Subroutines
Code reuse makes coding simpler and more efficient in program development. esProc supports basic code reuse by loop, as well as the modular programming through subroutine call or cross-cellset call. Here we discuss how to implement the two types of calls.
5.5.1 Subroutine call
A subroutine is a code block in which the master cell holds the func statement, and returns result with the return statement. Call the subroutine at the code block of C by using func(C, xi,…) function in the expression, in which xi,…. is the parameter. For example:
|
|
A |
B |
|
1 |
func |
/create an ID |
|
2 |
|
>id="" |
|
3 |
|
>A1.run(id=id+char(65+rand(26))) |
|
4 |
|
return id |
|
5 |
=func(A1,rand(3)+3) |
|
Create a random ID of capital letters according to the length of the given characters in the code block which covers the first line to the fourth line and takes A1 as the master cell. B2 sets id, the cellset variable, as an empty string. According to the length of characters obtained by the subroutine’s master cell, B3 runs a loop, adding a random capital letter to id each time while initializing id, the cellset variable, before each addition. B4 returns the value of the cellset variable id using the return statement. A5 calls the subroutine using the func function. In the expression =func(A1,rand(3)+3), A1 is the master cell of the invoked subroutine; rand(3)+3 computes the parameter value, a random integer of 3~5 characters, and passes it to the subroutine for computation. The result of A5 is a string consisting of 3~5 random characters, as shown below:
![]()
The parameter of func command will be copied to the subroutine’s master cell at the call of the subroutine. As the other applications, esProc uses a subroutine repeatedly. For example:
|
|
A |
B |
|
1 |
=5.(func(A2,2)) |
=10.(func(A2,rand(3)+3)) |
|
2 |
func |
/create an ID |
|
3 |
|
>id="" |
|
4 |
|
>A2.run(id=id+char(65+rand(26))) |
|
5 |
|
return id |
A1 creates five two-letter strings randomly as the abbreviations of product names. B1 creates ten strings consisting of 3~5 characters randomly as the client names. Here’re results of A1 and B1:
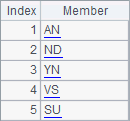
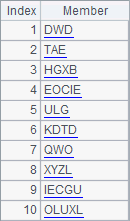
According to the two blocks of code, a subroutine can be called from any cell of the cellset. Actually during the running of a cellset program, the code block of the subroutine won’t be executed until the subroutine is called.
Both a subroutine and a loop statement are presented by a code block. The latter will be executed only when the loop in the master cell runs, whereas a subroutine can be called by the func function from any cell. The code block of a subroutine will remain unexecuted until the subroutine is called. Once a subroutine call begins, it continues until the end of the block, or until the first return command appears and returns the result. But what if there are multiple results to be returned? Look at the following example:
|
|
A |
B |
C |
|
1 |
=create(Product,Customer) |
0 |
|
|
2 |
func |
/create an ID |
|
|
3 |
|
>id="" |
>A2.run(id=id+char(65+rand(26))) |
|
4 |
|
return id |
|
|
5 |
func |
|
|
|
6 |
|
return [A7(A5),B7(B5)] |
|
|
7 |
=5.(func(A2,2)) |
=10.(func(A2,rand(3)+3)) |
|
|
8 |
for 100 |
=func(A5,rand(5)+1,rand(10)+) |
>A1.insert(0,B8(1),B8(2)) |
The subroutine which uses A5 as the master cell gets a product name and a client name according to the parameters. B6 returns them as a sequence. When it calls the subroutine, B8 creates randomly a product number and a client number and passes them as the parameters to the subroutine. If multiple parameters are used in calling a subroutine, they will be entered to cells from left to right starting from the master cell.
In B8, you can view the result returned by the execution of the last subroutine call:
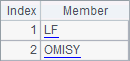
C8 fetches the needed data from the resulting sequence. The code in the 8th line generates 100 random records and inserts them into A1’s table sequence, in which each record has two parts: Product and Customer. After the program is run, A1’s table sequence is as follows:
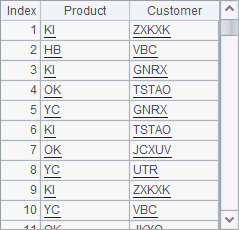
A subroutine does not necessarily return a value. When there is no return statement in the code block of a subroutine, the code will be sequentially executed until the end. For example:
|
|
A |
B |
C |
|
1 |
=create(OID,Product,Customer,Amount) |
0 |
|
|
2 |
func |
/create an ID |
|
|
3 |
|
>id="" |
>A2.run(id=id+char(65+rand(26))) |
|
4 |
|
return id |
|
|
5 |
func |
|
/add a record |
|
6 |
|
>B1=B1+1 |
=(rand(1000)+1)*100 |
|
7 |
|
>A1.insert(0,B1,A5,B5,C6) |
|
|
8 |
=5.(func(A2,2)) |
=10.(func(A2,rand(3)+3)) |
|
|
9 |
for 100 |
=A8(rand(5)+1) |
=B8(rand(10)+1) |
|
10 |
|
>func(A5,B9,C9) |
|
A2’s subroutine is the same as the one in the previous example. A5’s subroutine doesn’t have the return statement, so it will not return a value and will only add a record to A1’s table sequence with each execution. That’s why B10 can start with > when it calls A5’s subroutine. And the subroutine call will stop at the end of A5’s code block.
A9 generates 100 rows of test data by loop and adds them to A1’s table sequence:
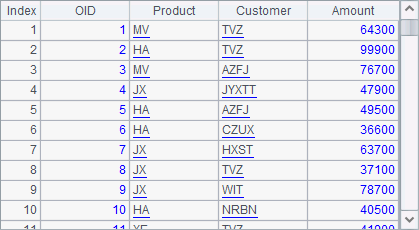
A subroutine can be recursive by allowing itself being called. As the example shows:
|
|
A |
B |
C |
|
1 |
func |
|
|
|
2 |
|
if A1<=0 |
return 1 |
|
3 |
|
else |
>A5=A5+string(A1)+";" |
|
4 |
|
|
return A1*func(A1,A1-1) |
|
5 |
="" |
|
|
|
6 |
=func(A1,12) |
|
|
A1’s subroutine makes judgment according to the input data. When A1is greater than 0, call itself recursively in C4 to compute factorial. A6 computes the factorial value of 12:
![]()
A5’s string stores the parameter used for each subroutine call, which shows the recursive process:
![]()
You can solve some complex problems using recursion. For example:
|
|
A |
B |
C |
|
1 |
func |
|
|
|
2 |
|
=A1\B1 |
=A1%B1 |
|
3 |
|
if C2==0 |
return B1 |
|
4 |
|
else |
return func(A1,B1,C2) |
|
5 |
=func(A1,4557,5115) |
|
|
It uses Euclidean algorithm to compute the greatest common divisor (GCD) of two numbers. The GCD of 4557 and 5115 that A5 gets is:
![]()
It is not necessary to use return statement to return a result set in a subroutine. Without return statement, the subroutine will return value of the last calculation cell starting with = within its sphere. For example:
|
|
A |
B |
C |
|
1 |
func |
/create an ID |
|
|
2 |
|
>id="" |
>A1.run(id=id+char(65+rand(26))) |
|
3 |
|
=id |
Test |
|
4 |
=5.(func(A1,2)) |
=10.(func(A1,rand(3)+3)) |
|
Here A1’s subroutine doesn’t have a return statement, so it returns the value of the last calculation cell beginning with = in its sphere, i.e. B3’s cell value, instead of the value of constant cell C3. This is equivalent to using return id in B3. In this case A4’s result is still the 5 random strings each composed of 2 letters, and B4 still gets 10 random strings composed of 3~5 characters each.
5.5.2 Cross-cellset call
Besides the subroutine call, esProc also supports the cross-cellset call, which uses call function to run a program from another cellset or to make use of the result of another cellset. This means a whole cellset will be treated as a subroutine to be executed. The return statement is used to return the result. End the cross-cellset call to release the memory after the result is returned. D:\files\createID.splx is a cellset:
|
|
A |
B |
|
1 |
/create an ID |
|
|
2 |
|
>size.run(A2=A2+char(65+rand(26))) |
|
3 |
return A2 |
|
In the cellset, B2 adds characters to A2 circularly to create random IDs and returns them using return statement. Similar to a subroutine call, it is also not necessary to use the return statement for a cross-cellset call. The returned result will be the value of the last calculation cell starting with =. You can change A3’s code to =A2, for example, and still get the same result. Notice that B2 uses a cellset parameter, size, which needs to be set in Program parameter dialog on the menu bar.
If a parameter is needed during the cross-cellset call, it should be transferred through the cellset parameter used in the dfx file being called. The way of using call function to call a program in another cellset is similar to that of calling a subroutine:
|
|
A |
|
1 |
=call("D:\\files\\createID.splx",rand(3)+3) |
|
2 |
=call("createID.splx",rand(3)+3) |
Likewise, the parameter is put after the program being called. Difference is that the script file being called is specified directly through its name during the cross-cellset call in A2. Note that \ is an escape character when used in a string expression; so, in A1’s code another \ is put before it to represent the character literally. A1 and A2 respectively call the script file and create an ID with 3~5 characters, as shown below:
![]()
![]()
To phrase a statement as A2’s, make sure that the script file is in esProc’s main path or search path. Click Tool>Options on the menu bar to set the main path and search path on the Environment page, as shown in the figure below:
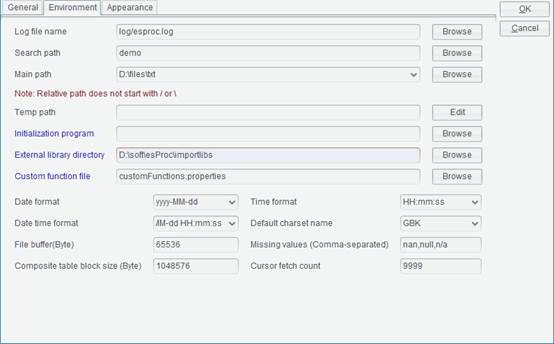
In the above configuration, whichever directory in the main path or search path the script file is placed, it can be called by the call function by name, without the necessity of writing the whole path.
If the dfx file is to be integrated, the main path and search path need to be configured in the configuration file raqsoftConfig.xml:
<Esproc>
<splPathList>
<splPath>E:\tools\raqsoft\esProc\demo\Case\Structural</splPath>
<splPath>D:\files\txt;</splPath>
</splPathList>
<mainPath>D:\files\demo</mainPath>
</Esproc>
A cross-cellset call could use multiple parameters or return multiple results. Like the following D:\files\findNames.splx shows:
|
|
A |
B |
|
1 |
/find a PNAME and a CNAME |
|
|
2 |
=rand(PNames.len())+1 |
=rand(CNames.len())+1 |
|
3 |
return PNames(A2),CNames(B2) |
|
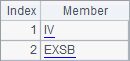
This subroutine fetches a random member from PNames and CNames respectively and returns them. PNames and CNames are input cellset parameters:

The main program calls a cellset program as follows:
|
|
A |
B |
|
1 |
=create(Product,Customer) |
|
|
2 |
=5.(call("createID.splx ",2)) |
=10.(call("createID.splx ",rand(3)+3)) |
|
3 |
for 100 |
=call("findNames.splx",A2,B2) |
|
4 |
|
>A1.insert(0,B3(1),B3(2)) |
A2 and B2 call the above-mentioned cellset createID.splx to create a sequence of product names and a sequence of client names. A3 runs a loop to call the cellset findNames.splx in B3 which inputs A2 and B2 as the parameters. Note: For the parameters used in call function, their values will be given to the script file’s parameters respectively; this is irrelevant to the parameter names in script file parameter list. That is to say, values are assigned to dfx’s parameters in order: A2’s value is assigned to PNames, and B2’s value is assigned to CNames. Unlike a subroutine’s return statement that returns a sequence of results, the return statement of the cellset being called separates the multiple results with commas and they will be returned automatically as a sequence. The returned result of the last cross-cellset call can be viewed in B3:
The aim of the above main cellset is to generate 100 random rows of test data and insert them into A1’s table sequence, where each record consists of two parts: Product and Customer. When the program is executed, the result of A1 is as follows:
As with the subroutine call, it is not necessary for a cros-cellset call to return a result. As the following file, D:\files\addRecord.splx, shows:
|
|
A |
B |
|
1 |
/add a record |
|
|
2 |
=Table.len()+1 |
=(rand(1000)+1)*100 |
|
3 |
>Table.insert(0,A2,PNAME,CNAME,B2) |
|
The cellset program uses three parameters to input product names (PNAME), client names (CNAME) and the table sequence (Table):
The cellset program is called by the following main cellset:
|
|
A |
B |
|
1 |
=create(OID,Product,Customer,Amount) |
|
|
2 |
=5.(call("createID.splx ",2)) |
=10.(call("createID.splx ",rand(3)+3)) |
|
3 |
for 100 |
=call("findNames.splx",A2,B2) |
|
4 |
|
>call("addRecord.splx",B3(1),B3(2),A1) |
B4 calls addRecord.splx to insert the randomly generated records to A1’s table sequence. When the program is executed, A1’s table sequence gets random test data as follows:
By reusing the existing cellset program, the cross-cellset call makes the code in the main cellset more concise. In addition, an algorithm which needs to be encrypted can be put into a separate cellset for being called by another program.