callx()
Here’s how to use the callx() function.
callx(spl,...;hs;rdfx)
Description:
Allocate tasks among a sequence of nodes, execute the script, and return a sequence of values returned by all tasks.
Syntax:
callx(spl,…;hs;rdfx)
Note:
The function allocates computing tasks among a sequence of nodes, executes script file .dfx/.splx, inherits task spaces, and returns a sequence of values returned by all tasks. Parameter … is the value passed to .dfx/.splx.
A subtask that terminates due to abnormal termination will be given to another node (one that does not have a task to process) to handle. The subtask fails if there isn’t an available node. It is regarded as an abnormal termination if a subtask is given to an unavailable node, and by default, the task will be re-allocated in order. The ith subtask is given to hs.m@r(i) until each node reaches the specified workload limit. The allocation begins again when one of the nodes returns its first completed task and continues until all subtasks are allocated.
rdfx is a script used for performing reduce action and can be omitted. It has two parameters – the current cumulative value and the current return value, which will be made the new cumulative value; the initial cumulative value is null. When the parameter is present, the function returns a sequence of values returned by all nodes in the order of node list hs.
Parameter:
|
spl |
A script file .dfx/.splx, for which an absolute or a relative path can be set. The relative path is the Search Path under the Tool->Option-> [Environment] menu |
|
… |
The parameter for passing value to .dfx/.splx. It is usually in the form of a sequence. The number of parameters to be passed to .dfx/.splx is the number of the sequences. The parallel algorithm will divide a computational task into multiple subtasks according to the length of the parameter sequence and pass each member of the sequence to the corresponding subtask as the parameter value of .dfx/.splx |
|
hs |
The server sequence in which each server is represented by a string in the form of "IP address:port number", such as "192. 168. 0. 86: 4001"; The absence of IP address means another process in the current physical machine; the absence of both IP address and port number while maintaining ":" means the current process |
|
rdfx |
A dfx script used that uses two parameters; it is used to perform reduce action, and can be omitted |
Option:
|
@a |
Enable a random allocation |
|
@l |
Enable allocating one task to all available nodes; the task is completed as long as one of the nodes does it successfully, and other nodes are thus terminated |
Example:
test.dfx is the node deployment file. The sequence of node machines is ["192.168.31.165:8281","192.168.31.39:8281"].
1. Single parameter
Below is test.dfx:
|
|
A |
B |
|
1 |
=connect("demo").query("select * from SCORES where SUBJECT=?",arg1) |
|
|
2 |
return A1 |
return A1.(SCORE) |
Below is reduce.dfx:
|
|
A |
|
|
1 |
=a|b |
a and b are dfx file’s parameters; a represents the current cumulative value and b is the current returned value. |
|
|
A |
|
|
1 |
=["192.168.31.165:8281","192.168.31.39:8281"] |
A sequence of nodes. |
|
2 |
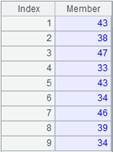
=callx("test.dfx",["English","Math","PE"];A1) |
Allocate the task in turn and return a sequence of values returned by all substasks.
|
|
3 |
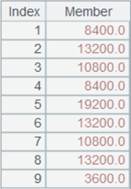
=callx("test.dfx",["English","Math","PE"];A1;"reduce.dfx") |
Allocate the task in turn, perform reduce action, and return a sequence of values returned by all substasks.
|
|
4 |
=callx@a("test.dfx",["English","Math","PE"];A1;"reduce.dfx") |
Use @a option to allocate subtasks randomly.
|
|
5 |
=callx@1("test.dfx",["English","Math","PE"];A1) |
Use @1 option to terminate the other subtasks if one node finishes its job.
|
|
6 |
=callx("test.dfx",["English","Math","PE"];":8281") |
Execute script at port 8281 on the current machine. |
|
7 |
=callx("test.dfx",["English","Math","PE"];":") |
Execute script in the current process. |
2. Multiple parameters
reduce.dfx is the same, and test.dfx is as follows:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
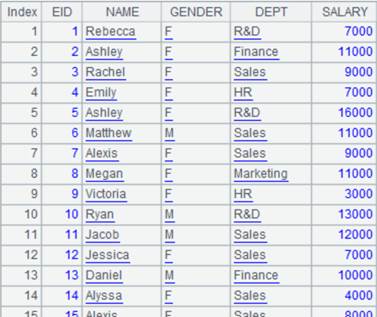
=A1.query("select * from EMPLOYEE where EID in (?) and GENDER=?",arg1,arg2) |
|
3 |
=A1.close() |
|
4 |
return A2 |
|
|
A |
|
|
1 |
=["192.168.31.165:8281","192.168.31.39:8281"] |
A sequence of nodes. |
|
2 |
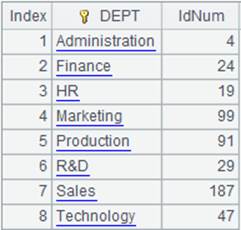
=callx("test.dfx",[1,20,6,14,5],"F";["192.168.31.165:8281"]) |
Pass two parameters [6,F] to one node, and the query result is null.
|
|
3 |
=callx("test.dfx",[1,20,6,14,5],"F";A1;"reduce.dfx") |
Send multiple parameters to multiple nodes and distribute subtasks in turn, that is, giving [1,F], [6,F] and [5,F] to node "192.168.31.165:8281" and [20,F] and [14,F] to node "192.168.31.39:8281".
|
|
4 |
=callx("test.dfx",[[1,20,6,14,5],[22,33,44]],"F";A1) |
When multiple nodes receive the same value for one parameter, the parameter can be passed in the form of a single value, that is, passing [ [1,20,6,14,5],F ] to node "192.168.31.165:8281" and [[22,33,44],F] to node "192.168.31.39:8281". |
|
5 |
=callx("test.dfx",[[1,20,6,14,5],[22,33,44]],["F","M"];A1) |
When multiple nodes receive the same parameter with different values, the parmeter will be passed in the form of a sequence, that is, passing [ [1,20,6,14,5],F ] to node "192.168.31.165:8281" and [[22,33,44],M] to node "192.168.31.39:8281". |