Updating Table Sequences
Adding, deleting and modifying records over a TSeq are common in data analysis and computing. This section discusses its update and maintenance by adding, deleting and modifying records and reseting it and adding fields to it; and explains differences between performing these operations on a TSeq and on an RSeq.
2.6.1 Adding records
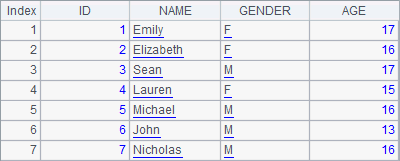
In the following cellset, a record r1 is appended to the table sequence in A1; and then a record r2 is inserted in the place of the second row. r1 is specified by listing field values in order and r2 is specified by giving field values followed by field names. Finally, three records r3, r4 and r5, which have values in ID and NAME fields specified but get nulls for other fields, are inserted consecutively before the second row.
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
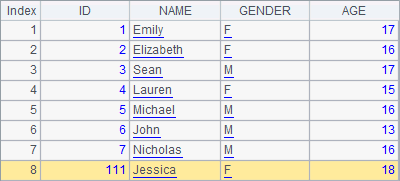
>A1.insert(0,111,"Jessica","F",18) |
|
3 |
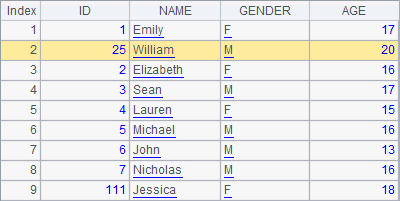
>A1.insert(2,25:ID,"William":NAME,20:AGE,"M":GENDER) |
|
4 |
>A1.insert(2:3,25+#:ID,"William"+string(#):NAME) |
A2, A3 and A4 successively add records to A1’s table sequence.
Click ![]() on the tool bar to
execute the code step by step to see the changes of the original table sequence
as follows:
on the tool bar to
execute the code step by step to see the changes of the original table sequence
as follows:
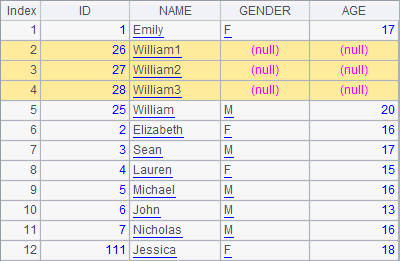
As can be seen from the above code, T.insert() function is used to add one or multiple records to a table sequence by specifying positions for the records to be inserted and fields for new values. Fields that aren’t assigned have null values.
Different from a table sequence, a record sequence is a sequence composed of references of the records. So only new references can be added to a record sequence:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=A1.to() |
|
3 |
>A1.insert(0,111,"Jessica","F",18) |
|
4 |
>A2.insert(2, A1(8)) |
A2 is a record sequence generated from the records of the table sequence in A1 through to function. To create another table sequence by duplicating the original table sequence, A.derive() function is needed. Both A1 and A2 here contain the same data as the table sequence in A1 in the previous example does. Then execute the cellset program step by step. With the code in A3 executed, the data in A1 and A2 are respectively as follows:
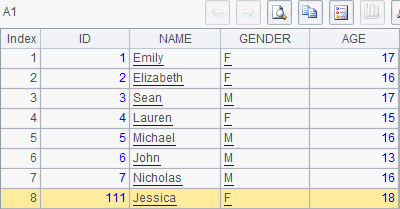
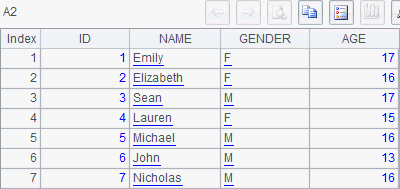
It can be seen that a new record has been appended to the table sequence, without affecting other records. So the record sequence in A2 remains unchanged. A4 inserts the new record into the record sequence, but at a different position. When A4 is executed, the record sequence in A2 becomes as follows:
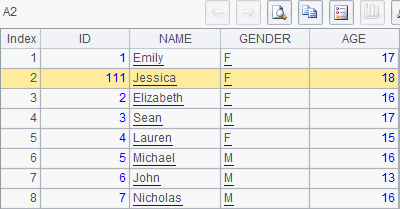
There is a big difference between the syntax of adding records to a table sequence and that of adding them to a record sequence. It is a physical record that a table sequence receives, so you can directly use insert function on table sequence A1. But a record sequence is only able to have the reference of a physical record that already exists. In the example, the newly added physical record is stored in A1 (It can also be a record of any other table sequence. Keep in mind that the records of a record sequence should be of the same structure; otherwise errors could arise).
That the first parameter of insert function is 0 means appending records at the end; if not, insert the records from the specified position. This applies to both table sequences and record sequences.
The one or more records inserted to a table sequence can come from a record sequence or a table sequence. For example:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=create(ID, NAME, GENDER, AGE) |
|
3 |
>A2.insert(0:A1([1,2]), ID, NAME, GENDER, AGE) |
|
4 |
>A2.insert@r(1:A1) |
A2 creates a new table sequence. A3 appends records at the end of the table sequence. The records to be appended come from A1’s record sequence. If the record sequence has a same data structure, you can just use T.insert@r(k:P) without explicitly write the field names, as A4 does. It inserts all records of A1 before the second record of A2’s table sequence. After executed, A2’s data is as follows:
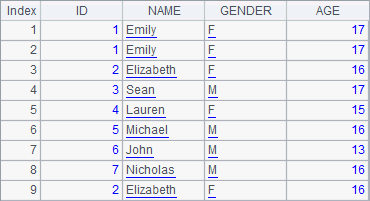
If the record sequence has a different structure, you can use T.insert@f(k:P) to add records according to shared fields. For example:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=create(ID, NAME, SEX, AGE) |
|
3 |
>A2.insert(0:A1([1,2]), ID, NAME, GENDER:SEX, AGE) |
|
4 |
>A2.insert@f(1:A1) |
A2 has different field names from A1. A3 specifies columns of A1’s record sequence corresponding to columns in the target table sequence when appending data at the end. A4, however, uses T.insert@f() to do the appending. After executed, A2 has the following data:
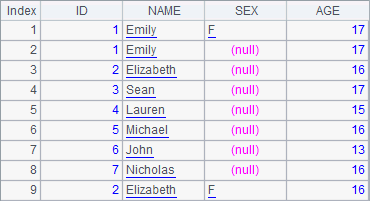
You can see that A4’s appending action only copies the fields of same names and enter nulls to the column of a different name.
2.6.2 Deleting records
In the following cellset, first the second record is deleted, then the first and second records, and finally the records of students who are older than 15 are deleted:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.delete(2) |
|
3 |
>A1.delete([1,2]) |
|
4 |
>A1.delete(A1.select(AGE>15)) |
A2, A3 and A4 successively delete records from A1’s table sequence. With the step-by-step execution of the code, you can see its changes as follows:
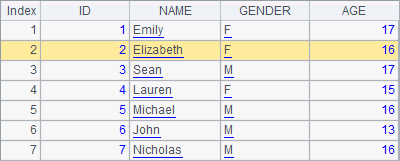
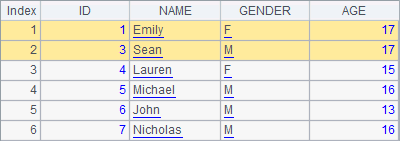
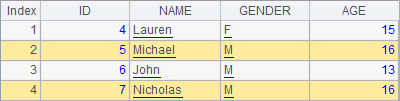

The delete function is used to delete records from a table sequence. The records are specified by ordinal numbers, or a sequence consisting of the ordinal numbers; or through a query of generating a record sequence. The code in A4 is equal to >A1.delete(A1.pselect@a(AGE>15)).
Let’s look at an example with a record sequence:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
=A1.to() |
|
3 |
>A2.delete(2) |
|
4 |
>A2.delete([1,2]) |
The record sequence in A2 and the original table sequence in the previous example have the same data. First A3 deletes a record, and then A4 deletes two records. Execute the code step by step and you can see the changes of the record sequence in A2:
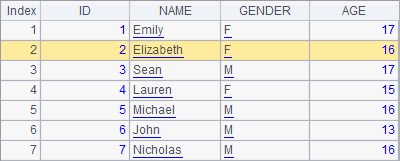
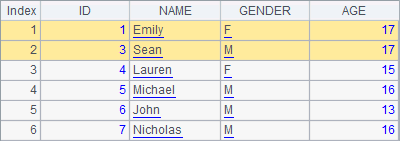
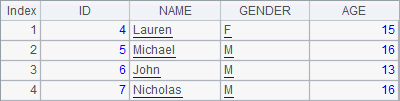
But a check of the data in A1shows that the original data in the table sequence remains unchanged:
It is the physical records that have been deleted from the table sequence, while it is the references of the records that have been deleted from the record sequence, which won’t affect the physical table sequence.
2.6.3 Modifying records
In the following cellset, first A2 modifies the GENDER field into Female and the NAME field into Violet for the second record; and then A3 adds 10 to each ID of the three consecutive records starting from the second:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.modify(2, "Female":GENDER, "Violet":NAME) |
|
3 |
>A1. modify (2:3,ID+10:ID) |
The table sequence in A1 contains the same original data as the table sequence in the above example. A2 and A3 respectively modify the table sequence. Through step-by-step execution, you can see the changes of A1:
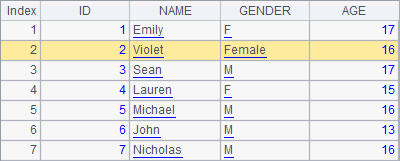
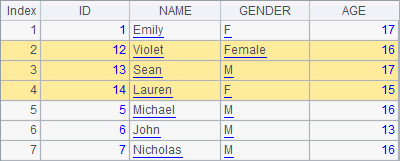
The modify function is used to modify records in a table sequence. It is also used to modify values of a single record.
It is forbidden to modify records in a record sequence. The modification must be performed on the refrerenced table sequence.
The field values of a record can be changed into those of another record in alignment:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1(5).modify@r(A1(1)) |
Using modify@r function to modify a record is also called record pasting. Through A2’s record pasting operation, the fifth record in the table sequenc has been changed:
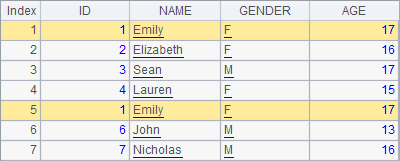
The record being pasted can be from the same table sequence, or another table sequence. The subject of record pasting function is records, instead of table sequences, so it applies in both table sequence and record sequences. The operation will update the original table sequence when executed. esProc also provides T.modify@r(k:P) function to paste multiple records of a record sequence simultaneously beginning from the kth record; append the records at the end when k is 0. If the to be appended records come from another table sequence of different structure, you can use T. modify@f(k:P) function to paste only the shared fields.
The field function can get field values as well as modifying them for a sequence or a record. For example:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
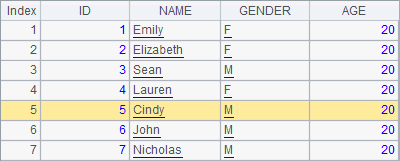
>A1.field("AGE",20) |
|
3 |
>A1(5).field(2, "Cindy") |
Modifying records with field function is similar to the use of modify function, except that the former can specify both a field number and a string type field name. When the above code is executed, the AGE field and the NAME of the 5th record are modified, as the following shows:
2.6.4 Reseting table sequences
Using reset function, you can empty a table sequence while retaining its data structure:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
>A1.reset() |
Resetting a table sequence can remove useless records and release the memory:

2.6.5 Adding fields
It is not allowed to add fields to a table sequence or to delete them from it. To add new fields to a table sequence, such as computed columns, create a new table sequence using derive function:
|
|
A |
|
1 |
=demo.query("select * from STUDENTS") |
|
2 |
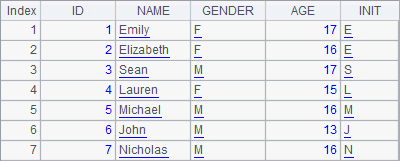
=A1.derive(left(NAME,1):INIT) |
The new table sequence is as follows after A2 adds new fields to the old one:
The derive function also applies to record sequences. No matter the subject of data manipulaiton is a table sequence or a sequence, the function will always create a new table sequence. If all the original fields are not needed, new function can be used to create a table sequence anew. For this example, if the data in the original table sequence A1 becomes useless, it would be better to clear the table sequence of all its field values, or to reset it using the reset function.