
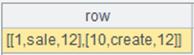
=A1.words@d() |
Extract digits form the string:
|
|
4 |
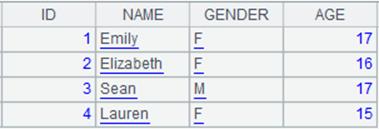
=A1.words@a() |
Extract English words and digits form the string:
|
|
abc你123好吗#?df34 |
|
|
|
6 |
=A5.words@w() |
|
|
7 |
=A5.words@i() |
Extract English letters in a row and continuous English letters plus digits as a whole:
|
|
8 |
hi*-10hello2020-01-01go3.1415926 |
|
|
9 |
=A8.words@w() |
|
|
10 |
=A8.words@wp() |
The beginning part of a digit or date is recognized as a part of a whole number or date data, like one in -10, 2020-01-01 and 3.1415926, according to the data type:
|