8.2 Multithreading
This section explains how to perform a multithreaded computation using the fork statement. You can choose to skip this section if you are not a professional programmer. It won’t affect your learning about the other contents of this Tutorial.
Sequential computation is the simplest and most intuitive processing method in handling computational tasks. Contemporary servers and PCs, however, have gained the multi-tasking ability with multi-core CPUs. Under the circumstances, sequential computation cannot make the most use of the computational power the CPU offers. Parallel computation is thus a better choice for implementing complex computational tasks and processing big data using multiple threads, or even multicomputers.
We’ll discuss multithreading – the most basic form of parallel computing – in this chapter.
8.2.1 Multithreaded execution with fork statement
Multithreading allows subtasks to have their respectively independent threads to compute concurrently during the implementation of a computational task. esProc uses fork statement to execute multiple threads. Its uses will be illustrated through the following example:
|
|
A |
B |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
|
2 |
fork B1 |
=A1.select(DEPT==A2) |
|
3 |
|
=B2.minp(BIRTHDAY) |
|
4 |
|
return B3 |
A1 retrieves data from the database table EMPLOYEE:
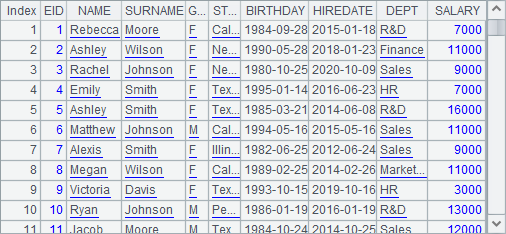
A2 performs the multithreaded operation using fork statement to select from each department the eldest employee. When executed, A2 gets result as follows:
During the code execution with multiple threads, fork statement loops through the sequence parameter, and according to the length of the parameter sequence, it uses multiple threads running in parallel to execute the code block where fork statement resides. The results returned through the return statement from the code block will be concatenated into a sequence in the main thread. You can also use a result statement to return the result.
Though looking like a loop computation, the fork statement is different from the for statement. The code block of a for statement is executed sequentially by a single thread, while a fork statement handles subtasks whose number is determined by the sequence parameter simultaneously. In order to further understand the execution of each thread, in A2’s code block output function is used to output the execution information to the console:
|
|
A |
B |
C |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
|
|
2 |
fork B1 |
>output(A2+"-begin") |
=A1.select(DEPT==A2) |
|
3 |
|
=B2.minp(BIRTHDAY) |
>output(A2+"-end") |
|
4 |
|
return B3 |
|
During the execution of A2’s code block, information is output from B2 and C3, respectively as a computation starts and ends. The output result after execution is as follows:
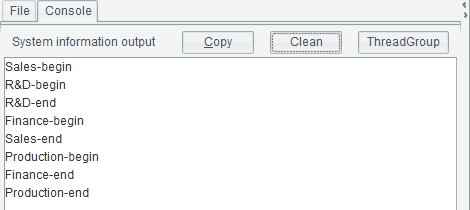
According to the output result, some subtasks can be implemented concurrently while others are waiting until resources are available. The system distributes subtasks to multiple threads and controls their execution according to the CPU capacity. The computing time of each subtask is affected by its computation volume and the status of the thread by which it is being performed. The implementation of subtasks with multiple threads differs according to different environments.
Multiple threads of execution can use multiple parameters. For example:
|
|
A |
B |
C |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
[Texas,Illinois,Ohio,Florida] |
|
2 |
fork B1,["F","F","F","F"],C1 |
=A1.select(DEPT==A2(1) && GENDER==A2(2) && STATE==A2(3)) |
|
|
3 |
|
=B2.minp(BIRTHDAY) |
|
|
4 |
|
return B3 |
|
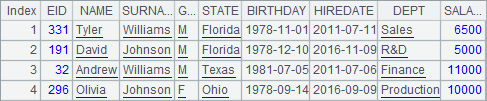
A2 uses three parameters in executing multiple threads. Members of the parameters will be sequentially matched for computation, i.e. [Sales,F,Texas], [R&D,F,Illinois], [Finance,F,Ohio] and [Production,F,Florida]. By doing so, department, gender and state are specified for selecting the eldest employees. Here’s A2’s result:
The sequence parameters used in the multiple threads of execution must have the same lengths.
In the above code, the genders specified for selecting employees from every department are same. So the corresponding parameter can be written as a single value, as shown in the following cellset:
|
|
A |
B |
C |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
[Texas,Illinois,Ohio,Florida] |
|
2 |
fork B1,"F",C1 |
=A1.select(DEPT==A2(1) && GENDER==A2(2) && STATE==A2(3)) |
>A1=B2 |
|
3 |
|
return B2 |
|
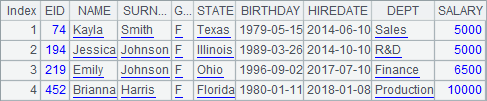
While a multithreaded operation is invoked, the single-value parameter will be copied to every thread where the same parameter value will be used. By the way, the return statement at the code block returns a record sequence instead of a single record each time, so the result of A2 is a sequence composed of record sequences:
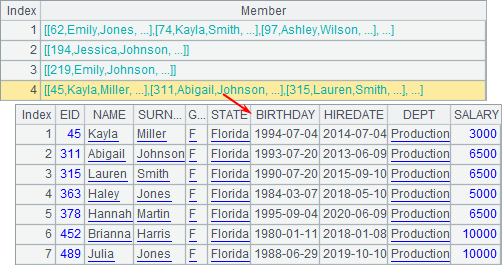
C2 at the code block updates A1 by modifying it into the record sequence derived from it through the query subroutine. Check A1’s data after the code block is executed and you can find that it hasn’t been modified by the code block of the multithreaded operation. Actually the multiple threads executing the subroutine will respectively duplicate the current cellset, thus they are mutually independent, having no influence on each other as well as on the data in the main routine.
The fork statement can be used in cluster computing, too. Details will be covered in Cluster Computing.
8.2.2 Performance advantage of multithreading
It appears that the execution of multithreaded code is similar to that of the loop code. But why multithreading is better? The following comparison between them gives the answer:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
|
|
2 |
=now() |
|
|
3 |
fork to(4) |
=A1.import@t(;A3:4) |
|
4 |
|
return B3.select(City=="San Diego") |
|
5 |
=A3.conj() |
=interval@ms(A2,now()) |
|
6 |
|
|
|
7 |
=now() |
|
|
8 |
for 4 |
=A1.import@t(;A8:4) |
|
9 |
|
>A10=A10|B8.select(City=="San Diego") |
|
10 |
[] |
=interval@ms(A7,now()) |
This example finds employees coming from San Diego from the text file PersonnelInfo.txt. The 2nd to the 5th lines use multithreading and from the 7th to the 10th lines run a loop. Both B3 and B8 import data by segment. Note that fork to(4) cannot be simplified for multithreaded execution. We get the same results in A5 and A10:
B5 and B10 time the two methods as they complete their computations
![]()
![]()
The multithreading takes less time than the loop takes thanks to a better utilization of CPU.
8.2.3 Setting the reasonable number of threads
Since multiple threads of execution can increase efficiency, then will it be improved more significantly with more threads? Let’s run a test and see.
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
|
|
2 |
=now() |
|
|
3 |
fork to(4) |
=A1.import@t(;A3:4) |
|
4 |
|
return B3.select(City=="San Diego") |
|
5 |
=A3.conj() |
=interval@ms(A2,now()) |
|
6 |
|
|
|
7 |
=now() |
|
|
8 |
fork to(400) |
=A1.import@t(;A8:400) |
|
9 |
|
return B8.select(City=="San Diego") |
|
10 |
=A8.conj() |
=interval@ms(A7,now()) |
The 2nd to 5th lines perform multithreaded execution with 4 threads while the 7th to the 10th lines perform one with 400 threads. Both A5 and A10 get the same result as that in the previous section. Now let’s check the computing time estimated in B5 and B10:
![]()
![]()
A8’s doesn’t increase efficiency in spite of using so many threads for a multithreaded opeation; on the contrary, the efficiency decreases. The computer has limited CPU capacity, but too many threads have to wait in queue for being executed and they also use the CPU resources. That’s why the efficiency lags rather than increases. In actual use, good performance can be achieved with the number of threads being a little fewer than that of CPU cores.