Cross-cellset Cursor
Concept of Cursor only touches on the preliminaries of the cross-cellset cursor. Here we’ll delve into more issues about it.
Basic uses
The cross-cellset cursor is typically used to handle big data analysis and computing, but it doesn’t impose a minimum limit on data volume. First look at a case with relatively small data volume. Here’s the cellset D:\files\FindEmployees1.splx:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE where DEPT = ?;arg1 |
|
2 |
>output("before return") |
|
3 |
return A1 |
The program in the cellset is simple. It retrieves data of employees in a certain department and returns a table sequence in A3 using a return statement. A2 uses output() function to output the execution information and status to the console. The arg1 used in A1 is a cellset parameter specifying the department name. The parameter can be set by clicking Program>Parameter on the menu bar:

Subroutines discussed the method of executing a program in another cellset file via call function. The cross-cellset cursor has a similar use, except that it will return a cursor using the cursor function. It calls the above cellset file in the main cellset program as follows:
|
|
A |
|
1 |
=cursor("FindEmployees1.splx";"Sales") |
|
2 |
>output("before fetch") |
|
3 |
=A1.fetch() |
While creating a cross-cellset cursor with the cursor function, directly write the name of the to-be-invoked script file. Enter the parameter, if needed, after the file and use a semicolon to separate them. After the program is executed, the result of A1 is a cross-cellset cursor that is used in the same way as an ordinary cursor:
![]()
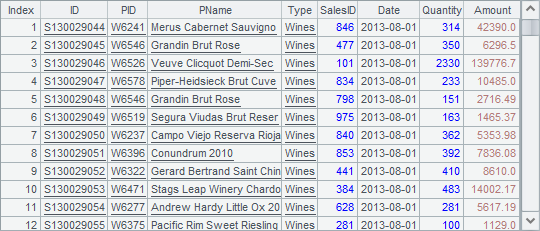
Using the fetch function, A3 returns a table sequence of employees of sales department:
Both cellsets use output function that outputs characters to the console during the execution, thus you can clearly see the execution order in the cellset. Click Tool>Options on the menu bar and then select Console takeover on the General page to see the output information:

It can be seen that the program in a specified cellset will only be invoked to kick off the cross-cellset computation when fetch starts to fetch data.
A1 calls the script file without using its full path. But this requires that the file is placed into esProc’s main path or search path, whose configuration is the same as that in the cross-cellset call by call function. The configuration process will be explained again below.
Click Tool>Options on the menu bar to configure the main path and the search path on the Environment page, as shown below:

As in the above configuration, the script file can be invoked only by its name without the necessity of writing the full path, regardless of being placed in the main path or under any directory of the search path.
In the case of being integrated, the main path and search path of the script file need to be configured in the configuration file raqsoftConfig.xml:
<splPathList>
<splPath>E:\tools\raqsoft\esProc\demo\Case\Structural </splPath>
<splPath>D:\files\txt;D:\files</splPath>
</splPathList>
<mainPath>D:\files\demo</mainPath>
Cellsets that return multiple results
A cellset file to be invoked through the cross-cellset cursor could return multiple results, as D:\files\FindEmployees2.splx shown below:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE where DEPT = ?;arg1 |
|
2 |
return A1.select(GENDER=="F") |
|
3 |
return A1.select(GENDER=="M") |
This cellset program queries the database to get data of employees in a certain department, and returns two record sequences, composed respectively of data of female employees and of male employees, in A2 and A3 separately using two return statements. It sets the same cellset parameter as the previous section did.
Then the cellset program is called in the main cellset to generate a cross-cellset cursor:
|
|
A |
|
1 |
=cursor("FindEmployees2.splx") |
|
2 |
=A1.fetch() |
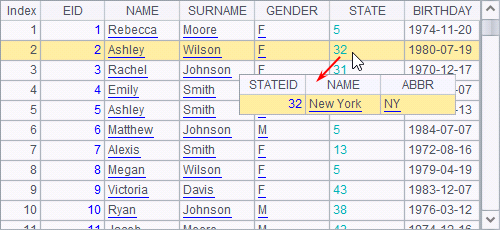
While creating a cross-cellset cursor with the cursor function without specifying a parameter, use the default cellset parameter value, which is the HR department in this instance. After execution A2 returns result as follows:
The first half of the resulting table sequence is female employees in HR department and the second half is the male employees in the department. You can see that the cross-cellset cursor will join in due order the multiple results that are returned via multiple return statements by the cellset being invoked.
For the invocation of the cellset that returns multiple results, the results must have the same data structure because they will be returned altogether by one cross-cellset cursor. Otherwise errors will occur.
In order to see the detailed execution process, the output statements are used in the cellset to be invoked, as shown in the following cellset D:\files\FindEmployees3.splx:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE where DEPT = ?;arg1 |
|
2 |
>output("return GENDER F") |
|
3 |
return A1.select(GENDER=="F") |
|
4 |
>output("return GENDER M") |
|
5 |
return A1.select(GENDER=="M") |
In this cellset, the program queries the database to get data of employees in a certain department, and returns two record sequences, composed respectively of data of female employees and of male employees, in A3 and A5 separately using two return statements. Here the same cellset parameter is used. The cellset program is called by a cross-cellset cursor:
|
|
A |
B |
|
1 |
=cursor("FindEmployees3.splx") |
[] |
|
2 |
for A1,5 |
>output("fetch"+string(#A2)) |
|
3 |
|
>B1=B1|A2 |
In our examples, the cross-cellset cursor only contains a very small volume of data, but this is sufficient for explaining the cross-cellset invocation through the cursor. A2 loops through data in the cursor and fetches five records each time. B2 outputs the execution information during loops. B3 concatenates the records returned from the cursor into B1’s record sequence. After the program is executed, B1gets the same result as the previous instance – records of female and male employees in HR department. The output information received by the console is as follows:

As can be seen from the output information, during the invocation of FindEmployees3.splx by the main cellset, the program will be executed step by step according to the specified way of returning the records. So it is only after all the records of female employees in A3 have been returned that the fetching of records of male employees begins.
Cellsets that return data by loop
When a cellset program returning a large amount of data through the cursor is invoked to generate a cross-cellset cursor, you can use multiple return statements separately to return multiple results, which then will be concatenated in the main cellset. But a more common way is running a loop to return the large amount of cursor data in batches and the returned results will be automatically concatenated when they are being fetched in the main cellset program. D:\files\Order1.splx is such a cellset file for invocation:
|
|
A |
B |
|
1 |
=file("Order_Books.txt") |
=A1.cursor@t() |
|
2 |
for B1,5000 |
return A2 |
A2 fetches data from the cursor by loop and B2 returns each batch of data as a table sequence using the return statement. This is not the way used in the previous example that the whole table sequence or record sequence is returned at a time. In the main cellset, the cross-cellset cursor works in completely the same way as those in the above:
|
|
A |
|
1 |
=cursor("Order1.splx") |
|
2 |
=A1.fetch(1000) |
|
3 |
>A1.close() |
The cross-cellset cursor returns huge data. A2 only fetches the first 1,000 records:

Since not all data in the cross-cellset cursor is fetched out, it needs to be closed deliberately in A3. Once the cross-cellset cursor closes, the cursor in the cellset being invoked will close simultaneously.
Cursor data can also be returned as multiple cursors using multiple return statements. In this case data in every cursor will be concatenated together and fetched as a whole. This is the same as the case in which multiple record sequences are returned. So the data in every cursor should have the same data structure.
Applications
By invoking a cellset file, the cross-cellset cursor performs computations and returns result as a cursor. This allows us to use the cellset file to deal with some complicated data processing tasks. During the big data analysis and processing, for example, text data is often used as the source data. But as it is not as orderly as the database data, it should be rearranged by a routine. In this case the cross-cellset cursor is used to call this separate routine.
D:\files\EmployeeMul.txt contains employee data, as shown below:
|
1 |
Nicole Jones |
F |
2009-08-01 |
|
1990-01-03 |
Philadelphia |
Pennsylvania |
Production |
|
36801 |
NicoleJones_PA@mail.xxx |
|
|
|
2 |
Tammy Powell |
F |
2010-09-29 |
|
1992-07-31 |
Pittsburgh |
Pennsylvania |
Technology |
|
43711 |
TammyPowell2@mail.xxx |
|
|
|
3 |
Jack Anderson |
M |
2007-04-12 |
|
1984-08-26 |
Cleveland |
Ohio |
R&D |
|
36094 |
JackAnderson_OH@mail.xxx |
|
|
|
4 |
Margaret Morales |
F |
2014-03-18 |
|
1992-11-12 |
Washington |
Washington |
Sales |
|
48983 |
MargaretMorales4@mail.xxx |
|
|
|
5 |
Willie Roberts |
M |
2012-07-06 |
|
1988-07-01 |
Plano |
Texas |
Technology |
|
43711 |
WillieRoberts5@mail.xxx |
|
|
|
6 |
Todd Gray |
M |
2009-01-04 |
|
1981-09-06 |
Baltimore |
Maryland |
R&D |
|
36094 |
ToddGray_MD@mail.xxx |
|
|
|
7 |
Kevin White |
M |
2007-04-19 |
|
1986-07-10 |
Minneapolis |
Minnesota |
Technology |
|
43711 |
KevinWhite_MN@mail.xxx |
|
|
|
…... |
|
|
|
In this text file, data of each employee hold information of ID, name, gender, entry date, birthday and city, etc. in three lines. It is common for a text file to save a record with many fields in multiple lines. The task is to find the data of Philadelphian employees from the file.
The text file cannot be used directly for computation, because esProc requires that each line of data in the file be a record when directly importing text data as a table sequence or a cursor. Data in the EmployeeMul.txt file should be reorganized before the file can be used for analysis and computing. The program will become more intuitive if a cross-cellset cursor is used. First you can reorganize the data in mergeRecord.splx:
|
|
A |
B |
C |
D |
|
1 |
=file("EmployeeMul.txt").cursor() |
|
|
|
|
2 |
for A1,5000*3 |
=A2. step(3,1) |
=A2. step(3,2) |
=A2. step(3,3) |
|
3 |
|
=join@p(B2:L1;C2:L2;D2:L3) |
=B3.new(L1.#1:ID,L1.#2:Name,L1.#3:Gender,L1.#4:EntryDate,L2.#1:Birthday,L2.#2:City,L2.#3:State,L2.#4:Dept,L3.#1:SuperiorID,L3.#2:MailAdress) |
|
|
4 |
|
return C3 |
|
|
A1 imports the text file as a cursor. A2 fetches 5000*3 records each time and joins the fetched data within its statement block. For every three records, B2, C2 and D2 respectively fetch the first one, the second one and the third one to create a record sequence. The table sequences they create with the last loop are separately shown below:
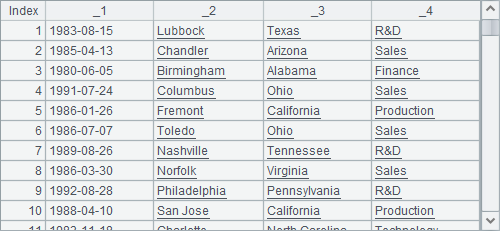
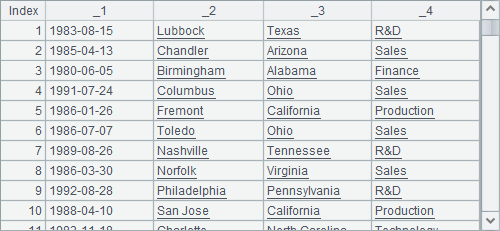

Only the first two columns of data in D2 are valid. B3 joins the three table sequences using join@p function:

After all this C3 can generate the desirable records using the source data:

Then the computation required by the task will be easily handled by invoking mergeRecord.splx through the cross-cellset cursor.
|
|
A |
|
1 |
=cursor("mergeRecord.splx") |
|
2 |
=A1.select(City=="Philadelphia") |
|
3 |
=A2.fetch() |
A cross-cellset cursor allows preprocessing the complicated multi-line records in a sub-cellset, making the program focused, concise and readable. It is particularly handy in performing analysis and computation based on a big data file. Data volume is not large in this example, so A3 fetches all data of Philadelphian employees at once:

Sometimes the text data has a more complicated format besides the need of combining multiple lines of data into a record, as the following D:\files\mailInfo.txt shows:

The file contains emails including recipient addresses, sender addresses and contents, which start respectively with RECIPIENT:, SENDADDRESS: and CONTENT:. As the number of lines in each mail’s content is different, it makes it impossible to import and combine a specified number of rows of data and to use them directly. Yet esProc supports the cross-cellset cursor through which data is allowed to be first reorganized in another cellset - readMail.splx:
|
|
A |
B |
C |
|
1 |
=file("mailInfo.txt").cursor@s() |
>A1.skip(2) |
="" |
|
2 |
for A1,5000 |
=C1+A2.(#1).concat("\r\n") |
=B2.split("RECIPIENT:") |
|
3 |
|
if A1.fetch@0(1) |
=C2.len() |
|
4 |
|
|
>C1="RECIPIENT:"+C2(C3)+"\r\n" |
|
5 |
|
|
>C2=C2.to(2,C3-1) |
|
6 |
|
else |
>C2=C2.to(2) |
|
7 |
|
=C2.regex("(.+)[\\s\\S]+" +"SENDADDRESS:(.+)[\\s\\S]+" +"CONTENT:([\\s\\S]+)"; Recipient,SendAddress,Content) |
|
|
8 |
|
return B7 |
|
A1 creates a cursor based on the text file. B1 skips the first two lines of meaningless data. Since how many lines in the text file are needed to form a record can’t be predetermined and thus needs extra consideration. C1 stores the unprocessed data left by each loop.
A2 runs a loop to fetch 5,000 rows from the cursor each time. B2 concatenates the fetched data into a big string, placing the unprocessed data left by the previous loop at the head of each batch of data. Since each email starts with RECIPIENT:, C2 splits the big string into a sequence by it. The first member of the newly-created sequence will be an empty row and you cannot confirm if its last member has been processed. So the data will continue to be processed from the 3rd to the 7th line. B3 uses @0 option in cs.fetch () function to judge if the cursor data has all been fetched out, rather than really fetching data from the cursor. If not all has been fetched out, the remaining data will be stored in C1. For the first batch of data, results of B2 and C2 are as follows:
![]()
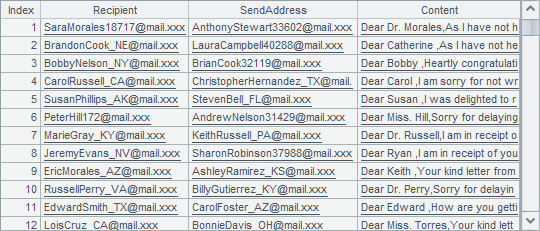
B7 performs regular expression parsing on each row of data in C2 using regex function. According to another two key words SENDADDRESS: and CONTENT:, it fetches the desirable data and makes them the field values. As the regular expression string used here is long, it is splitted into multiple smaller strings for easier viewing. The following figure shows the parsing result of the first batch of data in B7:

B8 returns the parsing result of each batch to the main program.
Despite the complexity of the parsing process, the main program fetches data simply using a cross-cellset cursor, whose use is nothing different from an ordinary cursor.
|
|
A |
|
1 |
=cursor("readMail.splx") |
|
2 |
=A1.fetch(1000) |
|
3 |
>A1.close() |
A2 fetches the first 1,000 rows: