Merge and Join Operations on Cursors
It’s convenient or necessary to combine multiple table sequences for data analysis and computing based on them. Related functions include A.merge() function, which combines records of multiple table sequences in a certain order, A.conj() function, which unions records of multiple table sequences into a grand table, as well as JOIN functions – join, join@p and xjoin – which create association between table sequences by joining data from them for data query or computation.
Likewise, the merge and join operations apply to cursors for handling big data, too. Related functions include CS.conj(), CS.merge(x) and joinx(). Their uses are discussed below.
7.4.1 Merging data in a certain order
Most of the time, the source data is stored in multiple tables, sales records of different products and profiles of employees in different department, for example. In those cases, data from multiple data tables need to be merged for use. For multiple normal table sequences with the same structure, esProc provides A.conj() or A.merge(x) functions to merge their records into a record sequence. For data tables holding big data, CS.conj() and CS.merge(x) functions are used to combine data from their corresponding cursors in the cursor sequence CS in a certain order, and thus the data can be fetched.
Since data in a cursor will be traversed only once and will usually be fetched step by step, it isn’t feasible to perform a sort after data in multiple cursors is merged and all fetched out. Therefore, data in each cursor must be ordered as required in a same way when merging multiple cursors.
Now let’s learn about the uses of and differences between CS.conj() and CS.merge(x) through examples. First, let’s look at a simple case about union.
|
|
A |
B |
C |
|
1 |
=file("Order_Wines.txt") |
|
|
|
2 |
=file("Order_Electronics.txt") |
|
|
|
3 |
=file("Order_Foods.txt") |
|
|
|
4 |
=file("Order_Books.txt") |
|
|
|
5 |
=[A1:A4].(~.cursor@t()) |
|
|
|
6 |
=A5.conjx() |
300 |
|
|
7 |
for |
=A6.fetch(B6) |
|
|
8 |
|
if B7==null |
break |
|
9 |
|
=B7(1).Type |
=B7(B6).Type |
|
10 |
|
if B9!=C9 |
break |
|
11 |
>A6.close() |
|
|
There are four text files respectively recording the ordering information of wines, electrical appliances, foods, and books. A6 concatenates the data from four file cursors. To find out the order in which data is retrieved, 300 records are retrieved each time and the retrieval will stop once a record of a different product appears. The resulting table sequence in B7 is as follows:

As can be seen from the result, regarding the unioned cursor, after all the wine data in the first text data table is retrieved, the electrical appliance data from the second text data table follows. In other words, after data is unioned using CS.conj() function, records in the resulting cursor will be retrieved in the order of the cursors arranged in the cursor sequence CS.
But more cases require more than just the union of the records from data tables one after another, but the merging of them in a certain order. CS.merge(x) is the function for doing this. It requires that the records in each cursor of the cursor sequence CS must be already sorted by expression x. For example, sorting and merging the order data of various products by the sales date:
|
|
A |
B |
|
1 |
=file("Order_Wines.txt") |
|
|
2 |
=file("Order_Electronics.txt") |
|
|
3 |
=file("Order_Foods.txt") |
|
|
4 |
=file("Order_Books.txt") |
|
|
5 |
=[A1:A4].(~.cursor@t()) |
|
|
6 |
=A5.merge(Date) |
300 |
|
7 |
for |
=A6.fetch(B6) |
|
8 |
|
break |
|
9 |
>A6.close() |
|
The purpose of this program is to know about the order in which the records are retrieved from the merged cursor sorted in a certain order. Only the first 300 entries are retrieved, and the table sequence in B7 is as follows:

Data is fetched by Date as specified. After all wine data of January 1st is fetched, the fetching of all electrical appliance data of the same day starts. Because fetching data from the cursor is in forward-only direction, the ordering data in each cursor must be ordered by Date beforehand. After multiple cursors are merged into a grand cursor using function CS.merge() in a specified order, data will be fetched from the corresponding cursor in the cursor sequence CS according to the value of the specified expression, and a result ordered in the specified order will thus be obtained. The actual data fetching will traverse data of each file cursor only once.
Merging data in multiple cursors in a certain order simply creates a single grand cursor, and adjusts the order in which data is fetched from each cursor, without adding or deleting any records. If the cursor data isn’t in a desired order, it must be sorted before merging, as in the following example:
|
|
A |
B |
|
1 |
=file("Order_Wines.txt") |
|
|
2 |
=file("Order_Electronics.txt") |
|
|
3 |
=file("Order_Foods.txt") |
|
|
4 |
=file("Order_Books.txt") |
|
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
|
6 |
=A5.merge(PID) |
2000 |
|
7 |
for |
=A6.fetch(B6) |
|
8 |
|
break |
|
9 |
>A6.close() |
|
Before cursors are merged by PID, the data in each cursor must have been ordered by PID. That’s why A5 uses cs.sortx() function to sort data in each of the cursors corresponding to the products.
Note that the way of sorting data in a cursor is different from that of sorting data in a table sequence. A cursor contains a large amount of data which can’t be entirely loaded into the memory at once for sorting. Therefore, data will be fetched and sorted in batches, whose amount is specified. Each sorted batch of data will be saved as a temporary data file. Once data is all fetched and sorted, the temporary data files will be merged in the same order and returned as a cursor. For details about sorting cursor data, see Method of External Memory Sorting. Here are records fetched in B7:
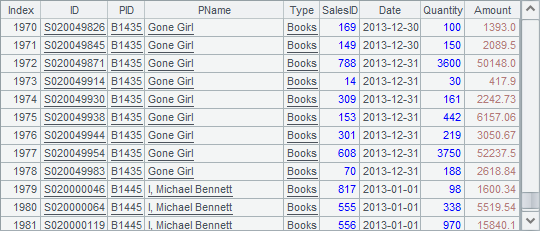
Merging data in the specified order can be accomplished after the data in each cursor is sorted.
7.4.2 Cusor-based alignment joins
The cs.switch() function can be used to join a cursor with a table sequence. But sometimes, the statistical data analysis requires joining data from multiple cursors, which is similar to joining multiple data tables.
Usually it’s impossible to retrieve all data from a cursor, so how to deal with the joining of multiple cursors? esProc offers the joinx() function to do this. For example:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=A1.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
6 |
=A2.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
7 |
=A3.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
8 |
=A4.groupx(Type,Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
9 |
=joinx@1(A5:Wines,Date;A6:Electronics,Date;A7:Foods,Date;A8:Books,Date) |
|
10 |
=A9.fetch(25) |
|
11 |
>A9.close() |
A5~A8 perform an aggregate operation over each kind of product and return a cursor for each temporary file (See detailed explanation of groupx function in Methods of External Memory Grouping for Large Result Sets). A9 joins the daily sales data of the various products by aligning the data of each product with dates. Then A10 fetches the statistical results of the first 25 days:

An alignment join of cursors also returns a cursor. Each record of the data table retrieved from the resulting cursor has record-type field values. This is similar to the result of joins between table sequences, and causes more memory usage per record compared with a record in a data table with non-record-type field values. The thing to note, with the record type values, is the format of an expression for an operation, particularly a join, using data of the resulting cursor.
The result of performing an alignment join on cursors can be reused for data handling, like filtering or generating data. For example:
|
9 |
=joinx@1(A5:Wines,Date;A6:Electronics,Date;A7:Foods,Date;A8:Books,Date) |
|
10 |
=A9.select(Foods.TotalAmount>Wines.TotalAmount) |
|
11 |
=A10.new(Foods.Date:Date,Foods.TotalAmount:Foods,Wines.TotalAmount:Wines) |
|
12 |
=A11.fetch(100) |
|
13 |
>A11.close() |
A10 adds a bundled operation to the joined cursor to select records where the total amount of food orders is greater than that of wine orders. A11 adds the bundled operation too to get the result, and A12 returns the first 100 records:

In performing the cusor-based alignment joins, you should have in mind that the cursor data can only be traversed once in a forward-only direction and can’t be fetched into the memory to store. Therefore data in each of the multiple cursors being joined must be already sorted in a same way, which is different from handling the multi-database-table join and the join() operation for ordinary table sequences. In the above example, the data in all cursors in A5~A8 is sorted by Date to ensure a correct join. In order to better explain this point, cursors are generated using two small in-memory table sequences:
|
|
A |
|
1 |
$select * from CITIES |
|
2 |
$select * from STATES |
|
3 |
=A1.cursor() |
|
4 |
=A2.cursor() |
|
5 |
=joinx(A3:City,STATEID;A4:State,STATEID) |
|
6 |
=A5.fetch() |
The table sequences in A1 and A2 are as follows:


Here’s the result of alignment join in A6:

Different from data in an ordinary table sequence, cursor data is traversed once in a forward-only manner. During this alignment join, it is the 32th record where the New York state corresponding to the New York city in the 1st record is located. So in the state table cursor the records before the 32th record become unavailable, making many cities in the city table cursor unable to find their home states. Without @1 and @f options for specifiying a left join or a full join, the join@x() function only returns the several cities that have found their home states.
But if the cities are first sorted, a desired result can be obtained:
|
|
A |
|
1 |
$select * from CITIES order by STATEID |
|
2 |
$select * from STATES |
|
3 |
=A1.cursor() |
|
4 |
=A2.cursor() |
|
5 |
=joinx(A3:City,STATEID;A4:State,STATEID) |
|
6 |
=A5.fetch() |
A1 returns the city data sorted by STATEID:

Now the result of join in A6 is as follows:

Joining data from multiple cursors doesn’t require the same cursor type. For example:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t().sortx(State) |
|
3 |
$(demo) select STATEID, NAME, ABBR from STATES order by ABBR |
|
4 |
=A3.cursor() |
|
5 |
=joinx(A2:PersonnelInfo,State;A4:State,ABBR) |
|
6 |
=A5.fetch(100) |
|
7 |
>A5.close() |
A5 joins personnel records with the corresponding state records. Make sure that the cursor data has already been sorted. A6 fetches the first 100 records:

Usually, the aim of joining a cursor with another is to get certain information from it, as in the above example where the purpose of join is to get the full names of the employees’ home states from a table sequence. In that case, besides the join operation, an alternative method is using the cs.switch() function, which can convert values of the related field of cursor cs to the corresponding records of the table sequence. The function’s use is covered in Basic Uses of Cursor. Difference between joinx() and cs.switch() is that the former joins records from different cursors, whereas the latter establishes a foreign key relationship between a certain field of a cursor and a table sequence or a sequence used as a dimension table. The joinx() function for joining cursors requires that their data be sorted by the field according to which they are joined. cs.switch() hasn’t such a requirement as the corresponding dimension table can be referenced directly from the memory.
We can also join a cursor to a segmentable bin file:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t(ID,Name,City,State) |
|
3 |
$(demo) select * from STATES order by ABBR |
|
4 |
=file("StateFile.btx") |
|
5 |
>A4.export@b(A3;ABBR) |
|
6 |
=A2.joinx(State,A4:ABBR,NAME:SName,CAPITAL:SCapital;10000) |
|
7 |
=A6.fetch(100) |
|
8 |
>A6.close() |
A5 generates a segmentable bin file StateFile.btx according to state data in the database. The bin file should be ordered by the joining key, which is ABBR field in this case. A6 joins the cursor and the bin file using cs.joinx(C:…, f:K:…, x:F,…;…;n) function. The function matches cursor cs’s C:… field with key K:… in bin file f to find eac corresponding record, calculates expression x over the record, and adds the result to the cursor as an F field value. Parameter n sets the maximum number of buffer rows. The function only requires that the bin file be ordered by the key. A6 finds the matching state records from the bin file containing state data by state abbreviations, gets the state names and their capitals to form two new fields – Sname and SCapital. A7 fetches the first 100 records from A6:

To append a field to a cursor, a composite foreign key is sometimes used to reference records of a table sequence or another cursor when establishing a foreign-key relationship. In those cases, the cs.join() function is used to do that. For example:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t() |
|
3 |
$(demo) select STATEID, NAME,ABBR from STATES |
|
4 |
=create(Month,State,GroupID) |
|
5 |
>A3.(12.((m=~,A4.insert(0,m,A3.ABBR,A3.ABBR+string(m))))) |
|
6 |
=A2.join(month(Birthday):State,A3:Month:State,GroupID:Group) |
|
7 |
=A6.fetch(100) |
|
8 |
>A6.close() |
A4 creates a table sequence based on months and the states’ abbreviations, and A5 inserts detailed data into it. Here’s A4’s table sequence:

A6 appends a field to A2’s cursor using cs.join(). The function first performs an equi-join between A2’s cursor and A4’s table sequence by comparing the former’s month of Birthday field and State field and the latter’s Month and State fields, and then retrieves GroupID field from A4’s table sequence to add it after the State field in the joining result. A7 fetches the first 100 records:

cs.join() allows joining fields of cursor cs with a table sequence. Different from joinx(), cs.join() doesn’t require data in the cursor cs be sorted. cs.switch(), however, can’t handle this example where two fields of the cursor cs need to be joined with the dimension table.