Text Files
Sources of data used for analysis usually fall into two categories: the database source and the file source. Compared with the database data, the file data is simple to deploy and publish. The problem is that, since a file is generally used as a whole and thus needs to be loaded into the memory all at once, it becomes hard to handle when being big. In response to this problem, esProc provides support for big data handling by offering the solution of retrieving a large file with the cursor. That makes the use of file data more convenient.
This part takes text data – the most common form of external file data – to explore how to manipulate file data in esProc.
7.7.1 Basic use of text data
The file function and import function are used to read data from text files. For example, the text file employee.txt holds information of 500 employees, as shown below:
|
EID |
NAME |
SURNAME |
GENDER |
STATE |
BIRTHDAY |
HIREDATE |
DEPT |
SALARY |
|
1 |
Rebecca |
Moore |
F |
California |
1984-09-28 |
2015-01-18 |
R&D |
7000 |
|
2 |
Ashley |
Wilson |
F |
New York |
1990-05-28 |
2018-01-23 |
Finance |
11000 |
|
3 |
Rachel |
Johnson |
F |
New Mexico |
1980-10-25 |
2020-10-09 |
Sales |
9000 |
|
4 |
Emily |
Smith |
F |
Texas |
1995-01-14 |
2016-06-23 |
HR |
7000 |
|
5 |
Ashley |
Smith |
F |
Texas |
1985-03-21 |
2014-06-08 |
R&D |
16000 |
|
6 |
Matthew |
Johnson |
M |
California |
1994-05-16 |
2015-05-16 |
Sales |
11000 |
|
7 |
Alexis |
Smith |
F |
Illinois |
1982-06-25 |
2012-06-24 |
Sales |
9000 |
|
8 |
Megan |
Wilson |
F |
California |
1989-02-25 |
2014-02-26 |
Marketing |
11000 |
|
9 |
Victoria |
Davis |
F |
Texas |
1993-10-15 |
2019-10-16 |
HR |
3000 |
|
… |
|
|
|
|
|
|
|
|
esProc sets rules for the format of the data table that has a text data source: Records must be separated by the carriage return and fields should be separated by the tab. Text data can be imported using simple code:
|
|
A |
|
1 |
=file("employee.txt") |
|
2 |
=A1 .import@t() |
|
3 |
=A1 .import() |
In esProc, import function is used to import the file data as the table sequence. In the above cellset, A1 creates a file object. If the path hasn’t been specified in the file name, it can be found in the main path specified on the settings page. Click on Tool>Options on the menu bar to view or set the main path on the Environment page of Option window:

A2 imports the file as a table sequence. The use of @t option in the import function will import the text file’s first row as the column names. For a clearer comparison, the option is omitted in A3’s data importing. After the code is executed, A2’s table sequence is as follows:

Not all files use tab as the field separator. The CSV file, for instance, uses commas. You can specify a separator when using import. For example, A2’s code can be modified as =A1 .import@t(;,","). A3 generates a table sequence as follows:

With the absence of @t option, the table sequence’s field names will be automatically generated and named _1,_2,_3 according to their positions.
When text data is being imported, its data type will be automatically parsed according to the data type of the first row. As the first row of employee.txt holds field names, all data of A3’s fields will be parsed into strings, like column _1 and column _9 in the result above, which are left-justified. While the data types in A2’s EID field and SALARY field are integer, and, therefore, data is right-justified.
You can import only some of the fields of a text file to generate a table sequence:
|
|
A |
|
1 |
=file("employee.txt") |
|
2 |
=A1.import@t(EID,NAME,BIRTHDAY,SALARY) |
|
3 |
=A1.import(#1,#2,#6,#9) |
The use of @t option in A2 allows directly using names to specify to-be-imported fields. Here’s A2’s result:
Without @t option, A3 specifies the to-be-imported fields with their serial numbers in the format of #i. Here’s the resulting table sequence:
As mentioned above, during text data importing, data type will be automatically parsed according to that of the first row. But if a particular data type is wanted, it can be defined for the specified fields to be imported. For example:
|
|
A |
|
1 |
=file("employee.txt") |
|
2 |
=A1.import@t(EID:string,NAME,BIRTHDAY:date,SALARY:int) |
|
3 |
=A1.import(#1:string,#2,#6:date,#9:int) |
esProc provides the following choices for data type specification:
|
Settings |
string |
int |
float |
long |
decimal |
date |
datetime |
time |
bool |
|
Data types |
String |
Integer |
Floating point number |
Long integer |
Big decimal |
Date |
Date/time |
Time |
Boolean |
Refer to Basic Data Types to learn more.
A2 specifies data types for EID field, BIRTHDAY field and SALARY field as string, date and integer respectively. After execution, A2’s table sequence is as follows:
As A2, A3 specifies the same data types for those fields. The resulting table sequence is as follows:
It can be seen that if certain data of a field cannot be parsed into the specified data type, it will be parsed automatically, like the title row, which has been automatically parsed into strings.
About computations after data is imported, see Operations on TSeqs and RSeqs.
esProc also offers T(fn, Fi, …; s) function to retrieve data from the file and return it as a table sequence by specifying the file name and the to-be-used field names. For example:
|
|
A |
|
1 |
employee.txt |
|
2 |
=T(A1, EID,NAME,BIRTHDAY,SALARY; "\t") |
|
3 |
=T(A1, EID,NAME,BIRTHDAY,SALARY) |
|
4 |
=T@b(A1, EID,NAME,BIRTHDAY,SALARY) |
|
5 |
=T@c(A1, EID,NAME,BIRTHDAY,SALARY).fetch@x(100) |
In the T() function, if separator s is tab \t, it can be omitted; if the to-be-used fields Fi, … are not specified, all fields will be retrieved. The function returns the same result as import() function, so A2 and A3 have the same result, as shown below:
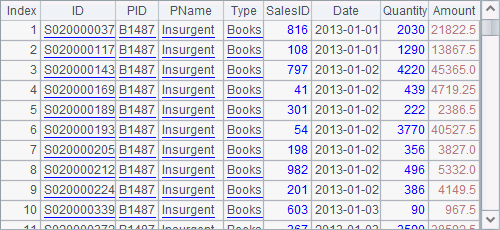
T() function does not support specifying data types for fields and by default uses the first row as field names. It works with @b option to not to display the field names, and can use @c option to import file data as a cursor. Here are results of A4 and A5:
T() function automatically judges which data file it will use according to the file extension. In addition to the txt file, it works with various other types of files, including csv, xls, xlsx, and btx (bin file) and ctx (composite table file), which we will mention later.
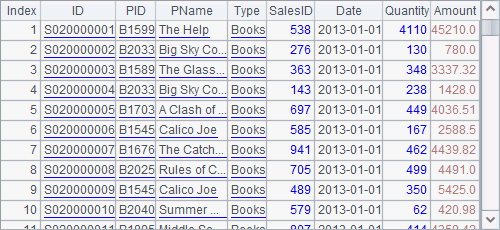
T() function can retrieve data from a file as a table sequence. esProc also provides similar E() function to retrieve a two-dimensional sequence as a table sequence. For example:
|
|
A |
B |
C |
D |
|
1 |
EID |
NAME |
BIRTHDAY |
SALARY |
|
2 |
1001 |
Frank |
2001-01-25 |
7000 |
|
3 |
1002 |
Harry |
2003-12-14 |
9000 |
|
4 |
=[[A1:D1],[A2:D2],[A3:D3]] |
|
|
|
|
5 |
=E(A4) |
=E@b(A4) |
=E(A5) |
=E@s(A5) |
|
6 |
=E(D5) |
=E(E(D5)) |
=A4(1).len().(n=~,A4.(~(n))) |
=E@p(C6) |
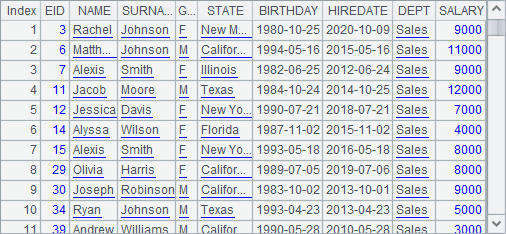
A4 generates a two-dimensional sequence using the first 3 rows of data:

A5 uses E() function to read A4’s two-dimensional sequence as a table sequence. By using @b option, it, similar to T() function, will not display field names. Here are results of A5 and B5:
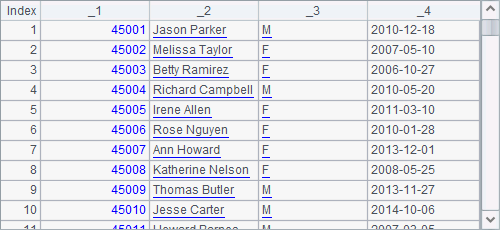
If the parameter of E() function itself is a table sequence, it will be converted to a two-dimensional sequence. Or the function can use @s option to convert it to a string, where records are separated by the carriage return and fields are separated by the tab. Here are results of C5 and D5:

![]()
If the parameter of E() function itself is a string, it will also be converted to a two-dimensional sequence. The function can still use the result as the parameter to get a table sequence. Here are results of A6 and B6:
If data of the two-dimensional sequence is arranged in the order of fields, we can add @p option in E() function to read the transposed two-dimensional sequence as a table sequence. Here are results of C6 and D6:
esProc allows not only importing text data as a table sequence, but exporting the in-memory data to a text file. Usually the to-be-exported data comes from a table sequence or a record sequence, or sometimes, an ordinary sequence. The export function is used to export data to a file.
|
|
A |
|
1 |
=file("employee1.txt") |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>A1.export(A2) |
A1 creates a file object, employee1.txt, to store data. But at this point the file is still stored in the report’s main path. A2 creates a table sequence and inserts two records into it:
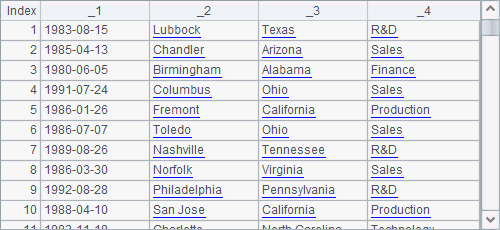
A3 exports data of the table sequence to the employee1.txt file:
The @t option can be used to export the column names. And you can specify certain fields to be exported. For example, by modifying A3’s code into >A1.export@t(A2,NAME), the exported data in employee1.txt will be as follows:
As with the import function, tab is used as the default field separator in the export function. But a user-defined separator is also allowed. For example:
|
|
A |
|
1 |
=file("employee2.txt") |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>A1.export@t(A2;"_") |
A3 uses "_" as the separator in the export function to write the table data into a file. So the exported file employee2.txt should be as follows:
T() function can be used to perform the export, for example:
|
|
A |
|
1 |
employee1.txt |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>T(A1:A2, NAME,EID; ",") |
|
4 |
=T@c(A1,EID,NAME; ",") |
|
5 |
>T@s(A1:A4) |
If T(fn:A, Fi, …; s) function specifies the data source, it will not read data of file fn as a table sequence at execution; instead, it will export data of A to file fn. esProc automatically identify the file type during export according to the file extension. Now execute the above cellset file step by step. After A3 is executed, employee1.txt has the following data:
According to the result, the original data in the file is overwritten after T() function exports data to the file. Similarly, T(fn:cs, Fi, …; s) function can be used to export data in cursor cs to a file. For example, A4 uses T@c(…) function to retrieve data in the file as a cursor, and then A5 exports the cursor data to a file, during which @s option is used to not to display field names. Execute the rest of the code in the above cellset file, view file employee1.txt and find the following data in it:

CSV files are commonly used in data analysis and processing. A CSV file is a text file separated by commas. To generate such a file, you can define the separator directly in the export function or use the @c option. For example:
|
|
A |
|
1 |
=file("employee3.csv") |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>A1.export@tc(A2) |
Below are the two forms of the exported file employee3.csv opened with Excel and with the text tool respectively:

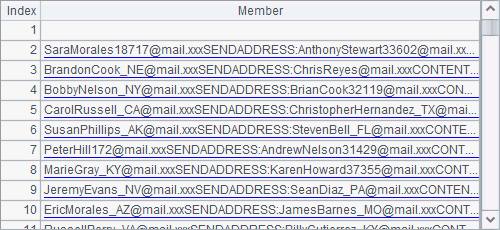
The @c option work with import function to generate a comma-separated data table imported from a text file.
To handle bin files, you just need to add @b option to the export or import function. Details are discussed in Bin Files.
7.7.2 Batch processing of the big text file
When a file holds a large amount of data, to load it all together to the memory may cause an overflow. In this case, it should be imported in batches. To do so, use a file segmentation parameter in the import function to import data by segment. For example:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.import@t(;100:500) |
|
3 |
=A1.import@t(;101:500) |
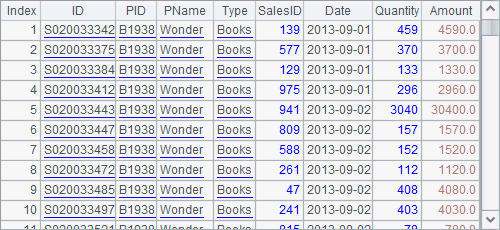
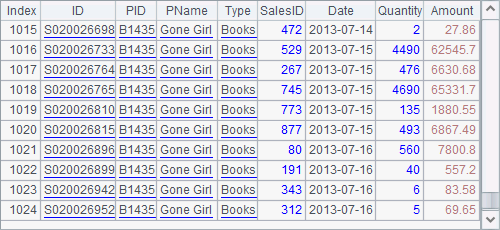
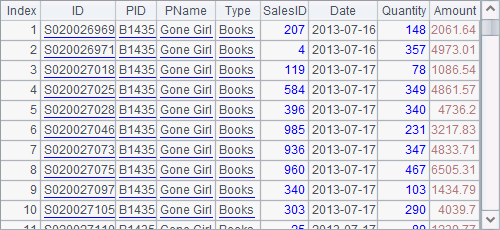
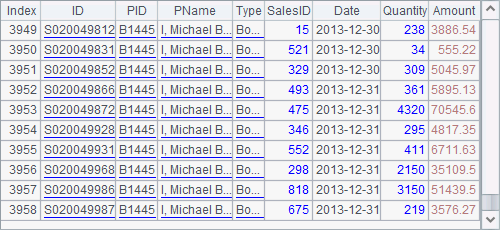
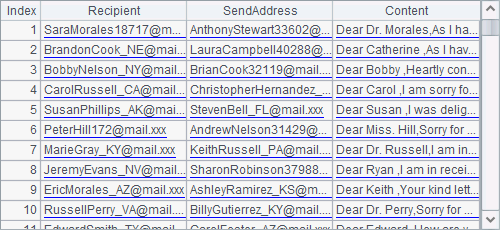
The text file PersonnelInfo.txt holds the personnel information. Both A2 and A3 use a file segmentation parameter in a form like 100:500 in the import function. So A2 divides data into 500 segments and imports the 100th segment. Here’s its result:
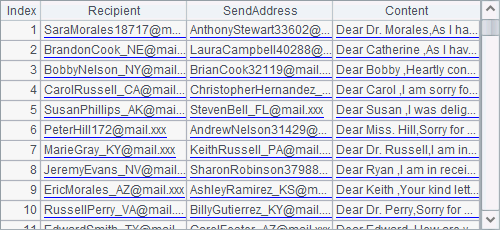
A3 continues to import the 101th segment:
During the batch import, esProc is able to ensure that complete records are imported by adjusting positions for beginning and ending points, and meanwhile maintains the continuity, integrity and uniqueness of the imported data.
Note: With the import function, when a file is imported in batches by being divided into multiple segments, the number of records imported varies with each batch because records have different numbers of bytes. That also explains why a specified row of data cannot be got directly. To locate the record in a specified positon, records need to be traversed one by one until the record is found. This is not efficient at all. Yet, the external file cursor can be used to access the target record precisely, which will be explained in the next section.
By segmenting a large file, a computing task can be divided into multiple subtasks. The method is significant to cluster computing. In The Server Cluster, we’ll discuss the batch processing of a large file using cluster computing.
The export of a big data table to a text file can also be hindered by the limited memory. Because data cannot be entirely loaded into the memory, it cannot be exported to a file at a time. But similarly, the export of a large file can be handled through batch processing. Use @a option in export function to append data to the existing data at each batch of data export. For example:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
=file("PersonnelInfo1.txt") |
|
2 |
for 500 |
=A1 .import@t(ID,Name,State;A2:500) |
|
3 |
|
>B1.export@at(B2) |
A2 runs a loop to import data from PersonnelInfo.txt in 500 batches and specifies certain fields to be written to the new file PersonnelInfo1.txt. @at options are used with the export function to export column names and detailed data by appending each batch to the existing data. When the code is executed, PersonnelInfo1.txt gets the following data:

But without @a option, the existing data in the file will be removed at each export.
7.7.3 Accessing big text files with the cursor
A more convenient tool to process text files containing a large amount of data is the cursor. Cursor functions are ready to be called after the external file cursor is generated based on a text file. For example:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t(ID,Name,Gender,State) |
|
3 |
>A2.skip(10000) |
|
4 |
=A2.fetch(1000) |
|
5 |
=A2.fetch(1000) |
|
6 |
>A2.close() |
A2 creates a file cursor using cursor function, in which @t option is used to import the file’s first row as the column names. A3 skips the first 10,000 rows. A4 and A5 respectively fetch 1,000 rows from A2’s cursor:


Data can be fetched conveniently and quickly by the position from the cursor. As with f.import() in section one, certain fields can be retrieved for creating the cursor and data type can be specified for a certain field with f.cursor().
With the external file cursor, various operations can be easily handled. About its uses, refer to Basic Uses of Cursor and other documents on esProc external memory computations.
Also through the cursor, data can be exported to a file. For example:
|
|
A |
|
1 |
=file("employee2.txt") |
|
2 |
=demo.cursor("select * from EMPLOYEE") |
|
3 |
>A1.export@t(A2,EID,NAME+" "+SURNAME:FullName,GENDER,STATE) |
A2 creates a database cursor. A3 gets the expected result by computing the cursor data and then export it to a file. After the code is executed, employee2.txt holds data as follows:

Exporting data through the cursor is convenient and the code is concise. To retain the existing data during the data export, use @a option to append each batch of data export to the previous data.
esProc also supports accessing bin files with the cursor. Bin files take up less memory space and enable more efficient computations. More details about bin files can be found in Bin Files.