The Built-in Parallelism
Later in Multithreading, we will discuss how to increase efficiency through multithreaded computation. Besides using fork statement in the cellset code to achieve the multithreaded parallel processing, esProc also packages the parallel computing approach into some functions. We’ll cover this in the following.
Parallel data retrieval
We can retrieve data from data tables through multithreaded processing, if the order of records is irrelevant to the result. This type of processing can make full use of the system resources, thereby enhancing the efficiency. Use @m option with f.import() function to use the multithreaded parallel processing.
You can use the multithreaded parallel processing to retrieve data from a single data file:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
=now() |
|
2 |
=A1.import@t() |
=now() |
|
3 |
=A1.import@mt() |
=now() |
|
4 |
=string(interval@ms(B1,B2))+"/"+string(interval@ms(B2,B3)) |
|
A2 imports data directly; while A3 uses f.import@m() to import data with multithreads. A4 compares the time the two methods use and gets the following result:
![]()
Retrieving data in parallel can significantly improve performance.
While data is retrieved from a single data file using multithreads, the multithreaded system will divide the file into multiple segments and every segment will be retrieved through a file cursor. Each file cursor uses a separate thread for the data retrieval, which resembles the above example where files are retrieved using multithreaded processing. For more information about retrieving data by segment in esProc, read Bin Files.
Because data is retrieved from a single data file by parallel processing, the order of records in the returned result is irregular too
With f.import@m(), the number of threads it uses is determined by the specified number of parallel tasks. The property is configured on the General page by clicking Tool>Option on esProc’s menu bar:

Merging cursors in a certain order
There is another operation that specifically requires parallel processing. That is merging cursors in a certain order, i.e. CS.merge(). For example:
|
|
A |
B |
|
1 |
=file("Order_Wines.txt").cursor@t() |
=file("Order_Foods.txt").cursor@t() |
|
2 |
=file("Order_Electronics.txt").cursor@t() |
=file("Order_Books.txt").cursor@t() |
|
3 |
=[A1:B2].merge(Date) |
=A3.fetch(10000) |
|
4 |
>A3.close() |
|
A3 merges the ordering data from four text files by date and generates a new cursor.
In the process of merging cursors in a certain order, you need to judge from which cursor the data should be fetched according to the sorting expression. So cursors should be all in place throughout the computation, which is handled also by the multiple threads. esProc provides the smart use of parallel processing to deal with the order-based cursor merge wthout using @m option.
B3 fetches the first 10,000 rows:
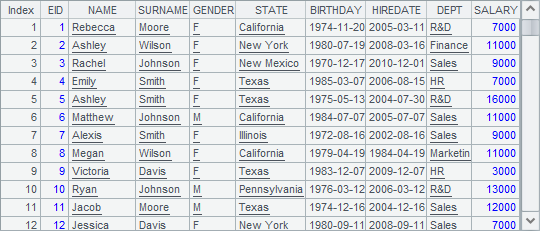
To learn more about the cursor merge, see Merge and Join Operations on Cursors.