Spark
1. The directory containing files of this external library is: installation directory\esProcext\lib\SparkCli. The Raqsoft core jar for this external library is scu-spark-cli-2.10.jar.
aircompressor-0.10.jar
antlr-runtime-3.5.2.jar
antlr4-runtime-4.8-1.jar
avro-1.8.2.jar
avro-ipc-1.8.2.jar
avro-mapred-1.8.2-hadoop2.jar
chill_2.12-0.9.5.jar
commons-cli-1.2.jar
commons-codec-1.10.jar
commons-collections-3.2.2.jar
commons-compiler-3.0.16.jar
commons-configuration2-2.1.1.jar
commons-io-2.5.jar
commons-lang-2.6.jar
commons-lang3-3.10.jar
commons-logging-1.1.3.jar
compress-lzf-1.0.4.jar
guava-14.0.1.jar
hadoop-auth-3.2.0.jar
hadoop-common-3.2.0.jar
hadoop-hdfs-client-3.2.0.jar
hadoop-mapreduce-client-core-3.2.0.jar
hadoop-mapreduce-client-jobclient-3.2.0.jar
hadoop-yarn-api-3.2.0.jar
hive-cli-2.3.7.jar
hive-common-2.3.7.jar
hive-exec-2.3.7-core.jar
hive-jdbc-2.3.7.jar
hive-llap-common-2.3.7.jar
hive-metastore-2.3.7.jar
hive-serde-2.3.7.jar
hive-shims-0.23-2.3.7.jar
hive-shims-common-2.3.7.jar
hive-storage-api-2.7.2.jar
htrace-core4-4.1.0-incubating.jar
jackson-annotations-2.10.0.jar
jackson-core-2.10.0.jar
jackson-core-asl-1.9.13.jar
jackson-databind-2.10.0.jar
jackson-mapper-asl-1.9.13.jar
jackson-module-paranamer-2.10.0.jar
jackson-module-scala_2.12-2.10.0.jar
jakarta.servlet-api-4.0.3.jar
janino-3.0.16.jar
jcl-over-slf4j-1.7.30.jar
jersey-container-servlet-core-2.30.jar
jersey-server-2.30.jar
jetty-util-7.0.0.M0.jar
joda-time-2.10.5.jar
json4s-ast_2.12-3.7.0-M5.jar
json4s-core_2.12-3.7.0-M5.jar
json4s-jackson_2.12-3.7.0-M5.jar
jul-to-slf4j-1.7.30.jar
kryo-shaded-4.0.2.jar
libfb303-0.9.3.jar
libthrift-0.12.0.jar
log4j-1.2.17.jar
metrics-core-4.1.1.jar
metrics-json-4.1.1.jar
netty-all-4.1.51.Final.jar
orc-core-1.5.12.jar
orc-mapreduce-1.5.12.jar
orc-shims-1.5.12.jar
paranamer-2.8.jar
parquet-column-1.10.1.jar
parquet-common-1.10.1.jar
parquet-encoding-1.10.1.jar
parquet-format-2.4.0.jar
parquet-hadoop-1.10.1.jar
parquet-jackson-1.10.1.jar
parquet-tools-1.11.1.jar
protobuf-java-2.5.0.jar
re2j-1.1.jar
scala-library-2.12.10.jar
scala-reflect-2.12.10.jar
scala-xml_2.12-1.2.0.jar
slf4j-api-1.7.30.jar
slf4j-log4j12-1.7.30.jar
snappy-java-1.1.8.2.jar
spark-avro_2.12-3.1.1.jar
spark-catalyst_2.12-3.1.1.jar
spark-core_2.12-3.1.1.jar
spark-hive-thriftserver_2.12-3.1.1.jar
spark-hive_2.12-3.1.1.jar
spark-kvstore_2.12-3.1.1.jar
spark-launcher_2.12-3.1.1.jar
spark-network-common_2.12-3.1.1.jar
spark-network-shuffle_2.12-3.1.1.jar
spark-sql_2.12-3.1.1.jar
spark-tags_2.12-3.1.1.jar
spark-unsafe_2.12-3.1.1.jar
stax2-api-3.1.4.jar
stream-2.9.6.jar
univocity-parsers-2.9.1.jar
woodstox-core-5.0.3.jar
xbean-asm7-shaded-4.15.jar
zstd-jni-1.4.8-1.jar
Note: The third-party jars are encapsulated in the compression package and users can choose appropriate ones for specific scenarios.
2. Download the following four files from the web and place them in installation directory\bin:
hadoop.dll
hadoop.lib
libwinutils.lib
winutils.exe
Note: The above files are required under Windows environment, but not under Linux. There are x86 winutils.exe and x64 winutils.exe depending on different OS versions.
3. SparkCli requires a JRE version 1.7 or above. Users need to install a higher version if the esProc built-in JRE version does not meet the requirements, and then configure java_home in config.txt under installation directory \esProc\bin. Just skip this step if the JRE version is adequate.
4. Users can manually change the size of memory if the default size isn’t large enough for needs. Under Windows, make the change in config.txt when starting esProc through .exe file; and in .bat file when starting the application through the .bat file. Make the modification in .sh file under Linux.
To modify the config.txt file under Windows:
java_home=C:\ProgramFiles\Java\JDK1.7.0_11;esproc_port=48773;btx_port=41735;gtm_port=41737;jvm_args=-Xms256m -XX:PermSize=256M -XX:MaxPermSize=512M -Xmx9783m -Duser.language=zh
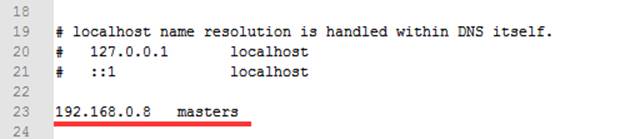
5. On the machine where esProc is installed, find the hosts file to add the IP address and hostname of the machine holding the Spark system. For example, if the IP address and hostname are 192.168.0.8 and masters respectively, here are the settings:
6. esProc provides functions spark_open(), spark_query(), spark_cursor() and spark_close() to access the Spark systems. Look them up in【Help】-【Function reference】to find their uses.