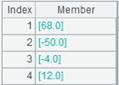
join()
Here’s how to use join() functions.
join()
Description:
Join multiple sequences together.
Syntax:
join(Ai:Fi,xj,..;…)
Note:
The function joins multiple sequences of Ai according to the condition that the value of join field/expression xj is equal to x1, and generates a table sequence whose fields are Fi,…. which are assigned with corresponding records of the original record sequences Ai. If xj is omitted, then use the key of Ai. An omitted xj won’t be matched.
Parameter:
|
Fi |
Field name of the resulting table sequence |
|
Ai |
Sequences or record sequences to be joined |
|
xj |
Join field/ expression |
Option:
|
@f |
Full join; if no matching records are found, then use nulls to correspond |
|
@1 |
Left join; it is the number "1" instead of the letter "l" |
|
@m |
If all Ai are ordered against xj, then use merge operation to compute |
|
@p |
Perform a join according to positions while ignoring parameter xj |
|
@i |
Used only to filter A1 and ignore parameter Fi; do not work with @f@1 options |
|
@d |
Used only to filter A1 to retain records that cannot be found and ignore parameter Fi; do not work with @f@1 options |
Return value:
Table sequence
Example:
|
|
A |
|
|
1 |
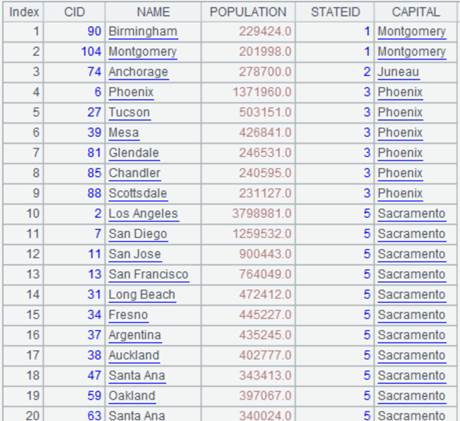
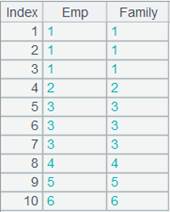
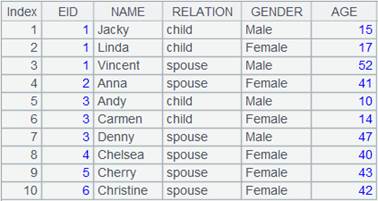
=demo.query("select top 3 EID,NAME from EMPLOYEE").keys(EID) |
|
|
2 |
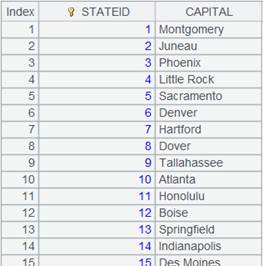
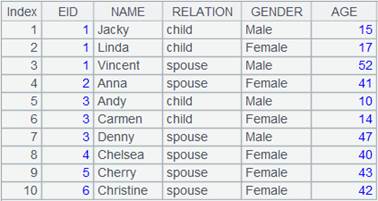
=demo.query("select top 3 EID,NAME from FAMILY").keys(EID) |
|
|
3 |
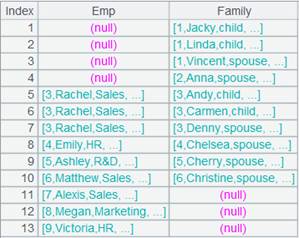
=join(A1:Employee,EID;A2:Familymembers,EID) |
A normal join that discards non-matching items; every field is a ref field pointing to the corresponding record in the original table sequence. |
|
4 |
=join@f(A1:Employee,EID;A2:Familymembers,EID) |
A full join that uses nulls to represent non-matching records. |
|
5 |
=join@1(A1:Employee,EID;A2:Familymembers,EID) |
A left join that uses the first table sequence as the basis and that uses nulls to correspond when no matching records can be found. |
|
6 |
=join@m(A1:Employee,EID;A2:Familymembers,EID) |
If all the join fields are in the same order, then merge operation can be used to compute; if they are not in the same order, then error will occur. |
|
7 |
=join@p(A1:Employee;A2:Familymembers) |
|
|
8 |
=join(A1:Employee;A2:Familymembers) |
|
|
9 |
=join(A1:Employee1;A2:Familymembers1) |
|
|
10 |
=join(A8:Employee2;A9:Familymembers2) |
|
|
11 |
=join@i(A1;A2) |
Filter A1 to retain records that can be found. |
|
12 |
=join@d(A1;A2) |
Filter A1 to retain records that cannot be found. |





Related function:
P.j oin()
Description:
A foreign-key-style join between table sequences/record sequences, or a table sequence and a record sequence.
Syntax:
P.join(C:.,T:K,x:F,…; …;…)
Note:
The function matches C field of table sequence/record sequence P with the key of table sequence/record sequence T to find the desired records. Add an F field represented by x, which is T’s field expression, to P to generate a new table sequence.
K can be omitted or represented by #. When omitted, K is T’s key by default; when written as #, K is the ordinal number of a record of table T, which means foreign key numberization. Simply put, primary key values of the dimension table are natural numbers starting from 1, which are row numbers corresponding to table records. In this case, we can directly locate dimension table records according to key values by row numbers. This helps speed up association with the dimension table and increase performance.
If there is an F field in P, just modify the existing field of P. Use the latest time calculated through now() when time key value is not specified.
Option:
|
@i |
Delete a record with a non-matching foreign key value; by default, a non-matching record will be represented by null. If parameters x:F are omitted, perform the filtering purely over parameter P |
|
@d |
If parameters x:F are absent, delete records matching the foreign key and perform the filtering operation only over table sequence/record sequence P |
|
@m |
Enable a merge join when P is ordered by C and T is ordered by K |
Parameter:
|
P |
Table sequence/record sequence |
|
C |
P’s foreign key; separate multiple fields in a composite key with the colon |
|
T |
Table sequence/record sequence |
|
K |
T’s key |
|
x |
T’s field expression, which can be represented by ~ and #; the pound sign # represents the ordinal number of a record in T; record the ordinal number as null if a record doesn’t exist in T |
|
F |
Field name in expression x |
Return value:
A table sequence/record sequence
Example:
|
|
A |
|
|
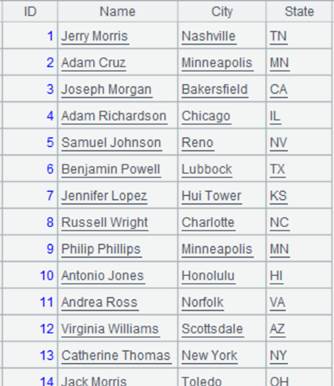
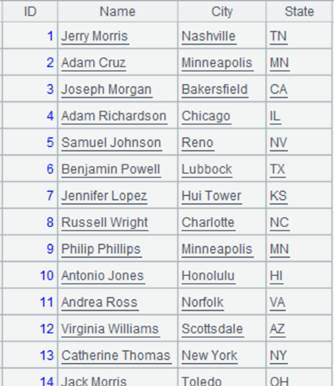
1 |
=connect("demo").query("SELECT * FROM CITIES") |
Data of CITIES table:
|
|
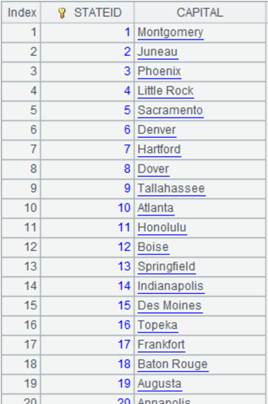
2 |
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID) |
Data of STATECAPITAL table:
|
|
3 |
=A1.join(STATEID,A2,CAPITAL) |
Associate CITIES table and STATECAPITAL table through the foreign key, during which default parameter K is STATEID, the key of STATECAPTITAL, and add STATECAPITAL’s CAPITAL field to CITIES to generate a new table sequence.
|
|
4 |
=A1.join(STATEID,A2:#,CAPITAL) |
As STATEID field values are natural numbers starting from 1, which correspond to ordinal numbers of records in STATECPATITAL table, parameter K is written as # to use those ordinal numbers in order to increae efficiency; return same result as A3. |
|
5 |
=A1.join@i(STATEID,A2,CAPITAL) |
@i option enables deleting records with non-matching foreign key values; write them as nulls if there isn’t the option.
|
|
6 |
=A1.join@i(STATEID,A2) |
@i option enables filtering CITIES table only when parameters x:F are absent.
|
|
7 |
=A1.join@d(STATEID,A2) |
With @d option and when parameters x:F are absent, delete records where foreign key values are matching and perform filtering only on CITIES table.
|
|
8 |
=A1.join(STATEID,A2,abc) |
Write records where values of parameter x cannot be found in A2 as nulls.
|
|
9 |
=A1.join(STATEID,A2,CAPITAL:NAME) |
Modify the existing fields when NAME field already exists in CITIES table.
|




Perform the JOIN through MERGE method:
|
|
A |
|
|
1 |
=connect("demo").query("SELECT * FROM CITIES").sort(STATEID) |
Below is data of CITIES table:
|
|
2 |
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID).sort(STATEID) |
Below is data of STATECAPITAL table:
|
|
3 |
=A1.join@m(STATEID,A2,CAPITAL) |
As CITIES table is ordered by STATEID and STATECAPITAL table is ordered by parameter K and with @m option being present, we can use MERGE method to compute.
|
ch.jo in()
Description:
Attach a foreign-key-style join with a record sequence to a channel and return the original channel.
Syntax:
ch.join(C:.,T:K,x:F,…; …;…)
Note:
The function attaches a computation to channel ch, which will use the key of table sequence/record sequence T to match the channel’s C,… field, compute T’s field expression x and make the results values of field F and join the field to ch, and return the original channel ch.
K can be omitted or represented by #. When omitted, K is T’s key by default; when written as #, K is the ordinal number of a record of table T, which means foreign key numberization. Simply put, primary key values of the dimension table are natural numbers starting from 1, which are row numbers corresponding to table records. In this case, we can directly locate dimension table records according to key values by row numbers. This helps speed up association with the dimension table and increase performance.
If there is an F field in ch, just modify the existing field of ch. Use the latest time calculated through now() when time key value is not specified.
This is an attached computation.
Option:
|
@i |
Delete the whole record if the foreign key can’t be matched; by default, make it null |
|
@o(Fi; C:.,T:K,x:F,…; …;…) |
Generate a new record by using the original record as a new field |
|
@d |
Delete the whole record matching foreign key value when parameters x:F are absent and perform filtering on ch only |
|
@m |
Use MERGE method during parallel computation when ch is ordered by the foreign key and T is ordered by its key |
Parameter:
|
ch |
A channel |
|
C |
Foreign key of a given channel; use comma to separate a composite key |
|
T |
A table sequence/record sequence |
|
K |
Key of the given table sequence/record sequence |
|
x |
A field expression of the given table sequence/record sequence |
|
F |
Name of the field expression |
Return value:
Channel
Example:
|
|
A |
B |
C |
|
|
1 |
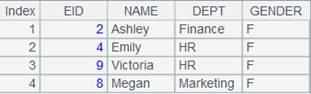
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
|
|
A1 returns a cursor. |
|
2 |
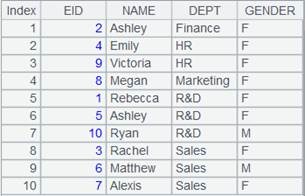
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
|
|
A2 returns a table sequence using STATEID as the key:
|
|
3 |
=channel() |
=A3.join(STATEID,A2,CAPITAL) |
=B3.fetch() |
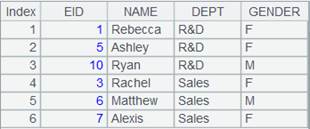
A3 creates a channel; B3 attaches a computation to channel A3, which will perform a foreign-key-style association between CITIES table and STATECAPITAL table, whose key, which is STATEID, is specified by parameter K by default, and join STATECAPITAL table’s field CAPITAL to the channel, and returns result to channel A3. C3 executes the result set function in channel A2 and keeps the current data in channel. |
|
4 |
=channel() |
=A4.join(STATEID,A2:#,CAPITAL) |
=B4.fetch() |
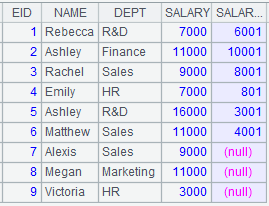
A4 creates a channel; B4 attaches a computation to channel A4 and returns result to channel A4. STATEID field values are natural numbers starting from 1, which correspond to record numbers in STATECAPITAL table; so parameter K can be specified as # to use those record numbers, which helps increase computing efficiency. C4 executes the result set function in channel A2 and keeps the current data in channel. |
|
5 |
=channel() |
=A5.join@i(STATEID,A2,CAPITAL) |
=B5.fetch() |
A5 creates a channel; B5 attaches a computation to channel A5, which will use @i option to delete the whole record in the channel if its foreign key cannot find a match – record the record as null by default – and returns result to channel A5. C5 executes the result set function in channel A2 and keeps the current data in channel. |
|
6 |
=channel() |
=A6.join@d(STATEID,A2) |
=B6.fetch() |
A6 creates a channel; B6 attaches a computation to channel A6, which will perform a filtering operation only on table CITIES and use @d option to delete the whole record in the channel if its foreign key finds a match when parameters x:F are absent, and returns result to channel A6. C6 executes the result set function in channel A2 and keeps the current data in channel. |
|
7 |
=channel() |
=A7.join@o(cities;STATEID,A2,CAPITAL) |
=B7.fetch() |
A7 creates a channel; B7 attaches a computation to channel A7, which will use @o option to generate new records using the original records of the channel as field cities, and returns result to channel A7. C7 executes the result set function in channel A2 and keeps the current data in channel. |
|
8 |
=A1.push(A3,A4,A5,A6,A7) |
|
|
Be ready to push cursor A1’s data to channels A3, A4, A5, A6 and A7, but the action needs to wait. |
|
9 |
=A1.fetch() |
|
|
Fetch data from cursor A1 while pushing data to the channels to execute the attached computations and keep the results. Below is the returned result:
|
|
10 |
=A3.result() |
|
|
Get channel A3’s result:
|
|
11 |
=A4.result() |
|
|
Get channel A4’s result:
|
|
12 |
=A5.result() |
|
|
Get channel A5’s result:
|
|
13 |
=A6.result() |
|
|
Get channel A6’s result:
|
|
14 |
=A7.result() |
|
|
Get channel A7’s result:
|




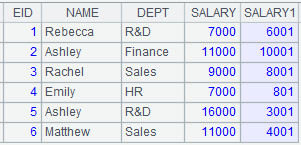

cs.jo in()
Description:
Attach foreign key style join with a record sequence to the cursor and return the original cursor.
Syntax:
cs.join(C:.,T:K,x:F,…; …;…)
Note:
The function attaches a computation to cursor cs, which matches field C,… in cursor cs with the key of parameter T, on which expression x is computed, and adds an F field that is assigned by results of x to cs, and return the original cursor. It supports the multicursor.
K can be omitted or represented by #. When omitted, K is T’s key by default; when written as #, K is the ordinal number of a record of table T, which means foreign key numberization. Simply put, primary key values of the dimension table are natural numbers starting from 1, which are row numbers corresponding to table records. In this case, we can directly locate dimension table records according to key values by row numbers. This helps speed up association with the dimension table and increase performance.
If there is an F field in cs, just modify the existing field of ch. Use the latest time calculated through now() when time key value is not specified.
This is a delayed function.
Parameter:
|
cs |
A cursor/A multicursor |
|
C |
Cursor cs’s foreign key; separate multiple fields in a composite key with the colon |
|
T |
A table sequence/A record sequence |
|
K |
T’s key |
|
x |
T’s field expression |
|
Field name in expression x. |
Option:
|
@i |
Delete a record with a non-matching foreign key value; by default, a non-matching record will be represented by null |
|
@o(Fi; C:.,T:K,x:F,…; …;…) |
Use the original record as the value of Fi field to generate a new record |
|
@d |
If parameters x:F are absent, only perform a filtering over the cursor by deleting its records where the foreign key is matched |
|
@m |
Enable a merge join when cs is ordered by C and T is ordered by K |
Return value:
Cursor
Example:
When parameter K is absent:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor, whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
=A1.join(STATEID,A2,CAPITAL) |
Attach a computation to cursor A1, which creates association between CITIES table and STATECAPITAL table through the foreign key specified by parameter K, whose value is by default the latter’s key, STATEID, and adds field CAPITAL in STATECAPITAL to the cursor, and return the original cursor. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed (it would be better to fetch data in batches when there is a huge amount of data):
|



When parameter K is written as #:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
=A1.join(STATEID,A2:#,CAPITAL) |
Attach a computation to cursor A1 and return the original cursor; as STATEID field values are natural numbers beginning from 1 that strictly correspond to record numbers in STATECAPITAL table, we can write parameter K as #, which means ordinal numbers in the table can be directly used to increase the computing efficiency. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed:
|


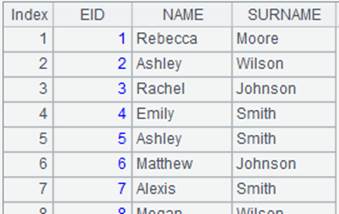
When @i option works:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
=A1.join@i(STATEID,A2,CAPITAL) |
Attach a computation to cursor A1, which, with @i option, deletes the whole record from the cursor if the foreign key does not match – by default the corresponding value is recorded as null, and return the original cursor. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed:
|

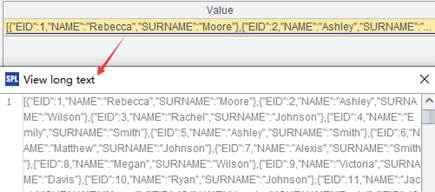
When @i option works and parameters x:F are absent:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
=A1.join@i(STATEID,A2) |
Attach a computation to cursor A1, which, with @i option, performs a filtering operation only on CITIES table when parameters x:F are absent , and return the original cursor. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed:
|
When @d works:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
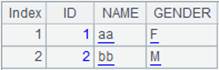
=A1.join@d(STATEID,A2) |
Attach a computation to cursor A1, which, with @d option, deletes the whole record in the cursor that matches the foreign key when parameters x:F are absent to achieve a filtering operation on CITIES table, and return the original cursor. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed:
|


When value of parameter x does not exist in T:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
=A1.join(STATEID,A2,abc) |
Attach a computaton to cursor A1, which records the corresponding field as null if parameter x value does not exist in A2, and return the original cursor. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed:
|


When @o works:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
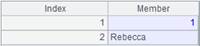
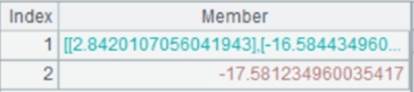
=A1.join@o(cities;STATEID,A2,CAPITAL) |
Attach a computation to cursor A1, which, with @o option, generates new records by making the cursor’s records values of cities field, and return the original A1. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed:
|
Modify the existing field when F field already exists in cs:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 10 CID,NAME,POPULATION,STATEID FROM CITIES") |
Return a cursor whose data is as follows:
|
|
2 |
=connect("demo").query("SELECT top 40 * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence whose key is STATEID:
|
|
3 |
=A1.join(STATEID,A2,CAPITAL:NAME) |
Attach a computation to cursor A1, which modifies the existing field as NAME field already exists in CITIES table, and return the original cursor. |
|
4 |
=A1.fetch() |
Fetch data from cursor A1 where A3’s computation is executed:
|


Related function:
cs.join ()
Description:
A foreign-key-style join between a cluster cursor and a record sequence.
Syntax:
cs.join(C:.,T:K,x:F,…; …;…)
Note:
The function matches foreign key field C,… of cluster cursor cs with the key of parameter T to find corresponding records in table T. Add an F field represented by x, which is T’s field expression, to cs and return the original cluster cursor. ordinal number.
K can be omitted or represented by #. When omitted, K is T’s key by default; when written as #, K is the ordinal number of a record of table T, which means foreign key numberization. Simply put, primary key values of the dimension table are natural numbers starting from 1, which are row numbers corresponding to table records. In this case, we can directly locate dimension table records according to key values by row numbers. This helps speed up association with the dimension table and increase performance.
If there is an F field in cs, just modify the existing field of ch. Use the latest time calculated through now() when time key value is not specified.
It supports the multicursor.
Option:
|
@c |
With a distributed cluster table, the operation won’t involve a cross-node reference but it assumes that the referenced records are local |
Parameter:
|
cs |
A cursor/multicursor/cluster cursor |
|
C |
cs’s foreign key; separate multiple fields in a composite key with the colon |
|
T |
A cluster in-memory table |
|
K |
T’s key |
|
x |
T’s field expression |
|
F |
Name of T’s field expression |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
[192.168.18.143:8281] |
|
|
2 |
=file("emp_1.ctx":[2], A1) |
|
|
3 |
=A2.open() |
|
|
4 |
=A3.cursor() |
A cluster cursor. |
|
5 |
[192.168.0.110:8281] |
|
|
6 |
=file("PERFORMANCE.ctx":[1],A5) |
|
|
7 |
=A6. open () |
|
|
8 |
=A7.cursor() |
|
|
9 |
=A8.memory() |
A cluster in-memory table. |
|
10 |
=A4.join(EID,A9:EMPLOYEEID, BONUS*12:total) |
Match EID field of A4’s cluster cursor with the key field EMPLOYEEID of A9’s cluster in-memory table, make the value of calculating expression BONUS*12 over the memory table’s total field and join it up with the cluster cursor, and return the cluster cursor. |
|
11 |
=A10.fetch() |
Fetch data from A10’s cursor.
|

T.join()
Description:
Define a computation of foreign-key-style join on a pseudo table and return a new pseudo table.
Syntax:
T.join(C:.,A:K,x:F,…; …;…)
Note:
The function defines a computation on pseudo table T, which will match its field C with the key of table sequence/record sequence A, compute expression x on each of the corresponding records, make the computing results values of field F to join with T, and return a new pseudo table.
K can be omitted or represented by #. When omitted, K is A’s key by default; when written as #, K is the ordinal number of a record of table A, which means foreign key numberization. Simply put, primary key values of the dimension table are natural numbers starting from 1, which are row numbers corresponding to table records. In this case, we can directly locate dimension table records according to key values by row numbers. This helps speed up association with the dimension table and further increase performance.
If there is an F field in T, just modify the existing field of A. Use the latest time calculated through now() when time key value is not specified.
Option:
|
@i |
Delete a record with a non-matching foreign key value; by default, a non-matching record will be represented by null |
|
@o(Fi; C:.,T:K,x:F,…; …;…) |
Use the record as the value of F field to generate a new record |
|
@d |
When parameters x:F are absent, delete whole records matching the foreign key and perform the filtering operation only over pseudo table T |
|
@m |
Enable a merge join when T is ordered by C and A is ordered by K |
Parameter:
|
T |
A pseudo table |
|
C |
T’s foreign key; separate multiple fields in a composite key with the colon |
|
A |
Table sequence/record sequence |
|
K |
A’s key |
|
x |
A’s field expression |
|
F |
Field name in expression x |
Return value:
Pseudo table
Example:
|
|
A |
B |
|
|
1 |
=create(file).record(["cities.ctx"]) |
|
Below is content of composite table cities.ctx:
|
|
2 |
=pseudo(A1) |
|
Generate a pseudo table from the composite table. |
|
3 |
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID) |
|
Below is content of STATECAPITAL:
|
|
4 |
=A2.join(STATEID,A3,CAPITAL) |
=A4.cursor().fetch() |
Execute expression in A4. Define a computation on A2’s pseudo table, which will associate A2’s pseudo table CITIES and A3’s STATECAPITAL table through the foreign key, during which default parameter K is STATEID, the key of STATECAPTITAL, and add STATECAPITAL’s CAPITAL field to CITIES to generate a new pseudo table. Execute expression in B4: fetch data from A4’s pseudo table while executing the computation defined in A4 on A2’s pseudo table, and return the following table:
|
|
5 |
=A2.join(STATEID,A3:#,CAPITAL) |
=A5.import() |
Execute expression in A5. Define a computation on A2’s pseudo table; as STATEID field values are natural numbers starting from 1, which correspond to ordinarl numbers of records in STATECPATITAL table, parameter K is written as # to use those ordinal numbers in order to increae efficiency; Execute expression in B5 and return same result as B4. |
|
6 |
=A2.join@i(STATEID,A3,CAPITAL) |
=A6.import() |
@i option enables deleting records with non-matching foreign key values – write them as nulls if there isn’t the option – and execute B6 and return the following table:
|
|
7 |
=A2.join@i(STATEID,A3) |
=A7.import() |
@i option enables filtering CITIES table only when parameters x:F are absent; execute B7 and return the following table:
|
|
8 |
=A2.join@d(STATEID,A3) |
=A8.import() |
With @d option and when parameters x:F are absent, delete records where foreign key values are matching and perform filtering only on pseduo table CITIES; execute B8 and return the following table:
|
|
9 |
=A2.join(STATEID,A3,abc) |
=A9.import() |
Write records where values of parameter x cannot be found in A2 as nulls; execute B9 and return the following table:
|
|
10 |
=A2.join@o(cities;STATEID,A3,CAPITAL) |
=A10.import() |
@o option enables to take the whole orignal record as a cities value
to generate a new record; this is equivalent to an expression where parameter
x is ~; execute B10 and return the following table: |
|
11 |
=A2.join(STATEID,A3,CAPITAL:NAME) |
=A11.import() |
Modify the existing fields when NAME field already exists in CITIES table; execute B11 and return the following table:
|