Methods of External Memory Grouping for Large Result Sets
After data is imported from a data table, often it may need to be grouped as required, or an aggregate operation is needed. In esProc, groups function can compute the aggregate result directly; group function is used to group data first, and then perform further analysis and computation.
For big data processing, however, records can’t be loaded into the memory all togerther for grouping; sometimes the groups are big and the grouping and aggregation result can’t be returned all at once. Both occasions require the use of external memory grouping.
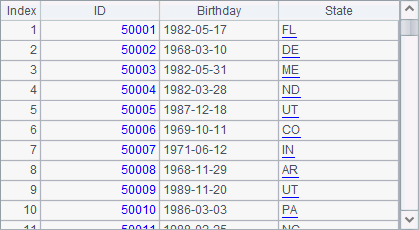
Let’s create a big, simple data table for containing employee information, which includes three fields: employee ID, state and birthday. The employee IDs will be generated sequentially; the states are entered in abbreviations obtained arbitrarily from the STATES table of demo database; birthdays are the dates selected arbitrarily within 10,000 days before 1994-1-1.The data table will be stored as a bin file for convenience.
|
|
A |
B |
C |
|
1 |
1000000 |
1000 |
=A1/B1 |
|
2 |
=file("BirthStateRecord.btx") |
=create(ID,Birthday,State) |
=demo.query("select ABBR from STATES") |
|
3 |
1994-1-1 |
0 |
=C2.(ABBR) |
|
4 |
for C1 |
for B1 |
>B3=B3+1 |
|
5 |
|
|
=elapse(A3,-rand(10000)) |
|
6 |
|
|
=C3(rand(C3.len())+1) |
|
7 |
|
|
>B2.insert(0,B3,C5,C6) |
|
8 |
|
>A2.export@ab(B2) |
|
|
9 |
|
>B2.reset() |
|
|
10 |
=A2.cursor@b() |
>A10.skip(50000) |
=A10.fetch(1000) |
|
11 |
>A10.close() |
|
|
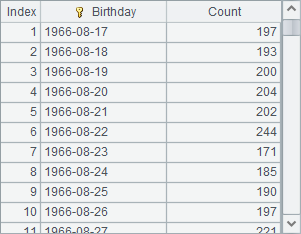
Altogether 1,000,000 rows of data are generated. C10 fetches rows from the 50,001th to the 51,000th with cursor:
Most of the time, when grouping data of cursors, it is the aggregate result, instead of the detailed data in each group, that is desired. To get the number of employees of each state from BirthStateRecord, for example, you can use the groups function to accomplish it:
|
|
A |
|
1 |
=file("BirthStateRecord.btx") |
|
2 |
=A1.cursor@b() |
|
3 |
=A2.groups(State;count(~):Count) |
|
4 |
>A2.close() |
A3 gets the grouping and aggregation results:
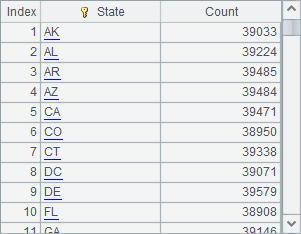
Notice that the groups function for grouping and aggregation returns a table sequence as the result after the computation is completed. During big data processing, sometimes there are a lot of groups and the result sets are too big to be returned all at once. The real-world cases include the customers’ bills calculated according to certain grouping condition by the telecom company and sales information grouped by certain condition for various kinds of products in the online shopping malls, and the like. In those cases, the use of groups function may result in a memory overflow. Alternatively, the groupx(x:F,…;y:F,…) function can be used to perform the grouping and aggregation by temporarily storing the result sets in external memory. For example:
|
|
A |
|
1 |
=file("BirthStateRecord") |
|
2 |
=A1.cursor@b() |
|
3 |
=A2.groupx(Birthday;count(~):Count;1000) |
|
4 |
=A3.fetch(1000) |
|
5 |
>A2.close() |
A3’s groupx function uses a row buffering parameter, whose value is set as 1000. We use this parameter only for testing and to illustrate the external memory grouping method. It isn’ needed in actual coding because esProc will automatically create a buffer file when the memory reaches its maximum capability. The code is executed step by step until A4. A3 performs grouping and aggregation with groupx function by making use of external memory. Among cursor-based operations, groupx function is used for both grouping and aggregation with result sets stored in external memory and the grouping with group numbers directly specified. The difference of the two operations lies in the parameters. A3 groups records by Birthday to calculate the number of employees born on each of the dates. A3 returns a cursor as follows:
![]()
After A3 is executed, external files will be generated in the directory of temporary files:
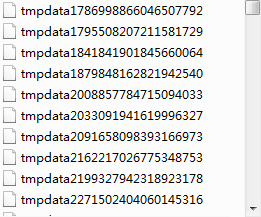
Import the data of one of the temporary files:
|
|
A |
|
1 |
=file("/temp/tmpdata1786998866046507792") |
|
2 |
=A1.import@b() |
|
3 |
=A2.count() |
Here’s the data that A2 imports:
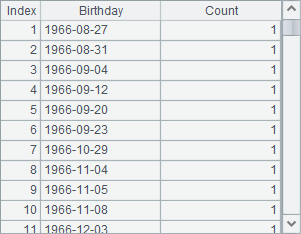
Below is A3’s result:
![]()
Here each temporary file is the result of grouping and aggregating a part of the whole data by Birthday. A grand cursor composed of all temporary file cursors will be merged and returned by the esProc program. When generating the temporary files, the program will set a suitable number of rows for each temporary file for the convenience of computation according to the available memory space.
Go on with the execution of the previous cellset file. When cursors close in A5, the temporary files will be automatically deleted. A4 fetches the first 1,000 birthdays from the cursor generated in A3 and counts the employees born on each birth date: