joinx()
Here’s how to use joinx() functions.
joinx()
Description:
Join table sequences retrieved from a series of cursors.
Syntax:
joinx(csi:Fi,xj,..;…)
Note:
The function applies MERGE algorithm over a resulting set generated from a series of ordered cursors csi and returns a new cursor. If parameter xj is omitted, join the cursors according to their primary keys; if parameter xj is present but there isn’t any primary key, perform the join based on values of xj. The function can be also used to join multiple multicursors where each one must have the same number of parallel cursors or subcursor. Parameter csi can be a table sequence.
Supposing multiple cursors csi are already ordered by join field/expression xj, the function performs a join between them on the condition that xj’s value is equivalent to the value of x1 field and returns a cursor consisting of Fi,…. fields. Fi,…. are referencing fields that reference the records of the cursors csi. Note: xj… only supports the ascending order.
Regardless of the number of cursors being joined, the equivalence determination is conducted according to cursor cs1’s x1 field. Therefore, it is a one-to-many relationship.
This is a delayed function.
Option:
|
@f |
Full join. If no matching records are found, then use nulls to correspond |
|
@1 |
Left join. Note that it is the number “1”, instead of letter “l” |
|
@p |
Perform a join according to positions, while ignoring the parameter xj |
|
@i |
Used only to filter A1 cs1 and ignore parameter Fi; do not work with @f@1 options |
|
@d |
Used only to filter cs1 to retain records that cannot be found and ignore parameter Fi; do not work with @f@1 options |
Parameter:
|
csi |
Cursors/table sequences being joined |
|
Fi |
Field name of the result table sequence |
|
xj |
Join field/expression |
Return value:
Cursor
Example:
Join by the primary key:
|
|
A |
|
|
1 |
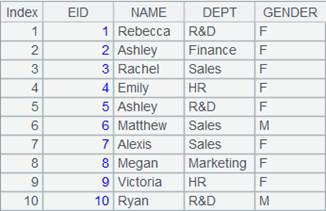
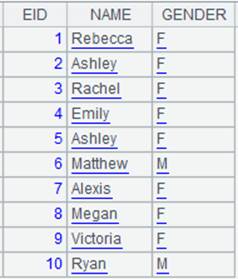
=demo.query("select top 10 EID,NAME,DEPT,GENDER from EMPLOYEE " ).keys(EID).cursor() |
Return a cursor where the table’s primary key is EID and whose data is as follows:
|
|
2 |
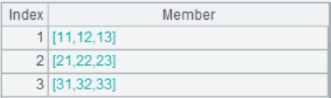
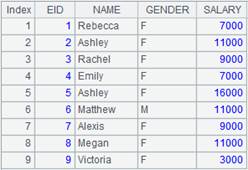
=demo.query("select top 10 EID,NAME,RELATION,GENDER,AGE from FAMILY " ).keys(EID) |
Return a table sequence whose key is EID and whose data is as follows:
|
|
3 |
=joinx(A1:Emp;A2:Family) |
Join by the primary key. |
|
4 |
=A3.fetch() |
Fetch data from cursor A3:
|
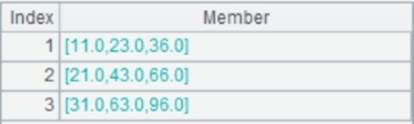
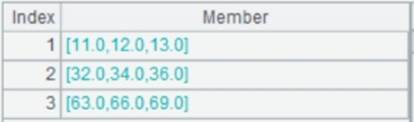
Use @f option to perform full join:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER from EMPLOYEE where EID>2 and EID<10" ) |
Return a cursor whose data is as follows:
|
|
2 |
=demo.query("select top 10 EID,NAME,RELATION,GENDER,AGE from FAMILY " ) |
Return a cursor whose data is as follows:
|
|
3 |
=joinx@f(A1:Emp,EID;A2:Family,EID) |
Use @f option to enable a full join that records a field as null when no matching value can be found. |
|
4 |
=A3.fetch() |
Fetch data from cursor A3:
|
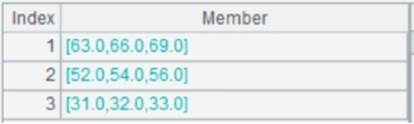


Use @1 to perform left join:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER from EMPLOYEE where EID>2 and EID<10" ) |
Return a cursor whose data is as follows:
|
|
2 |
=demo.query("select top 10 EID,NAME,RELATION,GENDER,AGE from FAMILY " ) |
Return a cursor whose data is as follows:
|
|
3 |
=joinx@1(A1:Emp,EID;A2:Family,EID) |
Use @1 option to enable left join based on the first cursor and that records a value that does not have a matching value in another cursor as null. |
|
4 |
=A3.fetch() |
Fetch data from cursor A3:
|
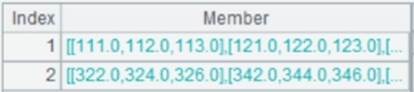
Use @p option to perform position-based join:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER from EMPLOYEE where EID>2 and EID<10" ) |
Return a cursor whose data is as follows:
|
|
2 |
=demo.query("select top 10 EID,NAME,RELATION,GENDER,AGE from FAMILY " ) |
Return a cursor whose data is as follows:
|
|
3 |
=joinx@p(A1:Emp,EID;A2:Family,EID) |
Use @p option to perform position-based join. |
|
4 |
=A3.fetch() |
Fetch data from cursor A3:
|

Use @i option to enable a filtering operation only:
|
|
A |
|
|
1 |
=demo.cursor("select top 10 EID,NAME,DEPT,GENDER from EMPLOYEE" ).sortx(DEPT) |
Return a cursor whose data is as follows:
|
|
2 |
=demo.query("select top 5 * from DEPARTMENT " ).sort(DEPT) |
Return a table sequence whose data is as follows:
|
|
3 |
=joinx@i(A1,DEPT;A2,DEPT) |
Use @i option to filter cursor A1, during which records that match A2 are retained. |
|
4 |
=A3.fetch() |
Fetch data from cursor A3:
|



Use @d option to enable a filtering operation opposite to @i:
|
|
A |
|
|
1 |
|
Return a cursor whose data is as follows:
|
|
2 |
=demo.query("select top 5 * from DEPARTMENT " ).sort(DEPT) |
Return a table sequence whose data is as follows:
|
|
3 |
=joinx@d(A1,DEPT;A2,DEPT) |
Use @d option to filter cursor A1, during which records that do not match A2 are retained. |
|
4 |
=A3.fetch() |
Fetch data from cursor A3:
|

Related function:
joinx()
Description:
Join up synchronously segmented cluster cursors.
Syntax:
joinx(csi:Fi,xi,..;…)
Note:
Suppose that the joining fields/expressions xi are ordered in an ascending order, the function joins up multiple synchronously segmented cluster cursors according to the condition that the values of the joining fields/expressions xi and x1 are equal to generate a cluster cursor consisting of fields Fi,….
Parameter Fi is a referencing field that references records of the csi, the sequence of the original cluster cursors. Join up the cluster cursors by primary keys when parameter xj is absent; and by the values of xj when the parameter is present but no dimensions are set. The function supports cluster multicursors that should contain the same number of subcursors.
The join operation is performed by matching the joining field x1 in cs1 with the values of all the other joining fields/expressions, which means it is a one-to-many relationship. The to-be-joined cursors should be stored in one node; cross-node retrieval isn’t allowed.
Option:
|
@f |
Full join; use null to correspond when there is no matching value |
|
@1 |
Left join; the option is number 1 instead of letter l |
|
@p |
Join by positions; ignore parameter xj |
|
@i |
Used only to filter A1 cs1 and ignore parameter Fi; do not work with @f@1 options |
|
@d |
Used only to filter cs1 to retain records that cannot be found and ignore parameter Fi; do not work with @f@1 options |
Parameter:
|
Fi |
The resulting field |
|
csi |
To-be-joined cluster cursors |
|
xi |
Joining field/expression |
Return value:
Cluster cursor
Example:
|
|
A |
|
|
1 |
=file("t1.ctx","192.168.0.111:8281") |
|
|
2 |
=A1.open() |
Open cluster composite table t1.ctx. |
|
3 |
=A2.cursor@m(;;3) |
Generate a synchrounous 3-parts multicursor from A2’s cluster composite table. |
|
4 |
=file("t2.ctx","192.168.0.111:8281") |
|
|
5 |
=A4.open() |
Open cluster composite table t2.ctx. |
|
6 |
=A5.cursor(;;A3) |
Synchronously segment A5 according to A3’s multicursor. |
|
7 |
=joinx(A3:t1,EID;A6:t2,EID).fetch() |
Join up A3 and A6 to perform a multithreading computation. |
cs.joinx ()
Description:
Join up a cursor and a segmentable bin file according to the foreign key.
Syntax:
cs.joinx(C:…,f:K:…,x:F,…;…;…;n)
Note:
The function matches the foreign key fields C,… in cursor cs with field K in segmentable bin file f, which is ordered by K, to find the corresponding record in f, and makes the record’s expression x a new field F and adds it to cs to generate a new cursor. The value corresponding to a mismatched record will be recorded as null. The cursor the function returns is irreversible.
Option:
|
@i |
Discard the records whose foreign key values can’t be matched; represent them as nulls by default; When parameters x:F are absent, only perform the filtering on the cursor/multicursor |
|
@d |
When parameters x:F are absent, discard the records whose foreign key values are matching |
|
@q |
Speed up the matching action according to a certain order when the cursor contains a relatively small amount of data or it is a sequence; return a sequence when cursor/multicursor cs is a sequence |
|
@u |
Speed up the matching operation by shuffling records in the cursor |
|
@m |
Perform a merge join when cs is ordered by C and f is ordered by K; with this option, the bin file f can be a cursor, and when cs is a multicursor, it is the multicursor partitioned in the same way |
Parameter:
|
cs |
A cursor/multicursor |
|
C |
cs’s foreign key |
|
f |
A segmentable bin file |
|
K |
A field of the bin file; it is treated as row number when written as # |
|
x |
An expression of the field of f |
|
F |
Name of the field of expression x |
|
n |
Number of buffer rows |
Return value:
Cursor/Sequence
Example:
Normal join between a cursor and a bin file:
|
|
A |
|
|
1 |
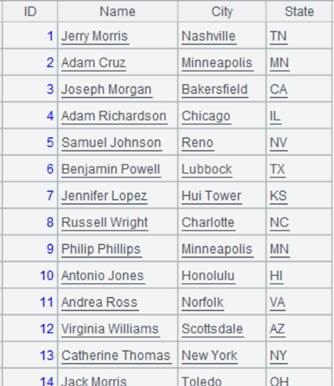
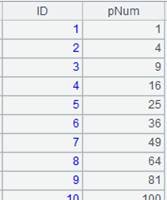
=file("PersonnelInfo.txt").cursor@t(ID,Name,City,State) |
Return a cursor, whose data is as follows:
|
|
2 |
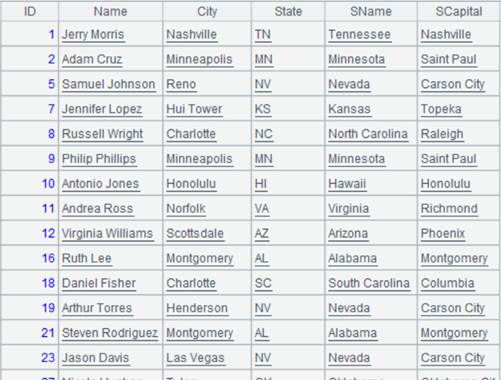
=file("StateFile.btx") |
Return a segmented bin file ordered by ABBR field; below is data in the file:
|
|
3 |
=A1.joinx(State,A2:ABBR,NAME:SName,CAPITAL:SCapital;10000) |
Match cursor A1’s State field with StateFile.btx’s ABBR field, rename StateFile.btx’s NAME field and CAPTITAL field SName and SCapital, and piece them to cursor A1 to generate a new cursor. |
|
4 |
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|

Use @i option to delete records that cannot match the foreign key:
|
|
A |
|
|
1 |
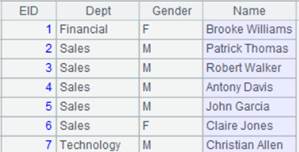
=file("PersonnelInfo.txt").cursor@t(ID,Name,City,State) |
Return a cursor, whose data is as follows:
|
|
2 |
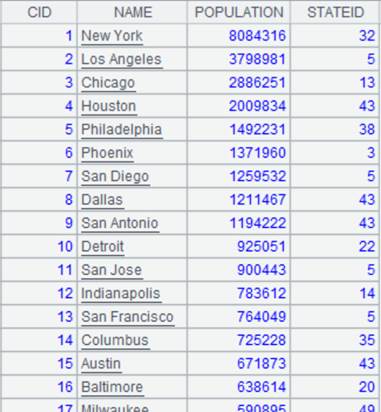
=file("StateFile.btx") |
Return a segmented bin file ordered by ABBR field; below is data in the file:
|
|
3 |
=A1.joinx@i(State,A2:ABBR,NAME:SName,CAPITAL:SCapital;10000) |
Use @i option to delete records that cannot match cursor A1’s foreign key State. |
|
4 |
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|

Use @d option:
|
|
A |
|
|
1 |
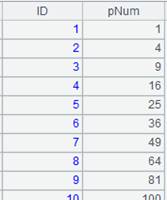
=file("PersonnelInfo.txt").cursor@t(ID,Name,City,State) |
Return a cursor, whose data is as follows:
|
|
2 |
=file("StateFile.btx") |
Return a segmented bin file ordered by ABBR field; below is data in the file:
|
|
3 |
=A1.joinx@d(State,A2:ABBR;10000) |
Use @d option to retain records that cannot match cursor A1’s foreign key State. |
|
4 |
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|
Use @q option when parameter cs is a table sequence:
|
|
A |
|
|
1 |
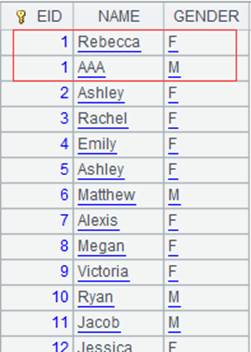
=file("PersonnelInfo.txt").import@t(ID,Name,City,State) |
Return a table sequence, whose data is as follows:
|
|
2 |
=file("StateFile.btx") |
Return a segmented bin file ordered by ABBR field; below is data in the file:
|
|
3 |
=A1.joinx@iq(State,A2:ABBR,NAME:SName,CAPITAL:SCapital) |
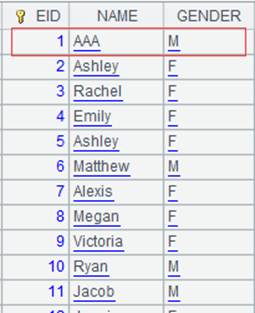
Return a table sequence when parameter cs is a table sequence; use @q option to speed up the computation and return the following result:
|

When parameter f is a cursor, use @m option to perform the MERGE algorithm:
|
|
A |
|
|
1 |
=file("PersonnelInfo.txt").cursor@t(ID,Name,City,State).sortx(State) |
Return a cursor ordered by State field, whose data is as follows:
|
|
2 |
=file("StateFile.btx").cursor@b() |
Return a cursor ordered by State field, whose data is as follows:
|
|
3 |
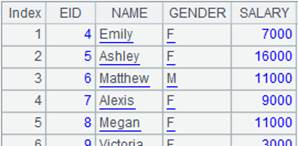
=A1.joinx@m(State,A2:ABBR,NAME:SName,CAPITAL:SCapital;10000) |
As A1 is ordered by State and A2 is ordered by ABBR, use @m option to perform MERGE algorithm. |
|
4 |
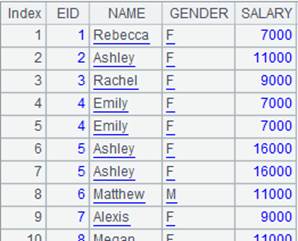
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|

cs.joinx()
Description:
Join up a cursor and an entity table by the foreign key.
Syntax:
cs.joinx(C:…,T:K:…,x:F,…;…;…;n)
Note:
The function matches the foreign key fields C,… in cursor cs with the key K in entity table T, which is ordered by K, to find the corresponding record in T, and makes the record’s expression x a new field F and adds it to cs to generate a new cursor. The value corresponding to a mismatched record will be recorded as null.
Option:
|
@i |
Discard the records whose foreign key values can’t be matched; represent them as nulls by default; When parameters x:F are absent, only perform the filtering on the cursor/multicursor |
|
@d |
When parameters x:F are absent, discard the records whose foreign key values are matching |
|
@q |
Speed up the matching action according to a certain order when the cursor contains a relatively small amount of data or it is a sequence cs Speed up the join when the cursor contains relatively small amount of data or is a sequence |
|
@u |
Speed up the matching operation by shuffling records in the cursor |
|
@m |
Can use MERGE method to perform the association when the cursor/multicursor is ordered by its foreign key and when the entity table is ordered by the primary key |
Parameter:
|
cs |
A cursor/multicursor |
|
C |
cs’s foreign key |
|
T |
An entity table |
|
K |
The entity table’s key; it is treated as row number when written as # |
|
x |
An expression of the field of T |
|
F |
Name of the field of expression x |
|
n |
Number of buffer rows |
Return value:
Cursor/Table sequence
Example:
Normal join between a cursor and an entity table:
|
|
A |
|
|
1 |
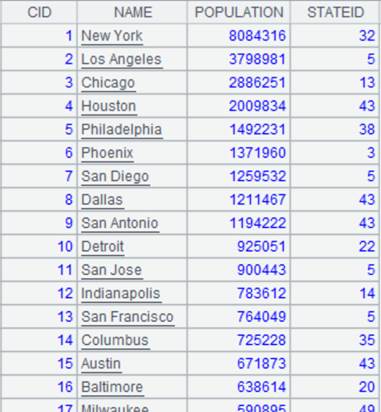
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES") |
Return a cursor, whose data is as follows:
|
|
2 |
=file("StateFile.ctx").open() |
Return an entity table using STATEID as the key; below is data in the table:
|
|
3 |
=A1.joinx(STATEID,A2:STATEID,NAME:SName,POPULATION:Spopulation;1000) |
Match cursor A1’s STATEID field with the entity table’s STATEID field, rename the latter’s NAME field and POPULATION field SName and SPopulation, and piece them to cursor A1 to generate a new cursor. |
|
4 |
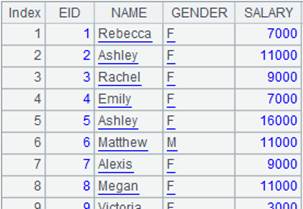
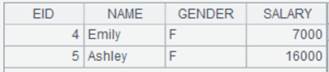
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|
Use @i option to delete records that do not match the foreign key:
|
|
A |
|
|
1 |
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES") |
Return a cursor, whose data is as follows:
|
|
2 |
=file("StateFile.ctx").open() |
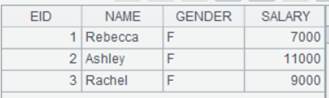
Return an entity table using STATEID as the key; below is data in the table:
|
|
3 |
=A1.joinx@i(STATEID,A2:STATEID,NAME:SName,POPULATION:SPopulation;1000) |
Use @i option to delete records that cannot match cursor A1’s foreign key STATEID. |
|
4 |
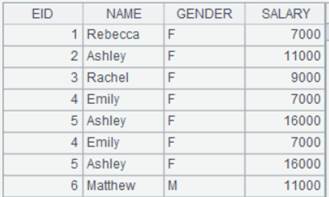
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|

Use @d option:
|
|
A |
|
|
1 |
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES") |
Return a cursor, whose data is as follows:
|
|
2 |
=file("StateFile.ctx").open() |
Return an entity table using STATEID as the key; below is data in the table:
|
|
3 |
=A1.joinx@d(STATEID,A2:STATEID) |
Use @d option to retain records that cannot match cursor A1’s foreign key STATEID. |
|
4 |
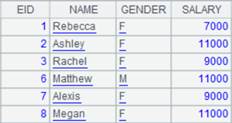
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|


Use @q option when parameter cs is a table sequence:
|
|
A |
|
|
1 |
=connect("demo").query("select CID,NAME,POPULATION,STATEID from CITIES") |
Return a table sequence, whose data is as follows:
|
|
2 |
=file("StateFile.ctx").open() |
Return an entity table using STATEID as the key; below is data in the table:
|
|
3 |
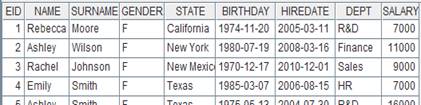
=A1.joinx@qi(STATEID,A2:STATEID,NAME:SName,POPULATION:SPopulation;1000) |
Return a table sequence when parameter cs is a table sequence; use @q option to speed up the computation and return the following result
|

Use @m option to perform the MERGE algorithm:
|
|
A |
|
|
1 |
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES").sortx(STATEID) |
Return a cursor ordered by STATEID field, whose data is as follows:
|
|
2 |
=file("StateFile.ctx").open() |
Return an entity table using STATEID as the key; below is data in the table:
|
|
3 |
=A1.joinx@m(STATEID,A2:STATEID,NAME:SName,POPULATION:SPopulation;1000) |
As both A1 and A2 are ordered by STATEID, use @m option to perform MERGE algorithm. |
|
4 |
=A3.fetch@x(100) |
Fetch the first 100 records from A3’s cursor, close the cursor when the fetching is finished, and return the following data:
|


ch.joinx()
Description:
Join up a channel and a bin file or an entity table by the foreign key.
Syntax:
|
ch.joinx(C:…,f:K:…,x:F,…;…;…;n) |
Match C,… field in channel ch with key K of the segmentable bin file f to find the corresponding records in f |
|
ch.joinx(C:…,T:K:…,x:F,…;…;…;n) |
Match C,… field in channel ch with key K of the entity table T to find the corresponding records in T |
Note:
The function matches the foreign key fields C,… in channel ch with the key K in bin file f or entity table T, which is ordered by K, to find the corresponding record in f /T, and makes the record’s expression x a new field F and adds it to ch. The value corresponding to a mismatched record will be recorded as null.
This is a function that gets the final result set.
Option:
|
@i |
Discard the records whose foreign key values can’t be matched; represent them as nulls by default; When parameters x:F are absent, only perform the filtering on the channel |
|
@d |
When parameters x:F are absent, discard the records whose foreign key values are matching |
|
@q |
Speed up the matching action according to a certain order when the channel contains a relatively small amount of data or it is a sequence |
|
@u |
Speed up the matching operation by shuffling records in the channel |
|
@m |
Can use MERGE method to perform the association when the channel is ordered by its foreign key and when the bin file/entity table is ordered by the primary key |
Parameter:
|
ch |
A channel |
|
C |
ch’s foreign key |
|
f |
A bin file |
|
T |
An entity table |
|
K |
The bin file/entity table’s key |
|
x |
An expression of the field of f/T |
|
F |
Name of the field of expression x |
|
n |
Number of buffer rows |
Return value:
Channel
Example:
Normal join between a channel and a bin file:
|
|
A |
|
|
1 |
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES") |
Return a cursor, whose data is as follows
|
|
2 |
=channel(A1) |
Create a channel and push cursor A1’s data to the channel. |
|
3 |
=file("States.btx") |
Return a segmented bin file, whose data is as follows:
|
|
4 |
=A2.joinx(STATEID,A3:STATEID,NAME:SName,POPULATION:SPopulation;1000) |
Match channel A2’s STATEID field with the bin file’s STATEID field, rename the latter’s NAME field and POPULATION field SName and SPopulation, add them to channel A2, and return a channel. |
|
5 |
=A1.fetch() |
A2 Fetch data from cursor A1, during which the data flows through the channel. |
|
6 |
=A2.result().fetch() |
Fetch data from the channel:
|



Use @i option during the association between a channel and an entity table to delete records that cannot match the foreign key:
|
|
A |
|
|
1 |
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES") |
Return a cursor, whose data is as follows:
|
|
2 |
=channel(A1) |
Create a channel and push cursor A1’s data to the channel. |
|
3 |
=file("StateFile.ctx").open() |
Return an entity table using STATEID as the key; below is data in the table:
|
|
4 |
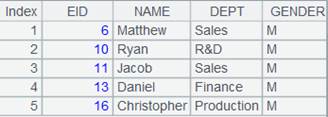
=A2.joinx@i(STATEID,A3:STATEID,NAME:SName,POPULATION:SPopulation;1000) |
Match channel A2’s STATEID field with the entity table’s STATEID field, rename the latter’s NAME field and POPULATION field SName and SPopulation, add them to channel A2, and return a channel. Use @i option to delete records that cannot match channel A2’s foreign key STATEID. |
|
5 |
=A1.fetch() |
A2 Fetch data from cursor A1, during which the data flows through channel A2. |
|
6 |
=A2.result().fetch() |
Fetch data from the channel:
|

Use @d option for association between a channel and a bin file to perform filtering opposite to @i:
|
|
A |
|
|
1 |
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES") |
Return a cursor, whose data is as follows:
|
|
2 |
=channel(A1) |
Create a channel and push cursor A1’s data to the channel. |
|
3 |
=file("States.btx") |
Return a segmented bin file, whose data is as follows:
|
|
4 |
=A2.joinx@d(STATEID,A3:STATEID) |
Match channel A2’s STATEID field with the bin file’s STATEID field, and use @d option to filter away records from A2 that cannot match the bin file’s STATEID. |
|
5 |
=A1.fetch() |
Fetch data from cursor A1, during which the data flows through channel A2. |
|
6 |
=A2.result().fetch() |
Fetch data from the channel:
|

Use @m option to perform the MERGE algorithm:
|
|
A |
|
|
1 |
=connect("demo").cursor("select CID,NAME,POPULATION,STATEID from CITIES").sortx(STATEID) |
Return a cursor ordered by State field, whose data is as follows:
Data is ordered by STATEID. |
|
2 |
=channel(A1) |
Create a channel and push cursor A1’s data to the channel. |
|
3 |
=file("States.btx") |
Return a segmented bin file, whose data is as follows:
|
|
4 |
=A2.joinx@m(STATEID,A3:STATEID,NAME:SName,POPULATION:SPopulation;1000) |
As both A2 and A3 are ordered by STATEID, use @m option to perform MERGE algorithm. |
|
5 |
=A1.fetch() |
Fetch data from cursor A1, during which the data flows through channel A2 |
|
6 |
=A2.result().fetch() |
Fetch data from the channel:
|