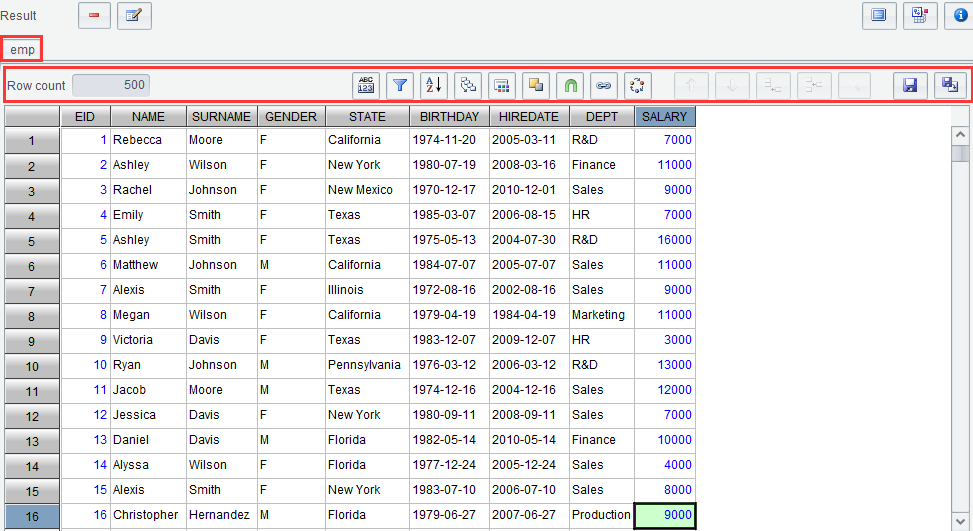
Edit result
After a
result set is named, we can perform operations on it, such as filtering,
sorting, grouping, set operation, add, delete, modify, and export. For example,
we click ![]() to rename the above result set emp:
to rename the above result set emp:

Click “OK” to get the following interface displaying the result set:
【Row count】The number of records displayed in the current result set.
【Rows to fetch】
When the result type is cursor, the number of records for the first retrieval is by default at most 1024. To fetch records continuously, set up the 【Rows to fetch】option to get more.
For example, to retrieve data from a file having ten thousand records, set up the open way as “Special open” and result type as cursor, click “OK” and retrieve a number of records as shown below:

Then set up the value of 【Rows to fetch】as 2000 and the next 2000 records will be fetched. Now the number of records displayed in the current dataset is 3024:
![]()
Edit data
This section explains how to perform common operations, including add, delete, and modify, etc., on a result set.
Ø Shift row up
Select a row and click ![]() to move it up.
to move it up.
Ø Shift row down
Select a row and click ![]() to move it down.
to move it down.
Ø Append row
Select a row and click ![]() to add a row after the last row
of the result set.
to add a row after the last row
of the result set.
Ø Insert row
Select a row, and click ![]() to insert a row before the
current row.
to insert a row before the
current row.
Ø Delete row
Select one or more rows, and click ![]() to delete it/them.
to delete it/them.
Ø Copy
Select one or more rows, right-click the row number(s) area on the left side, and select copy option to copy the selected row(s) to clipboard.
Ø Cut
Select one or more rows, right-click the row number(s) area on the left side, and select cut option to cut the selected row(s).
Ø Paste
Select one or more rows, right-click the row number(s) area on the left side to select paste option to paste data on the clipboard to the current position. Note that the action requires that data structure on the clipboard be the same as that of the current table.
Ø Shift column left
Select a column and click ![]() to move the current column
left.
to move the current column
left.
Ø Shift column right
Select a column and click ![]() to move the current column
right.
to move the current column
right.
Ø Append column
Select a column and click ![]() to add a column after the last
column of the result set.
to add a column after the last
column of the result set.
Ø Insert column
Select a column and click ![]() to insert a column to the left
of it.
to insert a column to the left
of it.
Ø Delete column
Select one or more columns, and click ![]() to delete it/them.
to delete it/them.
Ø Sort by field
Select a column, and right-click the column number area in the upper part to sort records by the current field in ascending or descending order.
Ø Rename field
Select a column, and right-click the column number area in the upper part to rename the current column.
Ø Modify
Select a cell and click it to modify data in it.
Complex computation
This section explains how to perform complex computations on data, such as filtering, sorting and grouping.
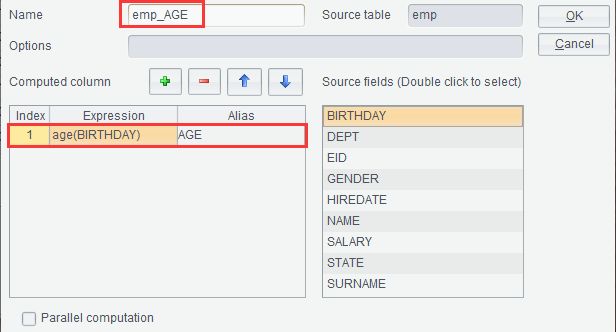
Ø Computed column
We can add user-defined columns to an existing result set through this “Computed column” functionality and generate a new result set. To add columns AGE to the following emp result set and generate new result set emp_AGE, for example:
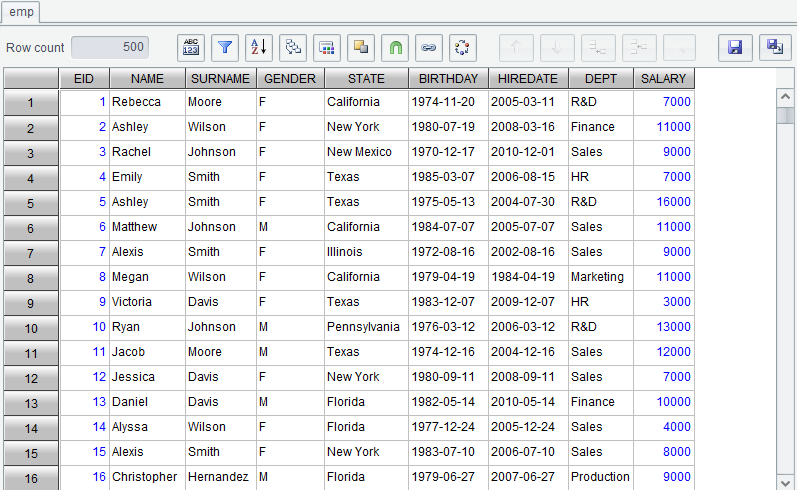
On the result set page, click ![]() or right-click to select a
computed column and get into the configuration window:
or right-click to select a
computed column and get into the configuration window:
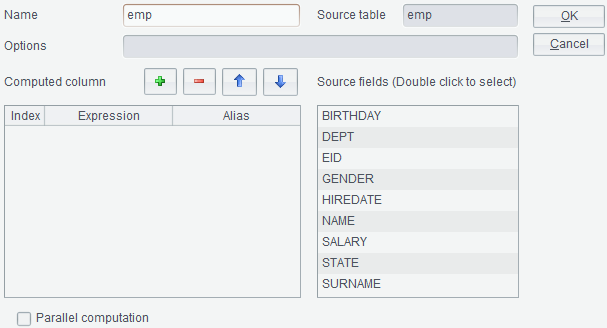
【Parallel computation】Use the parallel processing to increase performance when the computation is complex and involves a huge volume of data; data won’t be computed in a certain order.
Click ![]() to add a new column, whose expression
is age(BIRTHDAY) and alias is AGE and that generates a new result set named
emp_AGE.
to add a new column, whose expression
is age(BIRTHDAY) and alias is AGE and that generates a new result set named
emp_AGE.
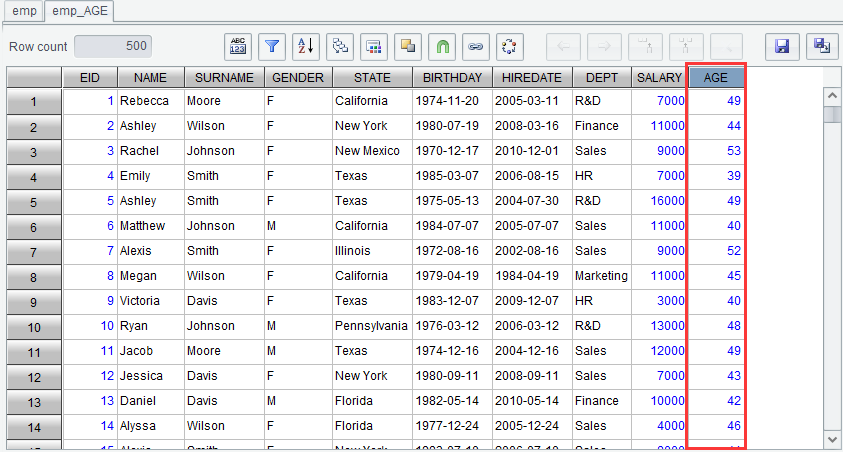
Click “OK” and generate new result set emp_AGE as follows:
Ø Filter
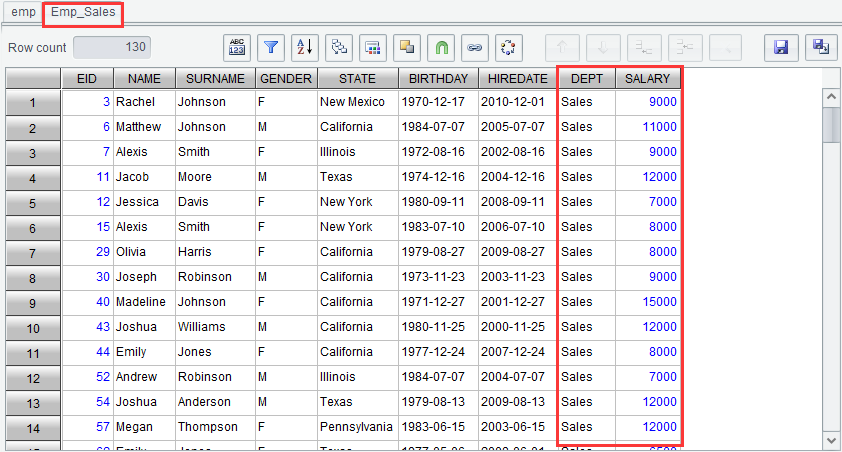
To perform filtering on data of the result set, click “Filter” icon ![]() or right click to choose
“Filter” on the “Result” tab, and select eligible records according to the
specified filter expression. To get records employees in sales department whose
salary are above 5,000 from result set emp, the filter expression is DEPT ==
"Sales" && SALARY > 5000 and the result set name is set as
Emp_Sales, as shown below:
or right click to choose
“Filter” on the “Result” tab, and select eligible records according to the
specified filter expression. To get records employees in sales department whose
salary are above 5,000 from result set emp, the filter expression is DEPT ==
"Sales" && SALARY > 5000 and the result set name is set as
Emp_Sales, as shown below:
Click “OK” and generate new result set Emp_Sales as follows:
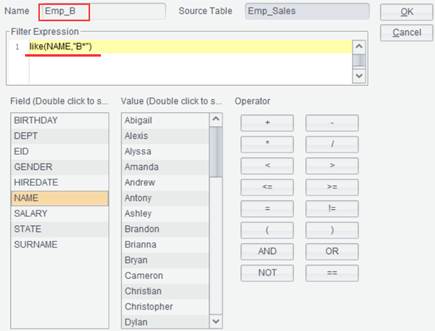
In a filter expression, we can also use an esProc function besides operators. To further filter the above result set Emp_Sales to get records of employees whose names start with letter B, the filter expression is like(NAME,"B*") and result set name is Emp_B, as shown below:
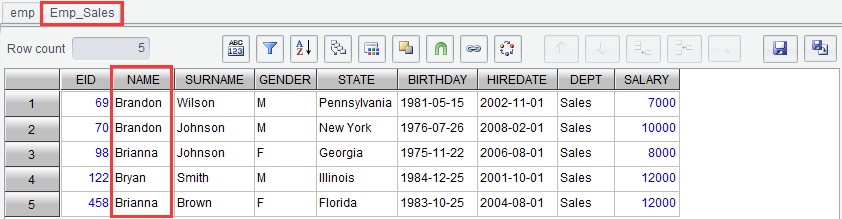
Click “OK” and we get new result set Emp_B as follows:
Ø Sort
On the “Result” tab, click “Sort” icon ![]() or right-click to select “Sort”
and set the sorting field and sorting direction to display data in the result
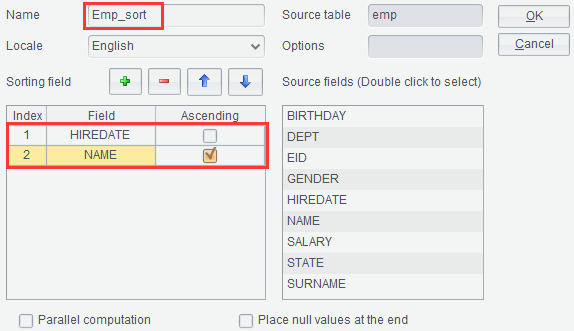
set in a certain order. To sort result set emp by HIREDAE in descending
order and by NAME in ascending order and name the result set after sorting Emp_sort,
for example:
or right-click to select “Sort”
and set the sorting field and sorting direction to display data in the result
set in a certain order. To sort result set emp by HIREDAE in descending
order and by NAME in ascending order and name the result set after sorting Emp_sort,
for example:
【Parallel computation】Use parallel processing to increase performance when the computation is complex and involves a huge volume of data.
【Place null values in the end】Put records where the sorting field values are null in the end.
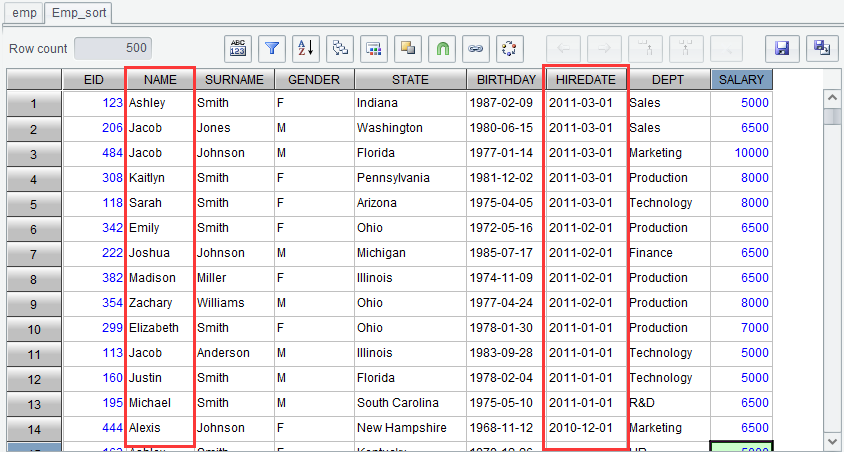
Click “OK” to generate new result set Emp_sort as follows:
We can also double click a field on the table header to sort the result set according to the current column. To sort result set emp by SALARY, double click SALARY field to sort values in ascending order:
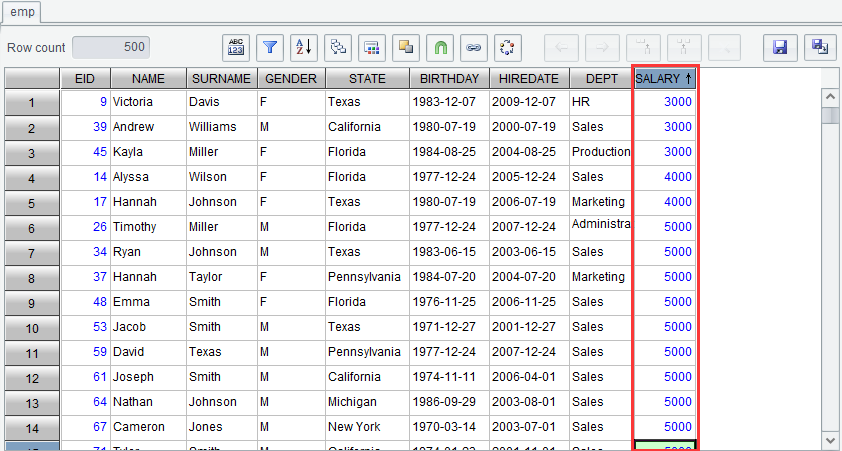
Double click SALARY field again to sort values in descending order.
Ø Select fields
On the “Result” tab, click “Select fields” button ![]() or right-click to select
fields. This lets us compute the specified expression on certain fields of the
result set to generate a new result set. For example, select EID, NAME, SURNAME,
HIREDATE and SALARY from data set emp, join up NAME and SURNAME to form
NAME field, compute hire duration according to HIREDATE and generate Seniority
field, and correspond each EID with two records, which are the original salary
SALARY and the SALARY value after 50% salary increase:
or right-click to select
fields. This lets us compute the specified expression on certain fields of the
result set to generate a new result set. For example, select EID, NAME, SURNAME,
HIREDATE and SALARY from data set emp, join up NAME and SURNAME to form
NAME field, compute hire duration according to HIREDATE and generate Seniority
field, and correspond each EID with two records, which are the original salary
SALARY and the SALARY value after 50% salary increase:
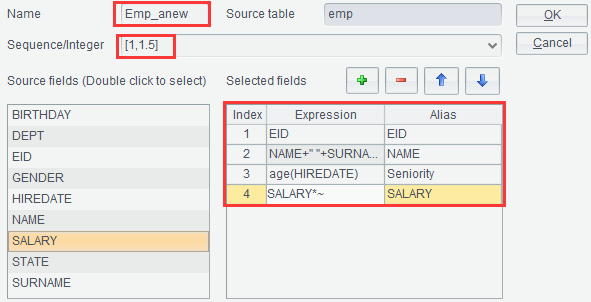
【Sequence/Integer】Optional. Suppose the content to-be-entered is parameter X, then in the selected fields expression we can use “~” to reference X, which can be a sequence or an integer. When it is an integer, it can be understood as to(X), which means performing X round of computations on the result set.
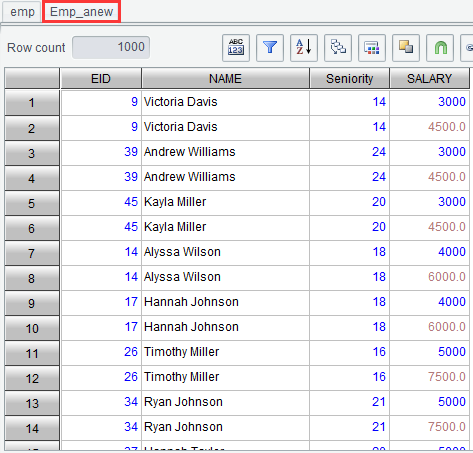
Click “OK” and generate a new result set Emp_anew as follows:
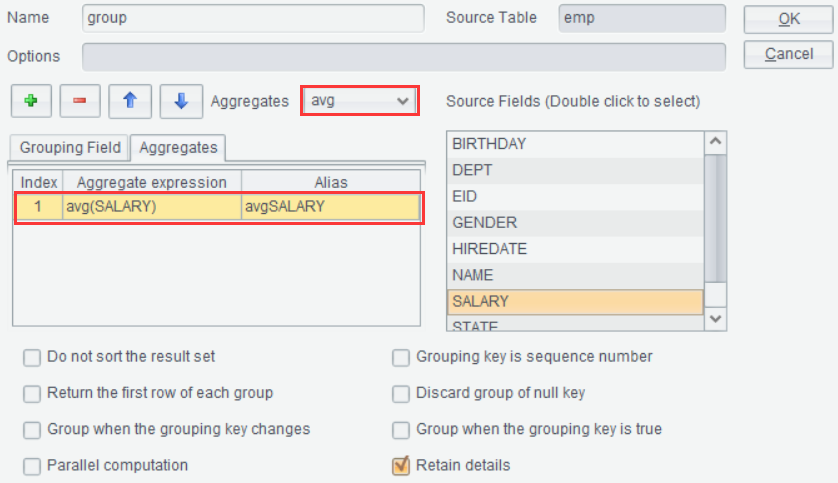
Ø Group
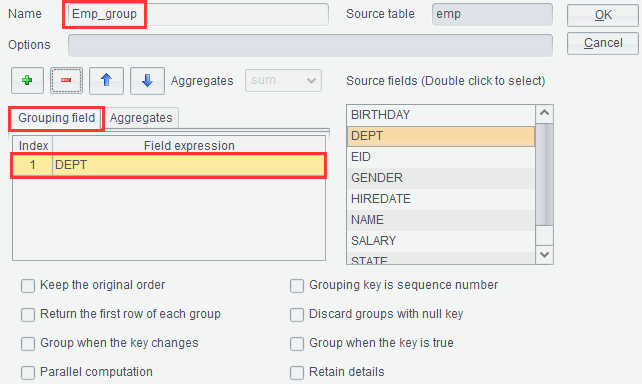
On the “Result” tab, click “Group” icon ![]() or right-click to select “Group”.
This lets us to perform grouping & aggregation on a result set. For
example, group result set emp by DEPT field and compute average salary
and the number of employees in each group:
or right-click to select “Group”.
This lets us to perform grouping & aggregation on a result set. For
example, group result set emp by DEPT field and compute average salary
and the number of employees in each group:
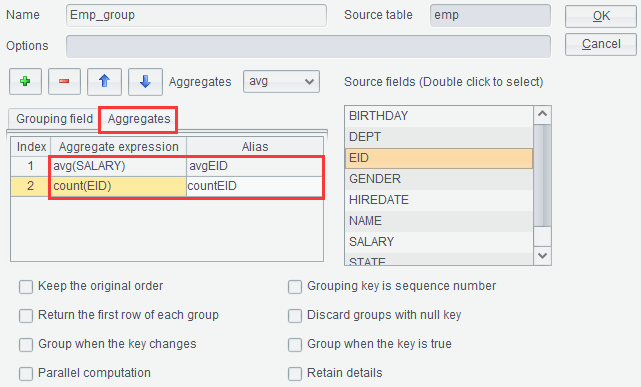
【Do not sort the result set】Do not sort result set according to the grouping field.
【Grouping key is a sequence number】When the grouping key value is a sequence number, use them to locate the target record directly.
【Return the first row of each group】Return values of the current group. When “Keep details” is also selected, get the first record of every group and union them to return; in this case, ignore the other options.
【Discard group of null key】Delete a group on which result of computing the grouping field expression is null.
【Group when the grouping key changes】Compare the grouping key value with that of the directly next record – the operation is equivalent to the merge, and do not sort the result set.
【Group when the grouping key is true】Create a new group whenever result of computing the grouping field expression on the current record is true.
【Parallel computation】Use parallel processing to increase performance when the computation is complex and involves a huge volume of data.
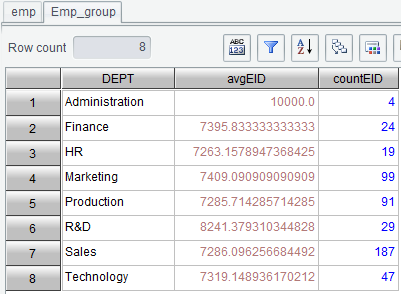
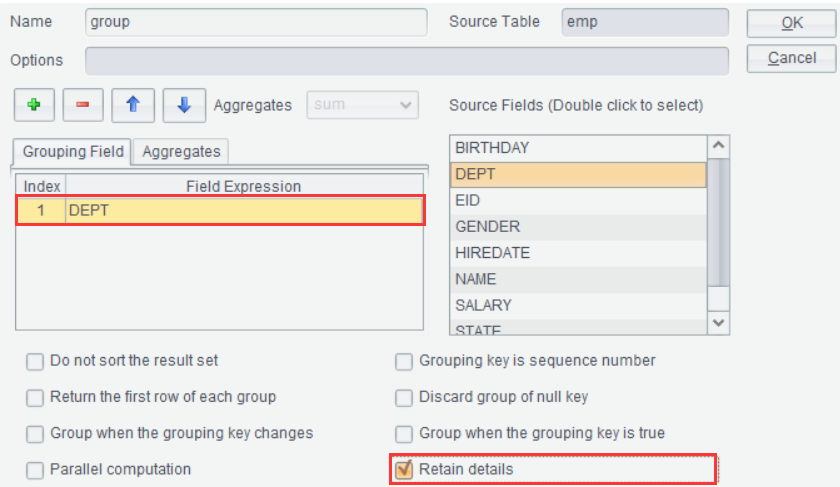
【Retain details】 Add a details field to store records before each group is summarized.Click “OK” and generate a new result set Emp_group as follows:
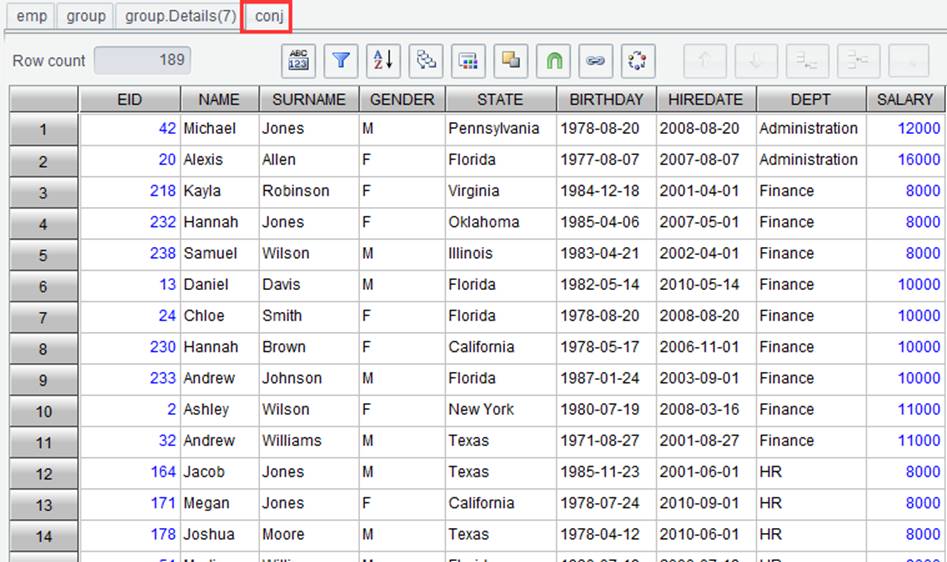
Ø Concatenate detailed data
On the “Result” tab, click “Concatenate
detailed data” icon ![]() or right-click a result set to select “Concatenate detailed data” to
group records, perform filtering and then perform the concatenation operation. For example,
find all employees from each department whose salaries are above the average
salary of their department.
or right-click a result set to select “Concatenate detailed data” to
group records, perform filtering and then perform the concatenation operation. For example,
find all employees from each department whose salaries are above the average
salary of their department.
First, click ![]() icon to get into “Group” window to group
result set emp by DEPT while keeping the detail data:
icon to get into “Group” window to group
result set emp by DEPT while keeping the detail data:
Set average salary as the aggregate value:

Click “OK” and get the grouping result:
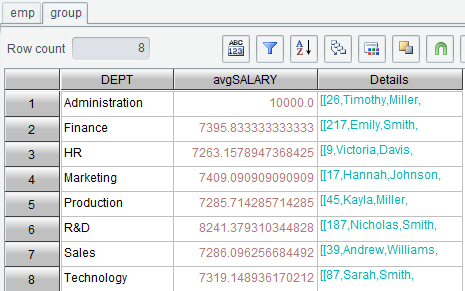
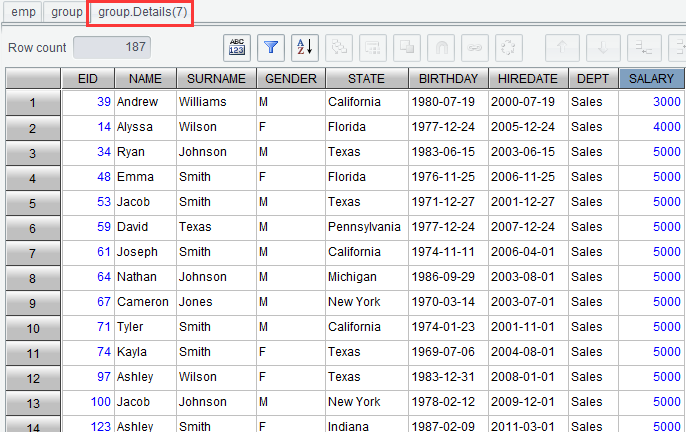
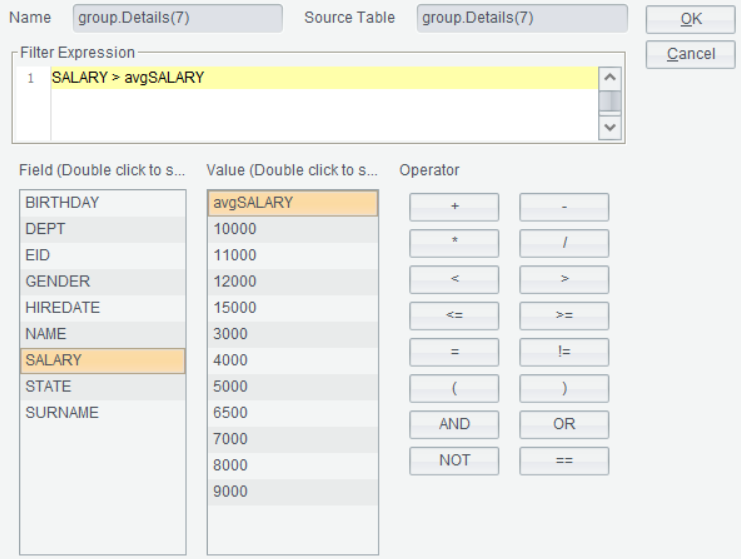
Open detail data in Sales department:
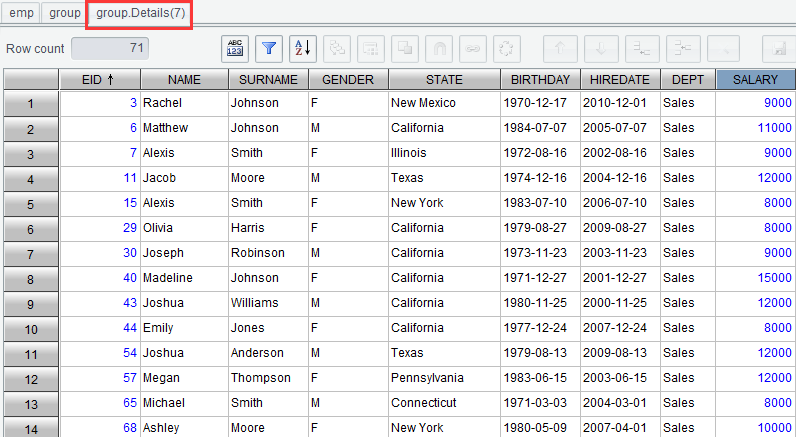
Click ![]() to set filtering condition as SALARY>avgSALARY:
to set filtering condition as SALARY>avgSALARY:

And get the following result:
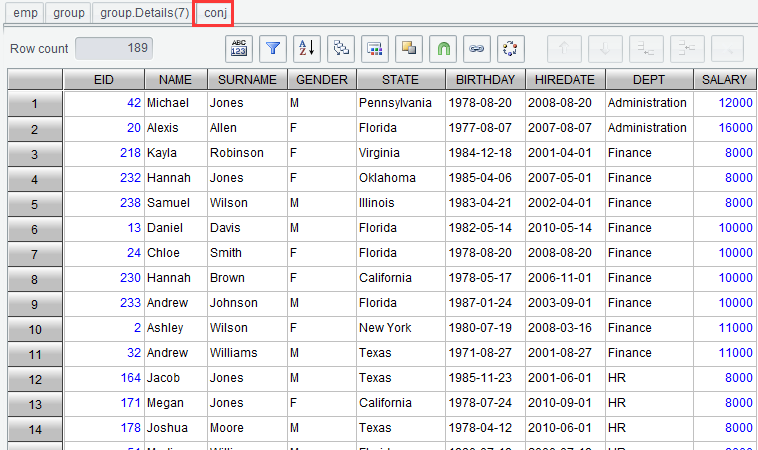
Then switch to the grouping result
set tab to concatenate all the detail data. Click ![]() to enter “Concatenate detailed data” window:
to enter “Concatenate detailed data” window:

【Perform recursive computation】 Recursively perform the operations until no sequence-type members exist.
Click “OK” and get the final filtering result:
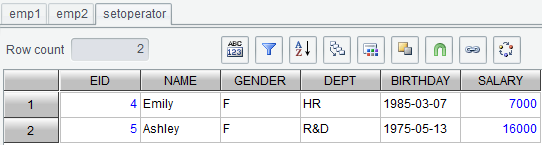
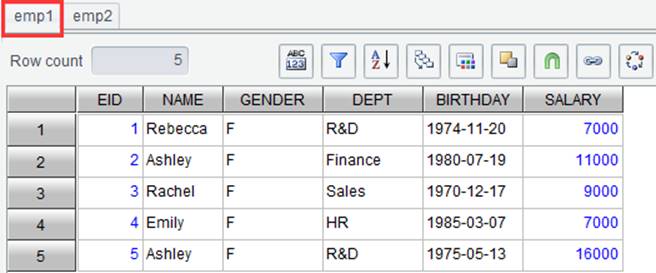
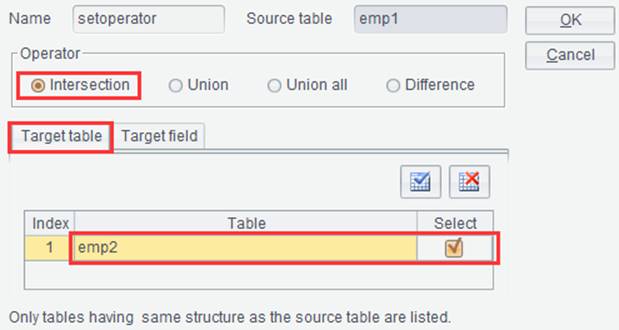
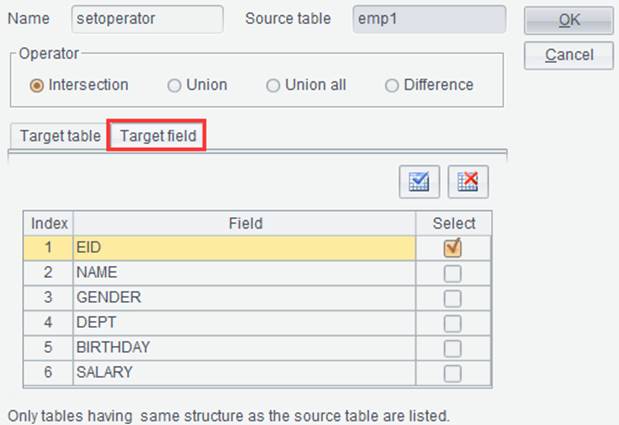
Ø Set operation
On the “Result” tab, click “Set operation” button ![]() or right-click to select “Set
operation”. For example, we have result sets emp1 and emp2, and
trying to union them. Below are contents of the two result sets:
or right-click to select “Set
operation”. For example, we have result sets emp1 and emp2, and
trying to union them. Below are contents of the two result sets:


Click ![]() on result set emp1 and
enter the set operation configuration interface:
on result set emp1 and
enter the set operation configuration interface:
Click “OK” and generate a new result set as follows:
Ø Data association
On the “Result” tab, click “Join” button ![]() or right-click to select “Join”
to associate data in multiple result sets through the join fields.
or right-click to select “Join”
to associate data in multiple result sets through the join fields.
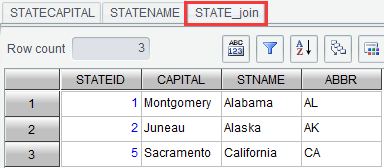
Suppose there are two result sets STATECAPITAL and STATENAME, perform an inner join on the two through STATEID field:

Click ![]() on the interface of result set STATECAPITAL
and enter the data association configuration interface to choose join type and
set up tables to be joined:
on the interface of result set STATECAPITAL
and enter the data association configuration interface to choose join type and
set up tables to be joined:
Set up the join field:

Set up the target fields and their aliases:
Click “OK” and generate new result set STATE_join as follows:
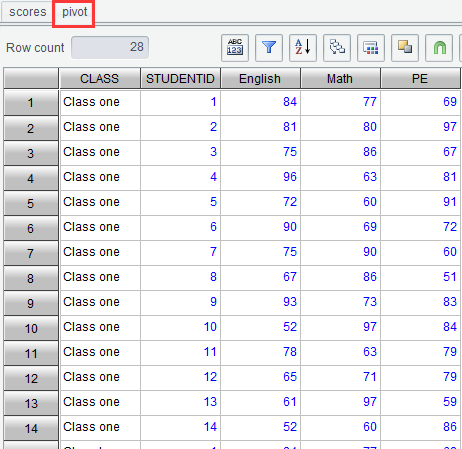
Ø Pivot
On the “Result” tab, click “Pivot” icon ![]() or right-click to select the “Pivot” option to perform row-to-column transposition on the result set.
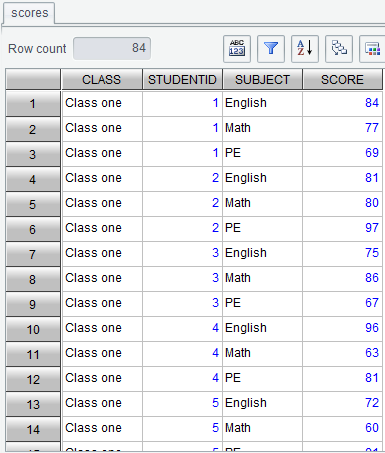
For example, we need to perform a row-to-column transposition on result set scores.
Group records by CLASS and STUDENTID, make SUBJECT field values English, Math
and PE the new column names, and then re-distribute the original SCORE field
values to the new columns.
or right-click to select the “Pivot” option to perform row-to-column transposition on the result set.
For example, we need to perform a row-to-column transposition on result set scores.
Group records by CLASS and STUDENTID, make SUBJECT field values English, Math
and PE the new column names, and then re-distribute the original SCORE field
values to the new columns.
Below is result set scores:
Click ![]() to pop up the following “Pivot” window:
to pop up the following “Pivot” window:
Double-click CLASS and STUDENTID under “Source Fields” to select the grouping fields and then choose the “New columns’ source field” and “Detail data column”:
【Transpose column to row】Perform column-to-row transposition; it is best to use user-defined “New columns’ source field” and “Detail data column” for this operation.
Click “OK” to get result of row-to-column transposition: