group()
Here’s how to use group() function.
A.group(x i ,… )
Description:
Perform equi-grouping according one or more fields or expressions.
Syntax:
A.group(xi,…)
Note:
The function performs equi-grouping on a sequence according to expression xi,…. The result is a sequence/record sequence consisting of groups.
Option:
|
@o |
Group records by comparing adjacent ones, which is equal to the merging operation, and the result set won’t be sorted |
|
@1 |
Get the first record of each group to form a record sequence and return it (Please note that 1 is a number instead of a letter); can work with @v option |
|
@n |
x gets assigned with group numbers which can be used to define the groups; discard groups that make x<1. @n and @0 are mutually exclusive |
|
@u |
Do not sort the result set by x. It doesn’t work with @o/@n |
|
@i |
x is a Boolean expression. If the result of x is true, then start a new group. This option is equivalent to A.group@o(a+=if(x,1,0)), in which a=0 and there is only one x |
|
@0 |
Discard the group over which the result of grouping expression x is null; discard empty groups when @n is also present. Use it when there’s only one expression x |
|
@s |
Perform a concatenation of sequences/records sequences after the grouping. It is equivalent to A.group(xi,…).conj(); can work with @v option |
|
@p |
Return a sequence of integer sequences, each of which contains the positions of members in each group in sequence A |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@v |
When parameter A is a pure table sequence, return a set of pure table sequences |
Parameter:
|
A |
A sequence |
|
xi |
Grouping expression |
Return value:
Sequence / Record sequence
Example:
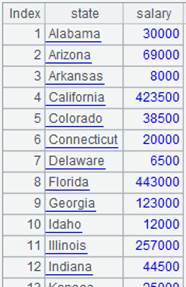
Group a sequence:
|
|
A |
|
|
1 |
[6,9,12,15,16,5,1,7,8] |
|
|
2 |
=A1.group(~%2) |
[[6,12,16,8],[ 9,15,5,1,7]] The series is divided into two groups. Divide the number of members in both groups by 2, one of the remainders is 0 and the other is 1. |
|
3 |
=A1.group(~%2,~%3) |
[[6,12],[16],[8],[9,15],[1,7],[5]]. Group the series according to multiple expressions. |
|
4 |
=[6,9,16,5,1,7,8].group@s(~%2) |
Divide the sequence into a group of odd numbers and a group of even numbers, and then concatenate them.
|
|
5 |
=A1.group((#-1)\3) |
Group sequence A1 every 3 members.
|

Reuse the grouping result:
|
|
A |
|
|
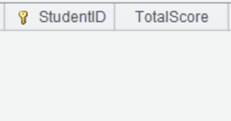
1 |
=demo.query("select NAME,BIRTHDAY,GENDER from EMPLOYEE") |
|
|
2 |
=A1.group(GENDER) |
Group A1’s table sequence by GENDER:
[Each group is a sequence:
|
|
3 |
=A2.new(GENDER:Gender,~.count():Number) |
Count members of each group. |
|
4 |
=A2.new(GENDER:Gender,~.avg(age(BIRTHDAY)):Average) |
Get different statistical results using the same grouping result. |



Group data by multiple fields:
|
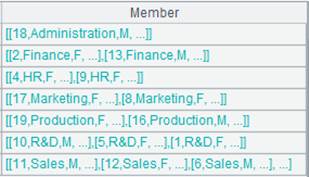
|
A |
|
|
1 |
=demo.query("select NAME,GENDER,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
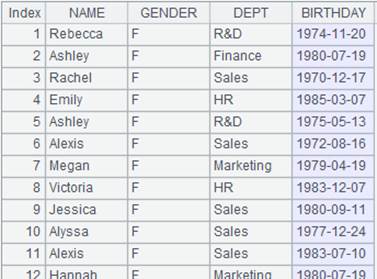
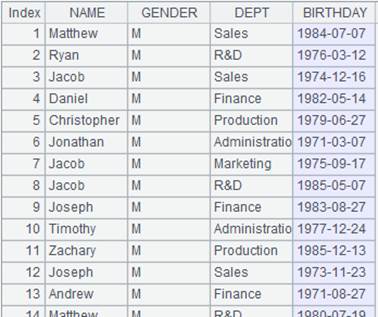
=A1.group(GENDER,DEPT) |
Group records by multiple fields. |
|
3 |
=A1.group@o(GENDER) |
Records won’t be sorted; only the adjacent ones will be compared and group them together if they match. Same records that are not adjacent may be put into different groups, so there may be overlapped groups and the returned result is a set of sequences.
|
|
4 |
=A1.group@1(GENDER) |
Return the first record of each group.
|
|
5 |
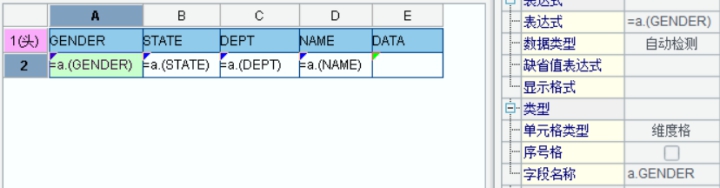
=A1.group@n(if(GENDER=="F",1,2)) |
x gets assigned with group numbers which can be used to define the groups directly. [[Rebecca,Ashley,Rachel,…],[Matthew,Ryan,Jacob,…]] |
|
6 |
=A1.group@u(GENDER,DEPT) |
Do not sort result set by the sorting field. |
|
7 |
=A1.group@i(GENDER=="F") |
Start a new group when GENDER=="F". |
|
8 |
=A1.group@p(GENDER,DEPT) |
Return a sequence of integer sequences, each of which contains the positions of records in a group (grouped by GENDER field and DEPT field) in the original table sequence. |
|
9 |
=file("D:\\Salesman.txt").import@t() |
|
|
10 |
=A9.group@0(Gender) |
Group the table sequence by GENDER field, while discarding groups with null values. |
|
11 |
=file("D:/emp10.txt").import@t() |
For data fiel emp10.txt, every 10 records are ordered by DEPT.
|
|
12 |
=A11.group@h(DEPT) |
As A11 is segmented and ordered by DEPT, @h option is used to speed up grouping.
|
|
13 |
=A1.group@n(if(DEPT=="HR":1,DEPT=="Sales":2;0)) |
Use @n option to discard groups of records that make the grouping expression less than 1. That is, give up those where DEPT is neither HR nor Sales.
|







When parameter A is a table sequence:
|
|
A |
|
|
1 |
=demo.query@v("select * from EMPLOYEE order by GENDER,DEPT ") |
Return a pure table sequence. |
|
2 |
=A1.group@v(GENDER,DEPT) |
@v option enables returning a set of pure table sequences. |
Related functions:
A.group(x:F,...;y:G,… )
Description:
Group a sequence and then perform aggregate operations.
Syntax:
A.group(x:F,...;y:G,…)
Note:
The function groups a sequence according to a single or multiple fields/expressions x, aggregates each group of data and generates a new table sequence made up of fields F,... G,… and ordered by grouping expression x. G field gets values by computing y over each group.
Option:
|
@o |
Group records by comparing adjacent ones, which is equal to the merging operation, and the result set won’t be sorted |
|
@n |
x gets assigned with group numbers which can be used to define the groups. @n and @o are mutually exclusive |
|
@u |
Do not sort the result set by x. It doesn’t work with @o/@n |
|
@i |
x is a Boolean expression. If the result of x is true, then start a new group. There is only one x |
|
@0 |
Discard the group over which the result of grouping expression x is null |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@t |
Return an empty table sequence with data structure if the grouping and aggregate operation over the sequence returns null |
|
@s |
Summarize data cumulatively |
Parameter:
|
A |
A sequence |
|
x |
Grouping expression. If omitting x:F, aggregate the whole set without grouping; in this case “;” must not be omitted |
|
F |
Field name of the result table sequence |
|
G |
Names of summary fields in the result table sequence |
|
y |
Aggregate expression in which ~ is used to reference a group |
Return value:
Sequence
Example:
|
|
A |
|
|
1 |
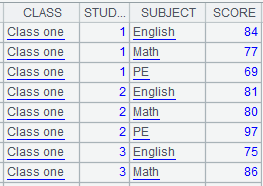
=demo.query("select * from SCORES") |
|
|
2 |
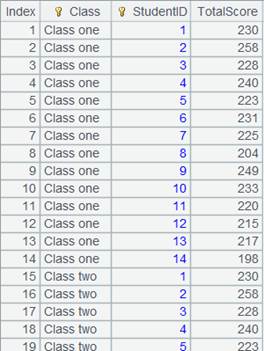
=A1.group(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
|
|
3 |
=A1.group@o(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
Only the adjacent ones will be compared and group them together if they are the same. The result set won’t be sorted. |
|
4 |
=demo.query("select * from STOCKRECORDS where STOCKID<'002242'") |
|
|
5 |
=A4.group@n(if(STOCKID=="000062",1,2):StockID;~.sum(CLOSING):TotalPrice) |
x gets assigned with group numbers. |
|
6 |
=A1.group(;~.sum(SCORE):TotalScore) |
Parameters x:F are omitted, so compute the total score of all the students. |
|
7 |
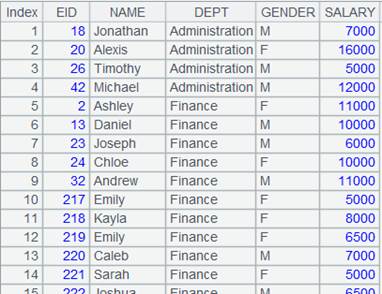
=demo.query("select * from EMPLOYEE") |
|
|
8 |
=A7.group@u(STATE:State;~.count(STATE):TotalScore) |
Do not sort result set by the sorting field. |
|
9 |
=A7.group@i((GENDER=="F"):IsF;~.count():Number) |
Start a new group when GENDER=="F". |
|
10 |
=file("D:\\Salesman.txt").import@t() |
|
|
11 |
=A10.group@0(Gender:Gender;~.sum(Age):Total) |
Discard the groups where GENDER values are null. |
|
12 |
=file("D:/emp10.txt").import@t() |
For
data file emp10.txt, every 10
records are ordered by DEPT |
|
13 |
=A12.group@h(DEPT:dept;~.sum(SALARY):bouns) |
As A12 are segmented and ordered by DEPT, @h option is used to speed up grouping.
|
|
14 |
=demo.query("select * from EMPLOYEE where EID > 500") |
Return an empty table sequence. |
|
15 |
=A14.group@t(STATE:State;~.count(STATE):TotalScore) |
Return an empty table sequence with the data structure.
|
|
16 |
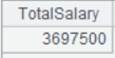
=demo.query("select * from employee").group@s(DEPT;sum(SALARY):TotalSalary) |
Perform aggregation cumulatively.
|





Related functions:
ch.g roup()
Description:
Attach an operation of grouping records in a channel by comparing each one with its next and return the original channel.
Syntax:
ch.group(x,…)
Note:
The function attaches a computation to channel ch, which will group its records by expression x, whose value is compared only with the directly next each record, and returns the original channel ch. This is equivalent to a merge and ch should be ordered.
This is an attachment computation.
Option:
|
@i |
With this option and with grouping expression x being a Boolean expression, start a new group if the result of x is true. Be sure there’s only one x in this case |
|
@1 |
Get the first record of every group to form a record sequence and return it to the original channel (here it is number 1 rather than letter l) |
Parameter:
|
ch |
A channel |
|
x |
Grouping expression |
Return value:
Channel
Example:
|
|
A |
|
|
1 |
=demo.cursor("select EID,GENDER,DEPT,NAME,SALARY from EMPLOYEE").sortx(GENDER,DEPT) |
Return a cursor ordered by by GENDER and DEPT fields. |
|
2 |
=channel() |
Create a channel. |
|
3 |
=A2.group(GENDER,DEPT) |
Attach a computation to channel A2, which will group its records by GENDER and DEPT. |
|
4 |
=A2.fetch() |
Execute the result set function in channel A2 and keep the current data in channel. |
|
5 |
=A1.push(A2) |
Be ready to push cursor A1’s data to channel A2, but the action needs to wait. |
|
6 |
=A1.skip() |
Fetch data from cursor A1 while pushing data into the channel to execute the attached computation and keep the result. |
|
7 |
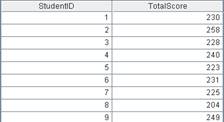
=A2.result() |
Get channel A2’s result:
|
|
|
A |
|
|
1 |
=demo.cursor("select EID,GENDER,DEPT,NAME,SALARY from EMPLOYEE").sortx(DEPT) |
Return a cursor ordered by DEPT field |
|
2 |
=channel() |
Create a channel. |
|
3 |
=channel() |
Create a channel. |
|
4 |
=A2.group@1(DEPT) |
Attach a computation to channel A2, which will group its records by DEPT field and use @1 option to get the first record of every group to form a record sequence, and return the original channel A2. |
|
5 |
=A2.fetch() |
Execute the result set function in channel A2 and keep the current data in channel. |
|
6 |
=A3.group@i(GENDER=="F") |
Attach a computation to channel A3, which will group its records by DEPT field and use @i option to create a new group whenever DEPT =="HR" is met, and return the original channel A3. |
|
7 |
=A3.fetch() |
Execute the result set function in channel A3 and keep the current data in channel. |
|
8 |
=A1.push(A2,A3) |
Be ready to push the data in A1’s cursor to channels A2 and A3, but the action needs to wait. |
|
9 |
=A1.skip() |
Fetch data from cursor A1 while pushing data into the channel to execute the attached computation and keep the result. |
|
10 |
=A2.result() |
Get channel A2’s result:
|
|
11 |
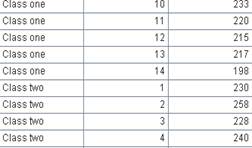
=A3.result() |
Get channel A3’s result:
|

cs.g roup()
Description:
Attach the action of grouping records by comparing only adjacent records to the cursor and return the original cursor.
Syntax:
cs.group(x,…)
Note:
The function attaches a computation to cursor cs, which groups cursor cs by expression x, whose value is compared only with the adjacent records, and returns the original cursor. Cursor cs should be ordered. The operation is equal to a merge and supports multicursors.
This is a delayed function.
Option:
|
@i |
x is a Boolean expression. Begin a new group when a record makes it return true. In this case there should be only one x |
|
@1 |
Get the first record of every group to form a record sequence and return it to the original cursor; here it is number 1 instead of letter l |
|
@v |
When parameter cs is a cursor based on pure table sequence, copy each grouped subset as a new pure table sequence |
Parameter:
|
cs |
A cursor or multicursor |
|
x |
Grouping expression |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
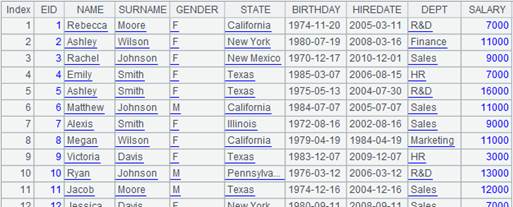
=demo.cursor("select * from EMPLOYEE").sortx(GENDER,DEPT) |
Return a cursor where data is ordered by GENDER and DEPT. |
|
2 |
=A1.group(GENDER,DEPT) |
Attach a computation to cursor A1, which puts records in the same group when two neighboring records have same GENDER and DEPT values, and return the original cursor. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed (fetch data in batches when there is a huge amount of data):
|

When @i option is present:
|
|
A |
|
|
1 |
=demo.cursor("select * from STOCKRECORDS where STOCKID='000062' ").sortx(DATE) |
Return a cursor where data is ordered by DATE. |
|
2 |
=A1.group@i(CLOSING<CLOSING[-1]) |
Attach a computation to cursor A1, which, with @i option, creates a new group whenever CLOSING value in the current record is less than that in the previous record, and return the original cursor. |
|
3 |
Fetch data from cursor A1 where A2’s computation is executed:
|

When @1 option is present:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,HIREDATE from EMPLOYEE").sortx(DEPT,HIREDATE) |
Return a cursor where data is ordered by DEPT and HIREDATE. |
|
2 |
=A1.group@1 (DEPT) |
Attach a computation to cursor A1, which, with @1 option, groups records in the cursor by DEPT and gets the first record in each group, and return the original cursor. |
|
3 |
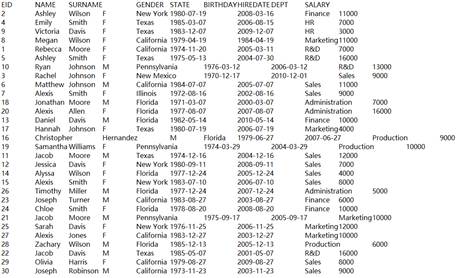
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|
When parameter cs is a cursor based on pure table sequence:
|
|
A |
|
|
1 |
=demo.cursor@v("select * from EMPLOYEE order by GENDER,DEPT") |
Return a cursor of pure table sequence. |
|
2 |
=A1.group@v(GENDER,DEPT) |
Attach a computation to cursor A1, which, with @v option, copies each grouped subset as a new pure table sequence, and return the original cursor. |
|
3 |
=A1.fetch() |
Get the number of groups in cursor A1 where A2’s computation is executed. |
Related function:
cs.group()
Description:
Group a cluster cursor by comparing each record with its next neighbor.
Syntax:
cs.group(x,…)
Note:
The function groups records in ordered cluster cursor cs according to expression x by comparing the value of x only with its next neighbor, and returns the cluster cursor containing a sequence of groups. The operation is equivalent to a merge and supports multicursors.
Parameter:
|
cs |
A cluster cursor |
|
x |
Grouping expression; use comma to separate multiple grouping fields or expressions |
Return value:
The grouped cluster cursor
Example:
|
|
A |
|
|
1 |
=file("employees.ctx","192.168.0.111:8281") |
Below is employees.ctx ordered by DEPT field:
|
|
2 |
=A1.open() |
Create a cluster composite table. |
|
3 |
=A2.cursor() |
Return a cluster cursor. |
|
4 |
=A3.group(DEPT) |
Group the cluster cursor by DEPT and return the grouped cluster cursor. |
|
5 |
=A4.fetch() |
|


cs.group(x:F,…;y:G,…)
Description:
Attach the action of grouping and aggregating records by comparing only adjacent records to a cursor and return the original cursor.
Syntax:
cs.group(x:F,...;y:G,…)
Note:
The function attaches a computation to cursor cs, which groups records in cursor cs according to expression x whose results are values of field F and computes aggregate expression y over each group, whose results are values of field G, and forms a table sequence consisting of F,... G,…. Fields to return to the original cursor cs. The function supports a multicursor.
cs is ordered by x whose values are only compared with their neighbors; and the resulting set won’t be sorted again.
This is a delayed function.
Parameter:
|
cs |
A cursor |
|
x |
Grouping expression |
|
F |
Field name |
|
G |
Aggregation field name |
|
y |
Aggregate expression |
Option:
|
@s |
Cumulative aggregation |
|
@q(x:F,…;x’:F’,…; y:G,…) |
Used when parameter cs is ordered by x,… and only fields after it need to be sorted; support in-memory sorting |
|
@sq(x:F,…;x’:F’,…; y:G,…) |
Only sort without grouping when parameters y:G are absent, and perform cumulative aggregation when the parameters are present; @s works only when @q option is present |
|
@e |
Return a table sequence consisting of results of expression y to the original cursor; grouping expression x is a field of cs and y is function on cs; the result of computing y must be one record of cs; and y only supports maxp, minp and top@1 functions when it is an aggregate expression; When @sev options work together, the function returns a pure table sequence |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES").sortx(CLASS,STUDENTID) |
Return a cursor whose data is ordered by CLASS and STUDENTID fields; below is the content:
|
|
2 |
=A1.group(CLASS:Class,STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
Attach a computation to cursor A1, which groups records in the cursor by comparing neighboring CLASS and STUDENTID values and computes total scores, which are made TotalScore field values, in each group, and return the original cursor. |
|
3 |
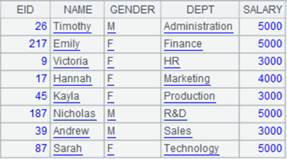
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|

When @q option works:
|
|
A |
|
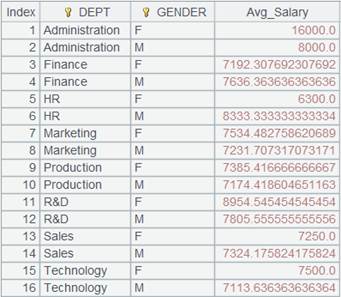
|
1 |
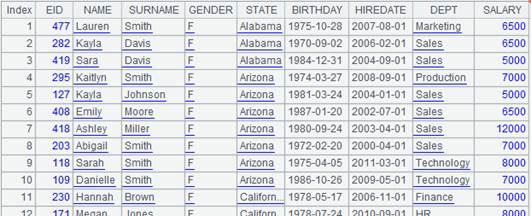
=demo.cursor("select EID,NAME,DEPT,GENDER,SALARY from EMPLOYEE ").sortx(DEPT) |
Return a cursor whose data is ordered by DEPT field; below is the content:
|
|
2 |
=A1.group@q(DEPT;GENDER;~.avg(SALARY):Avg_Salary) |
Attach a computation to cursor A1 that is ordered by DEPT and where only GENDER field needs to be ordered; @q option is used to enable an in-memory sorting, and return the original cursor. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|

@sq options work to enable sorting without aggregation:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,SALARY from EMPLOYEE ").sortx(DEPT) |
Return a cursor whose data is ordered by DEPT field; below is the content:
|
|
2 |
=A1.group@sq(DEPT;GENDER) |
Attach a computation to cursor A1 ordered only by DEPT; here the function does not specify the aggregate parameter is absent and use @sq options to sort without grouping, and returns the original cursor. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|

With @e option, return a table sequence consisting of results of expression y to the original cursor:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,SALARY from EMPLOYEE ").sortx(DEPT) |
Return a cursor whose data is ordered by DEPT field; below is the content: |
|
2 |
=A1.group@e(DEPT;~.maxp(SALARY)) |
Attach a computation to cursor A1; the function work with @e option to return the result records of computing maxp(SALARY) to the original cursor. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|

cs.group(x:F,…;y:G,…)
Description:
Group records of a cluster cursor by comparing each with its next neighbor, perform aggregation over each group and return the original cluster cursor.
Syntax:
cs.group(x:F,...;y:G,…)
Note:
The function groups records in cluster cursor cs according to expression x, by which cs is ordered and whose values are only compared with their neighbors while aggregate expression y is calculated. The resulting set won’t be sorted again. After grouping, records in the original cursor will have fields F,... G,…. Values of G field are the results of computing expression y over each group. The function supports a multicursor.
Parameter:
|
cs |
A cluster cursor |
|
x |
Grouping expression |
|
F |
Field name |
|
G |
Field to be aggregated |
|
y |
Aggregation expression |
Return value:
A cluster cursor
Example:
|
|
A |
|
|
1 |
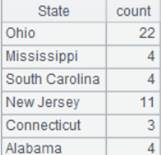
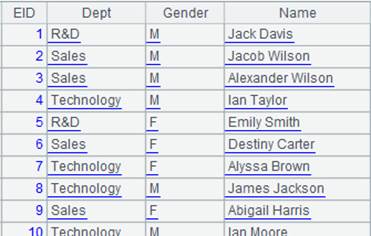
=file("employees.ctx","192.168.0.111:8281") |
employees.ctx is ordered by DEPT. Its content is as follows:
|
|
2 |
=A1.open() |
Open the cluster composite table. |
|
3 |
=A2.cursor() |
Return a cluster cursor. |
|
4 |
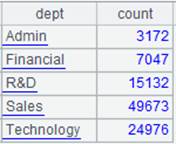
=A3.group(DEPT:dept;count(NAME):count) |
Group records by DEPT and perform aggregation on each group and return result to the original cluster cursor. |
|
5 |
=A4.fetch() |
|
T. group ()
Description:
Define a computation, which will group records by comparing the grouping field in each with its next neighbor, on a pseudo table and return a new pseudo table.
Syntax:
T.group(xi,…)
Note:
The function defines a computation on pseudo table T that should be ordered, which will group records by grouping expression xi whose value will only be compared with its next neighbor – which amounts to a merge, and return a new pseudo table.
Parameter:
|
T |
A pseudo table |
|
xi |
Grouping expression; use comma to separate multiple grouping fields or expressions |
Option:
|
@i |
x is a Boolean expression. Begin a new group when a record makes it return true. In this case there should be only one x |
|
@1 |
Get the first record of every group to form a record sequence and return it; here it is number 1, instead of letter l |
|
@v |
Store the composite table in the column-wise format when loading it the first time, which helps to increase performance |
Return value:
Pseudo table object
Example:
|
|
A |
|
|
1 |
=create(file).record(["D:/file/pseudo/empT.ctx"]) |
|
|
2 |
=pseudo(A1) |
Generate a pseudo table object, whose data is as follows:
|
|
3 |
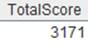
=A2.group(GENDER,DEPT) |
Define a computation on A2’s pseudo table, which will put records where both GENDER and DEPT values are same into the same group, and return a new pseudo table. |
|
4 |
=A3.import() |
Import data from A3’s pseudo table while executing the computation in A3 defined on A2’s pseudo table, and return the following pseudo table:
|
|
5 |
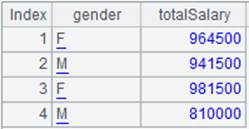
=A2.group@i(GENDER=="F") |
With @i option, create a new group whenever the record meets the condition GENDER=="F". |
|
6 |
=A5.import() |
Get data from A5’s pseudo table.
|
|
7 |
=A2.group@1(GENDER) |
With @1 option, return the first record of each group. |
|
8 |
=A7.cursor().fetch() |
Fetch data from A7’s pseudo table:
|
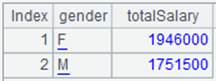
T.group(x:F,…;y:G,…)
Description:
Define a computation, which will group records by comparing the grouping field in each with its next neighbor and perform aggregation over each group, on a pseudo table and return a new pseudo table.
Syntax:
Note:
The function defines a computation on pseudo table T, which will group its records by expression x whose values are those of field F, compute aggregate expression y whose values are those of field G, and returns a new pseudo table consisting of fields F,... G,….
Pseudo table T is ordered by expression x whose values are only compared with their next neighbors, and the result set won’t be sorted again.
Parameter:
|
T |
A pseudo table |
|
x |
Grouping expression |
|
F |
Field name |
|
G |
Aggregation field name |
|
y |
Aggregate expression |
Option:
|
@s |
Cumulative aggregation |
|
@q(x:F,…;x’:F’,…;…) |
Used when parameter T is ordered by x,… and only fields after it need to be sorted; support in-memory sorting |
|
@sq(x:F,…;x’:F’,…;…) |
Only sort without grouping when parameters y:G are absent, and perform cumulative aggregation when the parameters are present; @s works only when @q option is present |
|
@e |
Return a pseudo table consisting of results of expression y; grouping expression x is a field of T and y is function on T; the result of computing y must be one record of T; and y only supports maxp, minp and top@1 functions when it is an aggregate expression |
Return value:
Pseudo table
Example:
|
|
A |
|
|
1 |
=create(file).record(["scores-g.ctx"]) |
scores-g.ctx is a composite table file ordered by STUDENTID; its content is as follows:
|
|
2 |
=pseudo(A1) |
Generate a pseudo table from composite table A1. |
|
3 |
=A2.group(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
Define a computation on A2’s pseudo table, which will group pseudo table A2 by STUDENTID and compute total SCORE values in each group, and return a new pseudo table. |
|
4 |
=A3.import() |
Import data from A3’s pseudo table while executing the computation defined on A2’s pseudo table in A3, and return the following pseudo table:
|


|
|
A |
|
|
1 |
=create(file).record(["emp-g.ctx"]) |
emp-g.ctx is a composite table file ordered by DEPT; its content is as follows:
|
|
2 |
=pseudo(A1) |
Generate a pseudo table from composite table A1. |
|
3 |
=A2.group@q(DEPT;GENDER) |
Define a computation on A2’s pseudo table – as the pseudo table is already ordered by DEPT, the function only sorts by GENDER during grouping – and return a new pseudo table:
|
|
4 |
=A3.cursor().fetch() |
Fetch data from A3’s pseudo table while executing the computation defined on A2’s pseudo table in A3, and return the following pseudo table:
|
|
5 |
=A2.group@qs(DEPT:DEPT;GENDER:GENDER) |
Define a computation on A2’s pseudo table, which will only sort records without grouping since parameters y:G are absent, and return a new pseudo table.
|
|
6 |
=A5.import() |
Import data from A5’s pseudo table while executing the computation defined on A2’s pseudo table in A5, and return the following pseudo table:
|
|
7 |
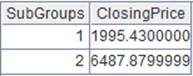
=A2.group@qs(DEPT:DEPT;GENDER:GENDER;count(GENDER):count) |
Define a computation on A2’s pseudo table, which will Perform cumulative aggregation as parameters y:G are present, and return a new pseudo table.
|
|
8 |
=A7.import() |
Import data from A7’s pseudo table while executing the computation defined on A2’s pseudo table in A7, and return the following pseudo table:
|
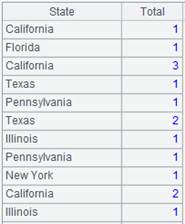
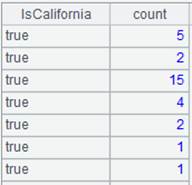
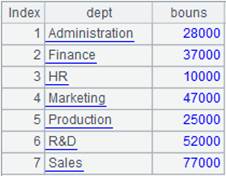
With @e option, return a pseudo table consisting of results of expression y:
|
|
A |
|
|
1 |
=create(file).record(["emp-g.ctx"]) |
Below is content of composite table emp-g.ctx:
|
|
2 |
=pseudo(A1) |
Generate a pseudo table from composite table A1. |
|
3 |
=A2.group@e(DEPT;~.minp(SALARY)) |
Define a computation on A2’s pseudo table, which, with @e option, will return a pseudo table consisting of result records of computing minp(SALARY).
|
|
4 |
=A3.fetch().cursor() |
Fetch data from A3’s pseudo table while executing the computation defined on A2’s pseudo table in A3, and return the following pseudo table:
|