new()
Here’s how to use new() function.
new ()
Description:
Generate a record according to the specified field name and field value.
Syntax:
new(xi:Fi,…)
Note:
The function generates a record made up of one field whose name is Fi and value is xi.
Parameter:
|
xi |
Field value |
|
Fi |
Field name |
Option:
|
@t |
Enable returning result as a table sequence |
Return value:
A record or table sequence
Example:
|
|
A |
|
|
1 |
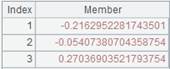
=new(1:ID,"ZHS":name) |
Generate a record:
|
|
2 |
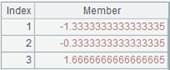
=new@t(1:ID,"ZHS":name) |
Use @t option to generate a table sequence made up of one record:
|

A.new( x i : F i ,… )
Description:
Perform computation on a sequence to generate a new table sequence.
Syntax:
A.new(xi:Fi,…)
Note:
The function computes expression xi on each member of sequence A and generate a new table sequence having same number of records as A and using xi as field values and Fi as field names.
Parameter:
|
Fi |
Field names of the result table sequence; use xi when the parameter is absent; use the original field names when xi is #i |
|
xi |
An expression whose results are field values; if omitted, field values will be nulls a, and when is absent, :Fi must not be omitted |
|
A |
A sequence |
Option:
|
@m |
Use parallel processing to speed up computation |
|
@i |
Won’t generate a record if the result of expression xi is null |
|
@o |
When parameter A is a pure table sequence, directly reference an old column if it is unmodified instead of generating a new column; sequence A will also be updated when the result table sequence is updated |
|
@z |
Perform an inverse operation; only apply to non-pure sequences |
Return value:
Table sequence
Example:
Ø Generate from an individual table sequence
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
=A1.new(EID:EmployeeID,NAME, #3:dept) |
Generate a new table sequence directly. If the field names are the same as those of A1, Fi can be omitted. |
|
3 |
=A1.new(NAME,age(BIRTHDAY):AGE) |
Generate the new table sequence by computing new field values. |
|
4 |
=A1.new@m(NAME,age(BIRTHDAY):AGE) |
Use @m option to increase performance of big data handling. |
|
5 |
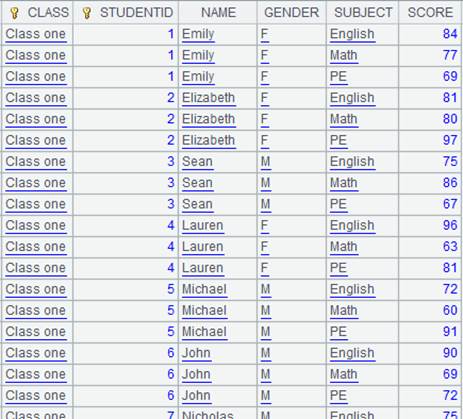
=file("D:\\txt_files\\data1.txt").import@t() |
Below is the file data1.txt:
|
|
6 |
=A5.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
If the SCORE value is null, the corresponding record won’t be generated.
|


Ø Generate from a pure table sequence
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE").i() |
Return a pure table sequence. |
|
2 |
=A1.new@o(EID,NAME, #3:dept) |
With @o option, directly reference the unmodified old columns instead of generating new ones. |
|
3 |
=A2(1).NAME="aaa" |
Modifying column values results in the modification of source table; below is A2’s result after execution:
And A1’s result is as follows:
|


Ø Generate from multiple table sequences of the same order
|
|
A |
|
|
1 |
=create(Name,Chinese).record(["Jack",99,"Lucy",90]) |
|
|
2 |
=create(Name,Math).record(["Jack",89,"Lucy",96]) |
|
|
3 |
=A1.new(Name:Name,Chinese:Chinese,A2(#).Math:Math) |
Use A2(#) to get the record from A2 in the same position.
|



Ø Perform the inverse operation:
|
|
A |
|
|
1 |
=demo.query("select * from SCORES ") |
Return a table sequence:
|
|
2 |
=A1.new(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
Perform iterative operation in a loop function to get cumulative total on SCORE values of records having same CLASS value and STUDENTID value, use the results as values of F1 column and return a new table sequence as follows:
|
|
3 |
=A1.new@z(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
Use @z option to perform an inverse operation:
|



Related function:
ch.n ew()
Description:
Attach a computation of getting field values to a channel and return the original channel.
Syntax:
ch.new(xi:Fi,…)
Note:
The function attaches a computation to channel ch, which will compute expression xi over each of its records and form a new table sequence having same number of records as in ch, with field names being Fi that uses results of xi as values, and returns the original ch.
This is an attachment computation.
Parameter:
|
ch |
A channel |
|
xi |
An expression, whose values are used as new field values. It is treated as null if omitted; in that case, parameter : Fi can’t be omitted. The sign # is used to represent a field with a ordinal number |
|
Fi |
Field name in the given channel; use the identifiers parsed from expression xi if it is omitted |
Option:
|
@i |
Won’t generate the corresponding record when the result of computing expression xi is null |
Return value:
Channel
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES") |
Return a cursor. |
|
2 |
=file("D:\\txt_files\\data1.txt").cursor@t() |
Below is data1.txt:
|
|
3 |
=channel() |
Create a channel. |
|
4 |
=channel() |
Create a channel. |
|
5 |
=A3.new(CLASS,#2:ID,SCORE+5:newScores) |
Attach a computation to channel A3 and return the original channel. #2:ID means renaming the second field of A3 ID; compute SCORE+5 on SCORE field, rename the column newScores, and form a new table sequence consisting of ID field, CLASS field and newScores field. |
|
6 |
=A3.fetch() |
Execute the result set function in channel A3 and keep the current data in channel. |
|
7 |
=A4.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
Attach a computation to channel A4, which uses @i option to not to generate the corresponding record if the result of computing a SCORE value is null, and return the original channel. |
|
8 |
=A4.fetch() |
Execute the result set function in channel A4 and keep the current data in channel |
|
9 |
=A1.push(A3) |
Be ready to push data in A1’s cursor to A3’s channel, but the action needs to wait. |
|
10 |
=A2.push(A4) |
Be ready to push data in A2’s cursor to A4’s channel, but the action needs to wait. |
|
11 |
=A1.fetch() |
Fetch data from cursor A1 while pushing data to channel A3 to execute the attached computation and keep the result. |
|
12 |
=A3.result() |
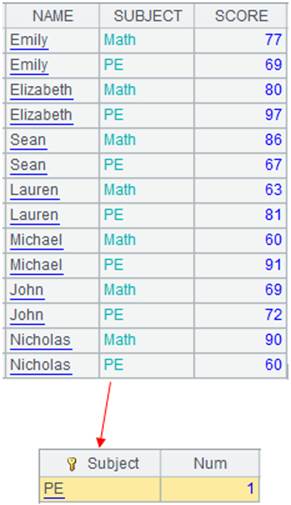
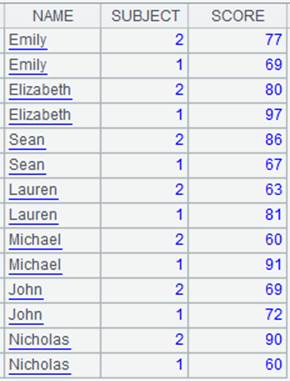
Get channel A3’s result:
|
|
13 |
=A2.fetch() |
Fetch data from cursor A2 while pushing data to channel A4 to execute the attached computation and keep the result. |
|
14 |
=A4.result() |
Get channel A4’s result:
|
cs.n ew()
Description:
Attach the action of computing new field values to a cursor and return the original cursor.
Syntax:
cs.new(xi:Fi,…)
Note:
The function attaches a computation to cursor cs, which computes expression xi against each record in cursor cs to generate a new table sequence having same number of records as that in cs, consisting of the field Fi whose values are results of expression xi,, and returns the table sequence to the original cursor.
This is a delayed function.
Parameter:
|
cs |
A cursor |
|
xi |
An expression, whose values are uses as the new field values. It is treated as null if omitted; in that case,Fi can’t be omitted. The sign # is used to represent a field with an ordinal number |
|
Fi |
Field name of cs; use the identifiers parsed from expression xi if it is omitted |
Option:
|
@i |
Won’t generate a record if the result of expression xi is null |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
=connect("demo").cursor("select top 5 * from SCORES where SCORE<60") |
|
|
2 |
=A1.new(#2:ID,CLASS,SCORE+5:newScores) |
Attach the action of computing an expression to cursor A1; #2:ID means renaming the 2nd field in cursor A1 ID; the attached computation will compute expression SCORE+5 on SCORE field and rename the field newScores and form a table sequence consisting of ID, CLASS and newScores to return to cursor A1. |
|
3 |
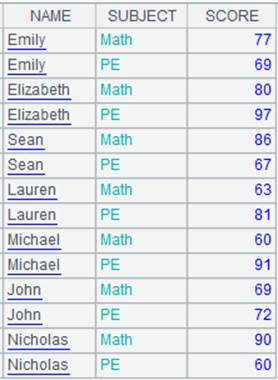
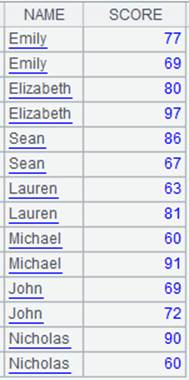
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is already executed (it would be better to fetch data in batches when a huge amount of data is involved):
|
When @i option works:
|
|
A |
|
|
1 |
=file("D:\\txt_files\\data1.txt").cursor@t() |
Below is
the file data1.txt: |
|
2 |
=A1.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
With @i option, if the SCORE value is null, the corresponding record won’t be generated. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is already executed:
|

T.new(A/cs:K…,x:C,…;wi)
Description:
Return a table sequence/cursor consisting of the specified fields according to the correspondence between the composite table’s key (/dimension) and the corresponding field in the table sequence/cursor.
Syntax:
T.new(A/cs:K…,x:C,…;wi)
Note:
Composite table T is the primary table ; table sequence/cursor A/cs is the subtable. They have a one-to-many relationship. The function matches T’s key (/dimension) field with the corresponding fields of A/cs (begin the correspondence from the first field) and returns a table sequence/cursor made up of x:C fields. A/cs is ordered by the first key field, which should have same order as T’s key (/dimension).
With a table sequence parameter, the function returns a table sequence, and with a cursor parameter, it returns a cursor or a multicursor. Align the returned result set to T and set key/dimension for it; support aggregations on fields of the subtable.
Parameter:
|
T |
A composite table |
|
A/cs |
A table sequence/cur sor |
|
K |
Name of the A/cs’s field that corresponds to T’s key (/dimension) Field of A/cs; when it is specified, use it to match with T’s key (/dimension); when it is absent, use the first field of A/cs to perform the matching; when there are multiple Ks, use colon (:) to separate them |
|
x |
Field expression or aggregate function count/sum/max/min/avg |
|
C |
Column alias; can be absent |
|
wi |
Filtering condition on T; retrieve the whole set when this parameter is absent; separate multiple conditions by comma(s) and their relationships are AND; besides regular filtering expressions, you can also use the following five types of syntax in a filtering condition, where K is a non-key field in entity table T: 1.K=w w usually uses expression Ti.find(K) or Ti.pfind(K), where Ti is a table sequence. When value of w is null or false, the corresponding record in the entity table will be filtered away; when w is expression Ti.find(K) and the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K; when w is expression Ti.pfind(K) and the to-be-selected fields C,... contain K, ordinal numbers of K values in Ti will be assigned to K. 2.(K1=w1,…Ki=wi,w) Ki=wi is an assignment expression. Generally, parameter wi can use expression Ti.find(Ki) or Ti.pfind(K), where Ti is a table sequence; when wi is expression Ti.find(Ki) and the to-be-selected fields C,... contain Ki, Ti’s referencing field will be assigned to Ki correspondingly; when wi is expression Ti.pfind(Ki) and the to-be-selected fields C,... contain Ki, ordinal numbers of Ki values in Ti will be assigned to Ki. w is a filter expression; you can reference Ki in w. 3.K:Ti Ti is a table sequence. Compare Ki value in the entity table with key values of Ti and discard records whose Ki value does not match; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K. 4.K:Ti:null Filter away all records that satisfy K:Ti |
Option:
|
@r |
Copy records of the primary table and return result set aligned by A/cs |
Return value:
Table sequence/Cursor
Example:
|
|
A |
|
|
1 |
=connect("demo").cursor("select STATEID,CAPITAL from STATECAPITAL") |
Return a cursor. |
|
2 |
=file("spec-new.ctx") |
|
|
3 |
=A2.create@y(#STATEID,CAPITAL) |
Create a composite table and set STATEID as the key. |
|
4 |
=A3.append@i(A1) |
Append data in cursor A1 to the composite table; below is content of the result table:
|
|
5 |
=demo.query("select STATEID,CID,NAME,POPULATION from CITIES").sort(STATEID) |
Return a table sequence:
|
|
6 |
=A4.new(A5:STATEID,CAPITAL,sum(POPULATION):STA_POP) |
A4 is the primary table and A5 is the subtable; perform the matching between the composite table’s key STATEID and the table sequence’s STATEID field and return a table sequence consisting of CAPITAL field and STA_POP field whose contents are results of performing an aggregate operation on the subtable’s POPULATION field:
|
|
7 |
=A4.new(A5,CAPITAL,sum(POPULATION):STA_POP) |
As parameter K is absent, perform matching between the composite table’s key and the table sequence’s first field – STATEID and return same result as A6. |
|
8 |
=A4.new@r(A5:STATEID,CAPITAL,NAME,POPULATION) |
Use @r option to copy the primary table records and return a result set aligned to the subtable:
|
|
9 |
=A4.new@r(A5:STATEID,STATEID,CAPITAL,NAME,POPULATION;STATEID<3,left(CAPITAL,1)=="M") |
Filter A4’s data according to filter condition – STATEID<3 and the first letter of CAPTIAL value is M – during the association:
|





When there are multiple K parameters:
|
|
A |
|
|
1 |
=file("stu.ctx").open() |
Open a composite table; its content is as follows:
|
|
2 |
=file("sco.txt").import@t() |
Return a table sequence as follows:
|
|
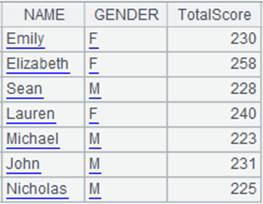
3 |
=A1.new(A2:Class:StudentID,NAME,sum(SCORE):TotalScore) |
A1 is the primary table and A2 is the subtable; perform the matching between the composite table’s key and the table sequence’s Class and StudentID and return a table sequence consisting of NAME field and TotalScore field, whose contents are results of performing aggregation on subtable’s SCORE field:
|
|
4 |
=A1.new@r(A2:Class:StudentID,NAME,SUBJECT,SCORE) |
Use @r option to copy the primary table records and return a result set aligned to the subtable:
|




Use special types of filtering conditions:
|
|
A |
|
|
1 |
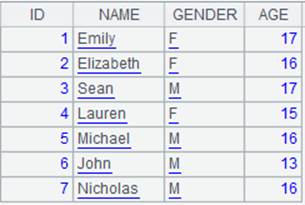
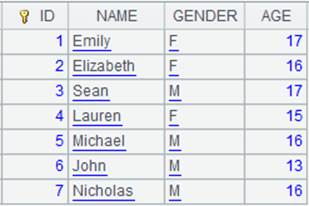
=demo.cursor("select * from STUDENTS") |
Below is content of the cursor:
|
|
2 |
=file("students.ctx") |
|
|
3 |
=A2.create@y(#ID,NAME,GENDER,AGE) |
Create a composite table. |
|
4 |
=A3.append@i(A1) |
Append cursor A1’s data to the composite table’s base table. |
|
5 |
=demo.query("select top 12 STUDENTID,SUBJECT,SCORE from SCORES") |
Return a table sequence:
|
|
6 |
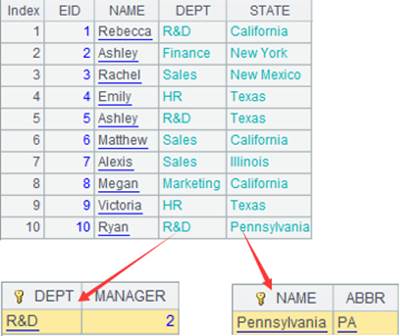
=A3.new(A5:STUDENTID,ID,NAME,AGE) |
Match the composite table’s key values to table sequence’s fields and retrieve corresponding composite table fields and return a table sequence:
|
|
7 |
=create(NAME,Num).record(["Emily",12,"Lauren",45]).keys(NAME) |
Generate a table sequence using NAME as the key:
|
|
8 |
=A3.new(A5:STUDENTID,ID,NAME,AGE;NAME=A7.find(NAME)) |
Use K=w filtering mode; in this case w is Ti.find(K) and entity table records making NAME=A7.find(NAME) get null or false are discarded; NAME is the selected field, to which table sequence A7’s referencing field is assigned.
|
|
9 |
=A3.new(A5:STUDENTID,ID,NAME;NAME=A7.pfind(NAME)) |
Use K=w filtering mode; in this case w is Ti.pfind(K) and entity table records making NAME=A7.find(NAME) get null or false are discarded; NAME is the selected field, to which its ordinal numbers in table sequence A7 are assigned.
|
|
10 |
=A3.new(A5:STUDENTID,ID,NAME;NAME:A7) |
Use K:Ti filtering mode; compare the entity table’s NAME values with the table sequence’s key values and discard entity table records that cannot match.
|
|
11 |
=A3.new(A5:STUDENTID,ID,GENDER;NAME:A7) |
This is a case where K isn’t selected; NAME isn’t the selected field, so only filtering is performed.
|
|
12 |
=A3.new(A5:STUDENTID,ID,NAME;NAME:A7:null) |
Use K:Ti:null filtering mode; compare the entity table’s NAME values with the table sequence’s key values and discard entity table records that can match.
|
|
13 |
=create(Age,Chinese_zodiac_sign).record([14,"tiger",15,"ox",16,"rat"]).keys(Age) |
Return a table sequence using AGE as the key.
|
|
14 |
=A3.new(A5:STUDENTID,ID,NAME,AGE;(AGE=A13.find(AGE),NAME=A7.find(NAME),AGE!=null&&NAME!=null)) |
Use (K1=w1,…Ki=wi,w) filtering mode; return records that meet all conditions.
|