index()
Here’s how to use index() functions.
T.index()
Description:
Create an index table for the key of a table sequence.
Syntax:
T.index(n)
Note:
The function creates an index table, whose length is n, on the basic key of table sequence T. Records with same time key value could be placed at the same index address. The index table will be cleared if n=0, or when the table sequence’s key is reset; the index table’s length will be automatically identified if n isn’t supplied. An index table can help speed up the key-based data query process.
To create an index table, we assume that the records’ primary key values are unique, otherwise error will be reported. Create HASH table only according to the basic key and arrange records having different time key values in the same HASH location.
Parameter:
|
T |
A table sequence with a key |
|
n |
Index length |
Option:
|
@s |
Create a multilevel tree-structured index and ignore parameter n if the table sequence’s basic key is serial byte values |
|
@m |
Enable parallel processing |
|
@n |
Create an ordinal-number index for the table sequence; the index is used for numberizing the foreign key. Foreign key numberization requires that foreign key values of the fact table correspond to ordinal numbers of the dimension table’s records; the ordinal number key can be omitted when using the index, and ignore parameter n when the option works. The option is not fit for a table sequence containing a time key |
Return value:
Table sequence
Example:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,SALARY from EMPLOYEE where EID<4") |
|
|
2 |
=A1.keys(EID) |
Set EID as A1’s key. |
|
3 |
=A1.index(10) |
Create an index table for the table sequence’s key; the length is 10. |
|
4 |
=A1.index@m(100) |
Create an index table using parallel processing. |
Create a multilevel tree-structured index:
|
|
A |
|
|
1 |
=3.new(k(~:2):id,~*~:num) |
Create a table sequence where id field is serial byte type. |
|
2 |
=A1.keys(id) |
Set id as A1’s key.
|
|
3 |
=A2.index@s() |
As A1’s basic key is serial byte type, use @s option to create a multilevel tree-structured index. |
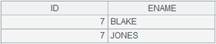
Create an ordinal-number-based index:
|
|
A |
|
|
1 |
=connect("demo").query("SELECT * FROM CITIES") |
Return a table sequence:
|
|
2 |
=connect("demo").query("SELECT * FROM STATECAPITAL").keys(STATEID) |
Return a table sequence and set EID as the key:
|
|
3 |
=A2.index@n() |
Create an ordinal-number index for A2’s table sequence. |
|
4 |
=A1.switch(STATEID,A3) |
CITIES table acts as the fact table and STATECAPITAL as the dimension table; convert values of STATEID, the CITIES’s key, to corresponding referencing records in STATECAPITAL. The index table on foreign key STATEID is used during the computing process, so the ordinal number key STATEID is omitted from the expression, which is equivalent to A1.switch(STATEID,A3:#). |
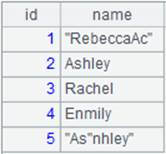
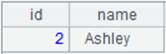
Related function:
T.index( n )
Description:
Create an index on the key of an in-memory table.
Syntax:
T.index(n)
Note:
The function creates an index whose length is n for the key of in-memory table T. Remove the index when parameter n is 0 or the in-memory table reset key; auto-select length of the index when parameter n is absent. The index facilitates data searching when we need to perform multiple searches according to the primary key.
To create an index table, we assume that the records’ primary key values are unique, otherwise error will be reported. Create HASH table only according to the basic key and arrange records having different time key values in the same HASH location.
Parameter:
|
T |
An in-memory table with unique primary key values |
|
n |
The length of index |
Option:
|
@m |
Create the index with parallel processing |
|
@n |
Create index on the ordinal number key |
|
@s |
Create a multilevel tree-structured index when the in-memory table T’s basic key is serial byte type, and ignore parameter n |
Return value:
An in-memory table
Example:
Create index on the in-memory table’s primary key:
|
|
A |
|
|
1 |
=file("ei.ctx") |
|
|
2 |
=A1.create@y(#EID,NAME,DEPT) |
Create the composite table’s base table and set EID as the key. |
|
3 |
=demo.cursor("select EID,NAME,DEPT from employee") |
|
|
4 |
=A2.append@i(A3) |
Append cursor A3’s data to the composite table. |
|
5 |
=A4.memory() |
Generate an in-memory table from a composite table’s entity. table; the new table inherits the entity table’s key. |
|
6 |
=A5.index(10) |
Create an index of length 10 on in-memory table’s key. |
Create multilevel tree-structured index on the in-memory table:
|
|
A |
|
|
1 |
=3.new(k(~:2):id,~*~:num) |
Create a table sequence. |
|
2 |
=A1.keys(id) |
Set id as the table sequence’s key. |
|
3 |
=A2.memory() |
Convert the table sequence into an in-memory table, which inherits the former’s key.
|
|
4 |
=A3.index@s() |
As the in-memory table’s key is serial byte, use @s option to create multilevel tree-structured index for it. |
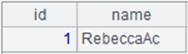
Create ordinal-number-based index for the in-memory table:
|
|
A |
|
|
1 |
=to(100).new(~*2:c1,rand():c2) |
Create a table sequence.
|
|
2 |
=A1.memory() |
Generate an in-memory table from the table sequence. |
|
3 |
=A2.index@n() |
Use @n option to create index on the in-memory table’s ordinal number key; in this case the in-memory table only has the ordinal number key without the basic key. |
|
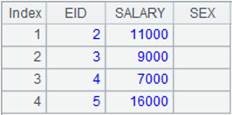
4 |
=A3.find(6) |
Get the record whose key value is 6 from the in-memory table, which is the one whose ordinal number key value is 6, and return the following result:
|

T.index( f:h,w;C,…;F,… )
Description:
Create index file for an entity table.
Syntax:
T.index(f:h,w;C,…;F,…)
Note:
For records of entity table T that meets condition w, use column C,… as the key and create index file object f on it; the index file does not update itself accordingly when the composite table is updated (or reset).
Field name of entity table T; the presence of F speeds up the query. When using the index file to retrieve data, get the indexed fields C,… and F field only; retrieve all fields when F is absent.
Creating an index file requires the presence of column C,… and index file object f.
If parameter h is present and @w option is absent, create a HASH index file whose length his h; create a full-text index file when @w option works; create an ordered index file when both parameter h and @w option are absent. Parameter F should be absent if you need to create a HASH index or full-text index.
When T is an attached table, parameter C cannot be a field inherited from the primary table.
Parameter:
|
T |
An entity table |
|
f |
Index file object |
|
w |
Filtering condition; retrieve the whose set if the parameter is absent |
|
C |
The field for which an index is created |
|
h |
Hash index length; can be omitted |
|
F |
Field name in an entity table; can be omitted |
Option:
|
@2 |
Work when only parameter f is present; used to load the index file to the memory and can increase performance |
|
@3 |
Work when only parameter f is present; used to load the index file to the memory; help achieve higher performance than @2 but occupy more memory space |
|
@0 |
Close the index to release resources when only parameter f is present |
|
@w |
Create a full-text index on column C, which should be a string type single column; Only support like("*X*") style search; X can be a string made up of letters, numbers or common characters, whose length should be greater than 2, or one or more Chinese characters; Case-insensitive when the index string is made up of letters; With this option, parameter h is interpreted as the largest number of records matched with each index string; no such interpretation when h is absent |
Return value:
Entity table
Example:
Create an ordered index file:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,BIRTHDAY,DEPT,GENDER,HIREDATE,SALARY from employee ") |
Return a table sequence. |
|
2 |
=file("empi.ctx") |
|
|
3 |
=A2.create@y(#EID,NAME,BIRTHDAY,DEPT,GENDER,HIREDATE,SALARY) |
Create a composite table. |
|
4 |
=A3.append@i(A1) |
Append table sequence A1’s data to the composite table. |
|
5 |
=file("index_dzdpx") |
Create index file object. |
|
6 |
=A3.index(A5,DEPT=="HR";EID;DEPT) |
For data of EID and DEPT fields meeting DEPT=="HR" in composite table A3, create ordered index file index_dzdpx on EID, which is the indexed field. |
|
7 |
=file("index_px") |
Create index file object. |
|
8 |
=A3.index(A7;EID,NAME) |
Create index file index_px for composite table A3 on EID and NAME, which are indexed fields; as parameter F is absent, read all fields of the table. |
|
9 |
=A3.icursor(EID,NAME,DEPT,SALARY;EID<20;A7,A5) |
Query EID, NAME, DEPT and SALARY fields meeting EID<20 in the composite table according to the index file.
|
Create a HASH index file:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
Open the composite table. |
|
2 |
=file("index_hs") |
Create index file object. |
|
3 |
=A1.index(A2:10;DEPT,GENDER) |
Create a HASH index file whose length is 10 for composite table empi.ctx on DEPT and GENDER, which are the indexed fields. |
|
4 |
=A1.icursor(NAME,DEPT,GENDER,SALARY;[["HR","M"]].contain(DEPT,GENDER);A2) |
Use index file index_hs to query data of NAME, DEPT, GENDER and SALARY fields where DEPT is HR and GENDER is M in the composite table and return a cursor, whose content is as follows:
|

Create a full-text index file:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
Open the composite table file. |
|
2 |
=file("index_qw") |
Create index file object. |
|
3 |
=A1.index@w(A2;NAME) |
Use @w option to create a full-text index file for composite table empi.ctx on NAME which are the indexed field. |
|
4 |
=A1.icursor(EID,NAME,BIRTHDAY;like(NAME," *ann *");A2) |
Use index file index_qw to query data of EID, NAME and BIRTHDAY fields in the composite table where NAME values contain string “ann” and return result as a cursor, whose content is as follows:
|
|
5 |
=file("index_qw1") |
|
|
6 |
=A1.index@w(A5:5;NAME) |
Use @w to create a full-text index file, whre the index string is case-insensitive; the value of parameter h is 5 means the largest number of records each index string can match. |
|
7 |
=A1.icursor(EID,NAME,BIRTHDAY;like(NAME,"*ANN*");A5) |
Content of the returned cursor is as follows:
|


Automatically load the composite table’s index file:
|
|
A |
|
|
1 |
=file("empi.ctx").open() |
Open the composite table file. |
|
2 |
=A1.index@2(file("index_qw")) |
Load the composite table’s index file to the memory. |
|
3 |
=A1.icursor(EID,NAME,BIRTHDAY;like(NAME,"A*");file("index_qw")) |
Use the index file loaded to the memory to query data in the composite table. |
|
4 |
=A1.index@0(file("index_qw")) |
Release the memory resources occupied by the index file. |
|
5 |
>A1.close() |
Close the composite table. |
T.index(I:h,w;C,…)
Description:
Create one or multiple non-primary-key-based indexes for an in-memory table.
Syntax:
T.index(I:h,w;C,…)
Note:
Treat column(s) C,… as the key and create index I for records meeting condition w , which can be omitted, on the key. When parameter h is present, create a hash index whose length is h.
The function creates one or multiple non-primary-key-based indexes for in-memory table T during creating a cursor.
Parameter:
|
T |
An in-memory table |
|
I |
Index name |
|
w |
Filtering condition; read the whole set when it is absent |
|
C |
The field(s) on which index is created |
|
h |
Index length |
Return value:
An in-memory table
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES ") |
|
|
2 |
=file("SCORES_ClassTwo.ctx") |
Create a composite table file. |
|
3 |
=A2.create@y(#CLASS,#STUDENTID,SUBJECT,SCORE) |
Create the composite table’s base table, where CLASS,#STUDENTID is the composite table’s key. |
|
4 |
=A3.append@i(A1) |
Append data of A1’s cursor to the base table. |
|
5 |
=A4.memory() |
Generate an in-memory table. |
|
6 |
=A5.index(index1:10,CLASS =="Class one";SCORE) |
Create a non-primary-key-based index named index1 for A5’s in-memory table. |