Cluster composite tables
The Server Cluster discussed cluster computing across a network of nodes. A composite table can be accessed through nodes and thus becomes a cluster composite table. To generate a cluster composite table, first we need to upload an existing composite table onto the main paths of all nodes. Now we can access nodes to read the composite table file:
|
|
A |
|
1 |
[192.168.1.112:8281] |
|
2 |
=file("employees.ctx",A1) |
|
3 |
=A2.open() |
|
4 |
=A3.cursor().fetch() |
|
5 |
=A3.cursor() |
|
6 |
=A5.groups(Dept;count(~):Count) |
In A2, file(fn,h) function reads the composite table file fn from the server list h to open a clustered file. Here only one node is involved. Here’s A3’s result:

In A3, T.open() function opens the composite table’s base table, which is a cluster composite table in this circumstance. An entity table of the cluster composite table is a cluster entity table. A4 retrieves attached table T' from the cluster composite table using T.attach(T') function. A cluster table is read-only but is computed in the same way as a local composite table is handled. In A4, T'.cursor() function generates a cursor from the cluster composite table’s base table T' and fetches data from the cursor:
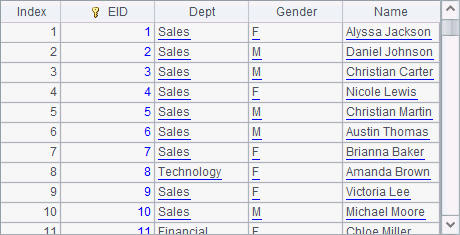
clustered file
Cursor-related function like cs.join(), cs.groupx() and cs.groups() apply to a cursor generated from a cluster composite table. A6 performs grouping and aggregation with cs.groups() function and gets the following result:
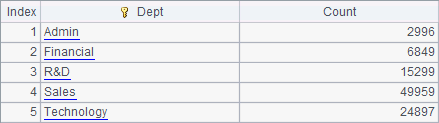
A cluster composite table can also be used to generate a cluster in-memory table, which utilizes the memory capacity:
|
|
A |
|
1 |
[192.168.1.112:8281] |
|
2 |
=file@n("D:/file/dw/employees.ctx",A1) |
|
3 |
=A2.open() |
|
4 |
=A3.memory(;right(Name,6)=="Garcia") |
|
5 |
=A4.dup() |
|
6 |
=A5(4) |
|
7 |
>A3.close() |
A2 opens a clustered file. Similar to generating an in-memory table from a local composite table, memory() function in A4 generates a cluster in-memory table. We can view the cluster in-memory table in A4:

We cannot handle a cluster in-memory table as we treat a table sequence. But the T.dup() function can convert the cluster in-memory table T into a local in-memory table, like what A5 gets:
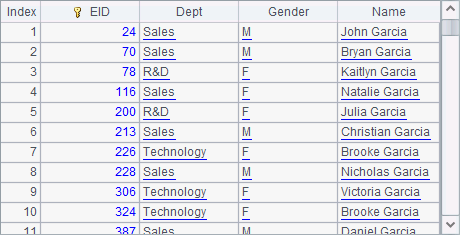
This is an ordianary in-memory table. T.dup(h) function can convert an ordinary in-memory table T into a cluster in-memory table. A cluster in-memory table should be closed to release memory resousrce using T.close() function after it finishes its job.
In fact, employees.ctx is also stored in the main path of another node 192.168.1.112:8282. We can perform query using the two nodes. For example:
|
|
A |
|
1 |
[192.168.1.112:8281, 192.168.1.112:8282] |
|
2 |
=file("employees.ctx", A1) |
|
3 |
=A2.open() |
|
4 |
=A3.cursor() |
|
5 |
=A4.fetch() |
Here A2 opens the clustered file through two nodes. A4 generates a cursor. The retrieval of the composite file will be split between the two nodes while the cursor remains its usual way of handling data with a single node. A5 fetches data from the cursor:
Take the above computation as an example, if a clustered file is stored redundantly in multiple nodes, it is called a duplicate file. A clustered file can also be made up of a homo-name files group. Such a clustered file is called a clustered homo-name files group. In this case, files stored on nodes come from a multi-zone composite table. Now let’s look at how to use a multi-zone composite table across a cluster using the students table in Acessing a (multi-zone) composite table. For example:
|
|
A |
B |
|
1 |
[192.168.1.112:8281, 192.168.1.112:8282] |
|
|
2 |
students.ctx |
D:/file/dw/students.ctx |
|
3 |
for [1,3,5] |
=file(B2:A3) |
|
4 |
|
=movefile@c(B3.name(); "/", A1(1)) |
|
5 |
for [2,4] |
=file(B2:A5) |
|
6 |
|
=movefile@c(B5.name(); "/", A1(2)) |
|
7 |
=file(A2:to(5),A1) |
=A7.open() |
|
8 |
=B7.cursor().fetch() |
>B7.close() |
Line 3 and line 4 copy file 1, file 3 and file 5 of B2’s multi-zone composite table onto node Ⅰ. Line 5 and line 6 copy file 2 and file 4 of the same table onto node Ⅱ. In A7, file(fn:zs:, hs) function accesses a cluster homo-name files group, without taking care of which node a zone file is stored. A8 retrieves specified data from the cluster homo-name files group, and gets a result table as follows:
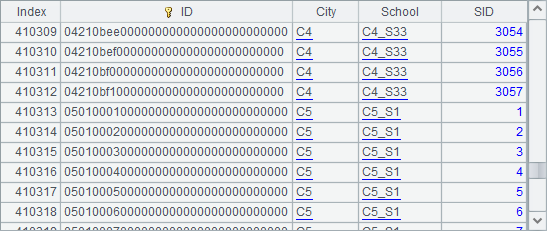
This shows that there is no need to get to know specifically the node where each zone table in a multi-zone composite table is stored. We just access the multi-zone composite table, and an automatic search of each zone table begins. Data will be read from zone tables, concatenated in turn, and returned. A cluster composite table demands high system stability because it is composed of a group of data tables stored in the memories of multiple nodes. In case that the malfunction of one or more nodes makes the table unavailable, we introduce memory fault tolerance strategy. The design stores each zone table of a multi-zone composite table redundantly in every node, enabling smooth computation when a certain node breaks down or is unavailable.