Operations on TSeqs and RSeqs
The esProc table sequence is a two-dimensional structured table, having concepts of field, record, primary key and index. These concepts originate from the data table of relational database. A table sequence is also an explicit set of genericity and orderliness, on which you can perform structured data computing more flexibly. A record sequence is the reference of the records of the table sequence. The two are closely related and have basically the same uses. This part will explain the basic TSeq and RSeq operations from aspects of access, loop functions, aggregate functions and set operations.
2.5.1 Access
Creation
In the cellset below, A1 reads two-dimensional structured data from the file to create a table sequence object and stores it. B1 peforms a query on A1 to create a record sequence object and store it:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
After computation A1 gets the following table sequence. Here only part of the table seqeunce is displayed. You can drag the scrollbar on the right to view all the records:

The record sequence in B1 is as follows:

Note: A table sequence object can be created based on a database or a file, or by inserting records into an empty object. A record sequence originates from one or more table sequences but it doesn’t store physical records. It only stores the references of some records in the table sequence(s).
Accessing field values
In the cellset below, A2 retrieves the PName field of the twentieth record of the table sequence object A1 and store it, and B2 retrieves the PName field of the second record of the record sequence object B1 and store it:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1(20).PName |
=B1(2).PName |
The results of A2 and B2 are as follows:
![]()
![]()
As the second record in B1 is the reference of the twentieth record in A1, A2 and B2 have the same results. According to the expressions of A2and B2, both table sequence and record sequence have completely the same syntax for field accessing.
A field name can be replaced by the field’s ordinal number and the result won’t change. As with this example, A2 can be written as =A1(20).#3. Because the replacement is employed universally in esProc, we won’t go into details about it in the following examples.
To get field values from a table seqeunce or a record, you can also use field function and array function. For example:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.field(2) |
|
2 |
=A1(20).field(2) |
=A1(20).array(PName) |
|
3 |
=A1(20).array(PID,PName) |
=A1(20).array() |
With field function, you can get values of fields with a certain number. Here are results of B1 and A2:

![]()
With array function, you can get field values from a record by specifying one or more field names. Without the specification, the function returns a sequences consisting of all field values of the record. Here are results of B2, A3 and B3:
![]()


Accessing column data
In the cellset below, A2 retrieves PName column from table sequence A1according to the name and store it, and again from table sequence A1, B2 retrieves PName column and Amount column according to names and store them. The record sequence and table sequence have the same syntax for column accesing. Here take the table sequence:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1.(PName) |
=A1.new(PName,Amount) |
The results of A2 and B2 are as follows:


Using the syntax of T.(x), you can only retrieve one column of data as a sequence without the structured column name. With T.new() function, however, you can retrieve one or more columns of data as a table sequence with structured column names.
Whether the object of computation is a table sequence or a sequence, both T.new() function and A.new() function will create a new table sequence. This means the result of B1.new(PName, Amount)is also a table sequence.
Accessing row data
In the following cellset, A2 fetches the first two records from table sequence A1 according to row numbers and stores them. B2 fetches the first two records from table sequence B1 according to row numbers and stores them. Both the record sequence and table sequence use the same syntax for row accessing:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1([1,2]) |
=B1([1,2]) |
A2’s result is as follows:

B2’s result is as follows:

2.5.2 Loop functions
With encapsulated complex loop statements, loop functions can perform the same computation on each record of a table sequence/record sequence. For instance, select is for data querying, sort for data soting, id for getting distinct records, and pselect for fetching ordinal numbers of the records satisfying the specified condition(s). Here the most basic ones - select function and sort function- will be illustrated. For more information about loop functions, please refer to Loop Computations.
Data querying
The following cellset code finds out records whose Amount field is greater than or equal to 20,000 and whose Date is in the month of March. As both record sequence and table sequence have the same syntax for data querying, only the latter is used for our illustration:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>=20000 && month(Date)==3) |
B1’s result is as follows:

Whether the object of computation is a table sequence or a record sequence, the result of select function will always be a record sequence, that is, the references of records instead of the physical records.
Data sorting
In the following cellset, records are sorted in ascending order according to SalesID field, and those having the same SalesID are then sorted in descending order according to Date field. The syntax is same when sorting a record sequence and a table sequence. Here take the record sequence in B1 as an example:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=B1.sort(SalesID,-Date) |
|
A2’s result is as follows:

Whether the object of computation is a table sequence or a record sequence, the result of sort function will always be a record sequence. In fact, except for record modification, most of the functions can be used to handling table sequences and record sequences.
2.5.3 Aggregate functions
Finding maximum value
Here the computing goal is finding the maximum value of Amount field. Since the syntax for performing this operation on the record sequence and table sequence is same, we just take table sequence A1 as an example:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1.max(Amount) |
|
A2’s result is as follows:
![]()
Other aggregate functions include min(for finding the minimum value), sum(for calculating sum), avg(for calculating average), count(for counting), etc.
Calculating sum by group
The following cellset code groups records by SalesID and the month, and then sums Amount and counts orders for each group. The syntax for performing this operation on the record sequence and table sequence is same, and we just take the table sequence A1 as an example:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>20000) |
|
2 |
=A1.groups(SalesID, month(Date); round(sum(Amount),2), count(~)) |
|
A2’s result is as follows:

Note: groups function generates a new table sequence. The sign “~” in expression count(~) represents the current group. The expression can also be written as count(ID). Since the code doesn’t designate field names for the result, default field names like month(Date) are used. You can use a colon to specify a field name, as with =A1.groups(SalesID, month(Date):Month;sum(Amount),count(ID)).
2.5.4 Set operations
Set operations include intersection “^”, union “&”, difference “\” and concatenation “|”, etc.
Intersection and union operations
In the following cellset, A2 stores records of the orders whose Amount is greater than and equal to 20,000 and whose Date is in the month of March, and B2 stores those whose SalesID is equal to 540 or 992. Now find the intersection and difference of A2 and B2, and store results respectively in A3 and B3:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
=A1.select(Amount>=20000 && month(Date)==3) |
=A1.select(SalesID==540 || SalesID==992) |
|
3 |
=A2^B2 |
=A2\B2 |
The record sequence in A2 is as follows:

The record sequence in B2 is as follows:

A3 calculates the intersection. The result is a record sequence:

A3 calculates the difference by removing members of B2 from A2. The result is still a record sequence:

Let’s move on to the intersection and difference operations on sequences or record sequences generated from different table sequences. First generate new table sequences by copying the the record sequences (or sequences in other times) with the derive() function, and then calculate the intersection and the difference:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
=A1.select(Amount>=20000 && month(Date)==3) |
=A1.select(SalesID==540 || SalesID==992) |
|
3 |
=A2.derive() |
=B2.derive() |
|
4 |
=A3^B3 |
=A3\B3 |
The records of the table sequences in A3 and B3 are the same as the records in A2 and B2 in the previous example.
A4 calculates the intersection of A3 and B3. The result is an empty set:

This means, as the sets of physical members, different table sequences have different members and the intersection of them will always be empty. Thus the operation has no practical significance in business.
B4 calculates the difference of A3 and B3. As members of two table sequences are always different, the result of difference operation is still A3:

Only set operations performed on record sequences originating from the same TSeqs have business significance. It makes no sense in realworld businesses to perform intersection and difference between different TSeqs or RSeqs originating from different TSeqs.
Union and concatenation operations
In the following cellset, A2 selects records of oders whose SalesID equals 540 and 992 from the record sequence in B1 to create another record sequence and store it, and B2 finds out records of orders whose SalesID equals 540 and 668 from B1’s record sequence and store it. Now find the union and concatenation of A2 and B2 and store the results respectively in A3 and B3:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>=20000 && month(Date)==3) |
|
2 |
=B1.select(SalesID==540 || SalesID==992) |
=B1.select(SalesID==540 || SalesID==668) |
|
3 |
=A2&B2 |
=A2|B2 |
The record sequence in A2 is as follows:

The record sequence in B2 is as follows:

A3 calculates the union of A2 and B2 by combining members of the two sets in order and removing the duplicate members.

B3 calculates concatenation of A2 and B2 by concatenating members of the two sets in order and retaining the duplicate members.

Next let’s look at union and concatenation operations between differernt table sequences:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.select(Amount>=20000 && month(Date)==3) |
|
2 |
=B1.select(SalesID==540 || SalesID==992) |
=B1.select(SalesID==540 || SalesID==668) |
|
3 |
=A2.derive() |
=B2.derive() |
|
4 |
=A3&B3 |
=A3|B3 |
Records of table sequences in A3 and B3 are the same as those in A2 and B2 in the previous example.
A4 calculates union of A3 and B3. As members of the two table sequences are totally different, the union operation means a simple union-all of the two, with the same result as that of the concatenation operation:
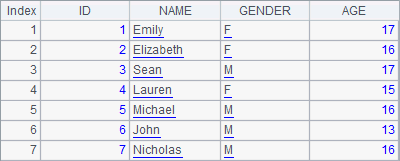
B4 calculates concatenation of A3 and B3. The result is the same as the union in A4: