Sorting and Ranking Data
It is a frequent need in data summarizing and analysis to sort data or get the member rankings, like sorting sales records by date, getting the salespersons’ achievement rankings for performance assessment, and so on.
3.3.1 Sorting and ranking members in a sequence
esProc uses functions inlcuding psort, sort, rank, ranks, and etc. to sort or rank data. Now let’s look at how to perform the operations on sequences.
|
|
A |
|
1 |
[8,1,2,7,0,5,3] |
|
2 |
=A1.sort() |
|
3 |
=A1.psort() |
|
4 |
=A1.ranks() |
|
5 |
=A1.rank(5.5) |
A2~A5 sort and rank members of A1’s sequence. Results of A2 and A3 are respectively as follows:
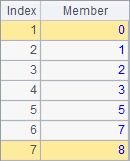
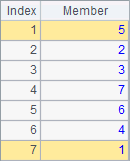
A2 sorts members of the sequence in ascending order, and A3 finds ordinal numbers of the sorted members in the original sequence. For instance, the ordinal number of 0, the smallest value, in the original sequence is 5; the ordinal number of 8, the biggest value, in the original sequence is 1. Actually the result of the expression in A2 is the same as that of =A1(A1.psort()). So psort function can be used to generate an index integer sequence during data computing. Results of A4 and A5 are respectively as follows:
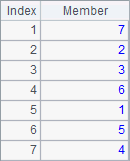
![]()
The result of A4 is the rankings of members of the original sequence in ascending order. A5 finds the ranking of 5.5 in the same order by comparing it with each member of the original sequence.
When it is expected to have same rankings in the result, you can use @i option and @s option to adjust the sorting result. For example:
|
|
A |
B |
|
1 |
[2,1,2,3,4,4,5] |
|
|
2 |
=A1.ranks() |
|
|
3 |
=A1.ranks@i() |
=A1.rank@i(3.8) |
|
4 |
=A1.ranks@s() |
=A1.rank@s(2) |
A2 gets the default rankings. A3 uses @i option, and A4 works with @s option. Results of A2, A3 and A4 are as follows:
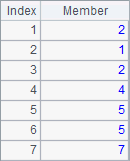
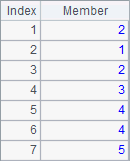
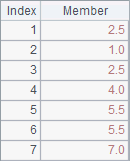
By default, same rankings take up the positions, making the rankings of later members postponed. For instance, with two second rankings, the next member will be recorded as the 4th. But the use of @i option can eliminate this effect, which means no matter how many same second rankings, the next member will always be recorded as the 3rd. With @s option added, the function will calculate the average of the same rankings, if any, to make it their recorded ranking, which reflects the reality better. For instance, the two second rankings actually take up the second and third positions, so it’s reasonable to consider that their real rankings are the average 2.5.
Similar to ranks function, rank function changes its normal computational style after working with @i option or @s option. Here are results of B3 and B4:
![]()
![]()
Note: When executing A.rank@s(y) function, if y is already included in A, the funciton will return the ranking of y’s corresponding value in A, instead of projecting y in A to calculate the average of same rankings.
When there are empty values in a sequence, the empty values will be considered the smallest in sorting. In certain cases, @o option can be used to make the empty value the biggest. For example:
|
|
A |
|
1 |
[1,2,,,4,3,2,1] |
|
2 |
=A1.sort() |
|
3 |
=A1.sort@0() |
Sorting results of A2 and A3:
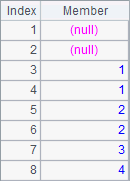
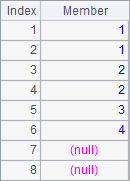
All sorting-related functions, like psort and sort, can work with the @o option.
In real-world situations, it is seldom to sort a constant sequence. Usually, the sequence to be sorted comes from computation. For example:
|
|
A |
B |
C |
|
1 |
=demo.query("select * from EMPLOYEE where EID<6") |
|
|
|
2 |
=A1.(NAME+" "+SURNAME) |
=A2.sort() |
=A2.ranks() |
|
3 |
=A1.(BIRTHDAY) |
=A3.sort() |
=A3.ranks() |
|
4 |
=A1.(age(BIRTHDAY)) |
=A4.sort@z() |
=A4.ranks@z() |
For the convenience of comparison, A1 selects only the first five records of employees to calculate. A2 computes their full names. B2 sorts these names, and C2 computes the rankings of them. Results of A2, B2 and C2 are as follows:
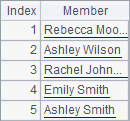
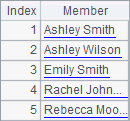
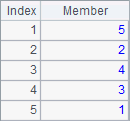
Notice that these strings are sorted alphabetically. In practice, strings are sorted and ranked according to each character’s ASCII code.
A3 computes employees’ birthdays, B3 sorts them and C3 computes the their rankings. Results A3, B3 and C3 are as follows:
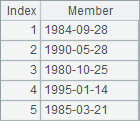
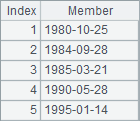
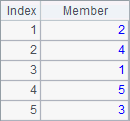
The date type data is sorted in ascending time order. In esProc, you can click Tool>Option to set the date format on the Environment page. But the result of sorting or ranking data of date type or datetime type is irrelevant to the format.
A4 computes the ages of employees. B4 adds @z option to the function to sort the ages in descending order. C4 also uses this option to compute rankings in descending order. Similarly, psort function and rank function can also use the @z option. Results of A4, B4 and C4 are as follows:
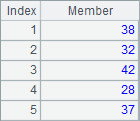
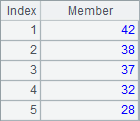
By adding @z option, the orders in which sort function and rank function get their results are still in opposite directions. You can notice that there are duplicate values among the ages. As shown in the result, the rankings of both 42s are 2 while the ranking of next 37 becomes 4. This means a same ranking will occupy a position by default. The rank operation will be covered in detail in the third section.
The way that strings are sorted according to each character’s ASCII code may cause an error if the target strings are not in English language. In that case, you need to specify the language in A.sort(…;loc) through the parameter loc. For example:
|
|
A |
|
1 |
[Íker,Álvaro,Estela,Alba,César,Sancho] |
|
2 |
=A1.sort() |
|
3 |
=A1.sort(;"esp") |
The sequence in A1 contains Spanish names. A2 and A3 sort them in different ways. A3 specifies a language parameter "esp" to sort the string members in Spanish alphabetical order. Values of A1, A2 and A3 are as follows:
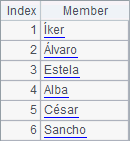
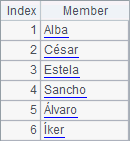
As can be seen, a correct sorting result can be got by specifying a language parameter.
For the languages and charsets esProc supports, please refer to the Function Reference.
3.3.2 Record sorting
Sorting records in a data table as required is another common need during data computing. For example:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY from EMPLOYEE where EID<6") |
|
2 |
=A1.sort(NAME+" "+SURNAME) |
|
3 |
=A1.sort(BIRTHDAY) |
|
4 |
=A1.sort@z(age(BIRTHDAY)) |
A1 is a selection of the table of employee information:
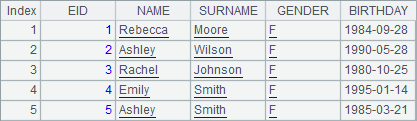
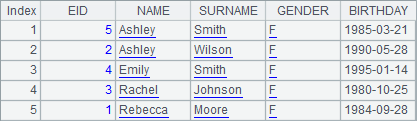
A2 sorts the records according to the employees’ full names:
A3 sorts the records by birthday:
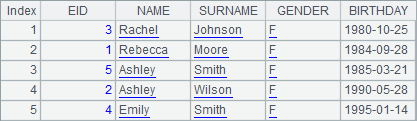
A4 sorts the records by age in descending order:
So you see that the sort function can be used conveniently to sort the records in a table sequence or a record sequence and generate and return a new record sequence.
Let’s look at the result of A2, which has been sorted by full names. But most of the time the records of employees are sorted first by surnames and those of employees who have the same surnames are sorted again by names. Multiple fields are thus involved.
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY from EMPLOYEE") |
|
2 |
=A1.sort(SURNAME,NAME) |
|
3 |
=A1.sort(GENDER,-SURNAME,-NAME) |
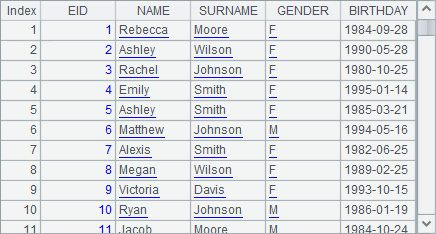
A1 retrieves all the employee records:
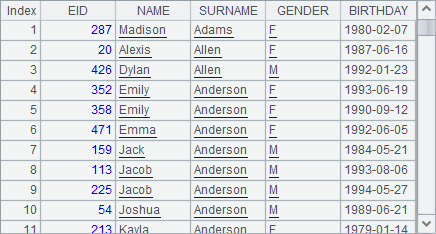
A2 sorts the data first by SURNAME and then by NAME. Result is as follows:
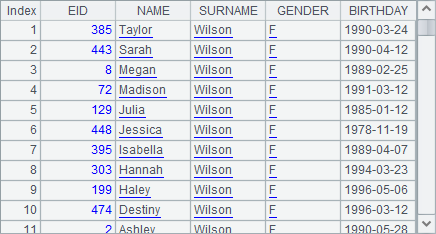
According to the last section, @z option can be added to functions like sort, psort, rank, ranks to change the sorting order. To sort data by multiple fields, you can’t use the @z option because the sorting order for each field could be different. But you can add a minus sign before the expression for the reverse sorting. In A3’s expression, for example, GENDER means sorting data by gender in ascending order and -SURNAME means sorting data by surname in descending order. Without such signs, data will be sorted in ascending order. The sorting result of A3 is as follows:
If the sorting field contains non-English strings, you can define a language parameter in sort function.
Sometimes it is the records that in the top few that you desire. Then you can use top funciton or ptop function. For example:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY from EMPLOYEE") |
|
2 |
=A1.top(5,age(BIRTHDAY)) |
|
3 |
=A1.ptop(5,age(BIRTHDAY)) |
|
4 |
=A1.top(5;age(BIRTHDAY)) |
|
5 |
=A1.top(-5,age(BIRTHDAY)) |
A2 finds the 5 youngest ages using top function. A3 gets the IDs of 5 youngest employees using ptop function. A4 retrieves the records of 5 employees with the youngest ages with top function, where the third parameter ~ represents the returned original record in A1. Here are results of A2, A3 and A4:
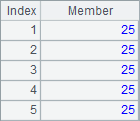
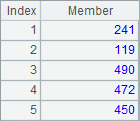
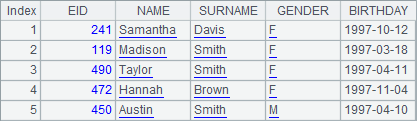
Both top function and ptop function can’t work with @z option. To find the 5 oldest ages, use a negative number as a prameter, like -5 in A5, which means getting 5 oldest ages. Here’s the result:
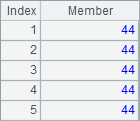
3.3.3 Computing rankings based on a TSeq
There are two common ways for computing rankings: ranking members with/without duplicate values counted. For example, if there are two players tied for first place in a competition and the duplicate ranking values are counted, the next player following them would have a third ranking. But if the duplicate ranking value isn’t counted, the second place will follow without taking the extra ranking value into account. esProc has rank function to compute the rankings and rank to compute the ranking of a certain value. The use of @i option with the functions will compute rankings or the ranking without counting the extra ranking(s). For example:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.ranks(SALARY) |
|
3 |
=A1.ranks@i(SALARY) |
|
4 |
=A1.rank(10000,SALARY) |
|
5 |
=A1.rank@i(10000,SALARY) |
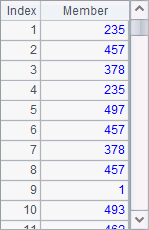
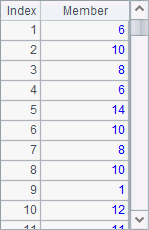
A2 computes the rankings of salaries of all employees. A3 computes them without considering duplicate values. Results of A2 and A3 are as follows:
Now let’s look at the employee data in A1:
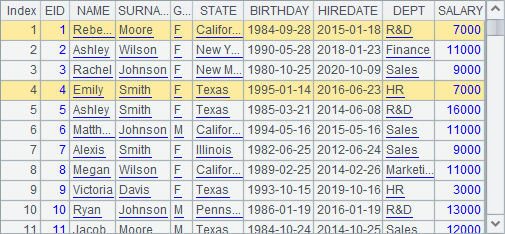
It can be seen by comparison that the employees with the same salary, such as Rebecca and Emily, get the same ranking for their salaries either way. But obviously they rank much higher in the result of A3 because duplicate ranking values are ignored and they won’t affect the rankings of the subsequent employees. In fact it is the result in A2 that reflects the rankings more objectively.
A4 computes the ranking of 10,000 among employee’s salaries. A5 computes the ranking of 10,000 by not taking the duplicate values account. Results of A4 and A5 are as follows:
![]()
![]()
A higher ranking is obtained without counting the duplicate values. rank@i and ranks@i compute rankings in a way similar to that in which id function is used to list all the unique members before computing rankings.