2.3.2 TSeqs-sequences with structure
esProc inherits the concept of data table in relational databases, and defines it as table sequence. Consistent with the relational database’s definition of the data table, every table sequence has its own data structure, which consists of fields. Members of a table sequence are called as records.
Two-dimensional structured data objects
A member of a sequence can be any data type, such as an ordinary type, a sequence and a record; while members of a table sequence must be records of the same structure. The following data object is a table sequence:
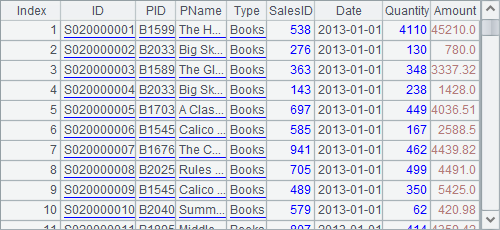
Because a table sequence is a two-dimensional structured data object, it is usually generated from SQL statements, text files, bin files, Excel files or an empty table sequence. The results of A1, A2 and A3 in the following cellset are table sequences:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=demo.query("select * from CITIES") |
|
3 |
=create(OrderID,Client,SellerId,Amount,OrderDate) |
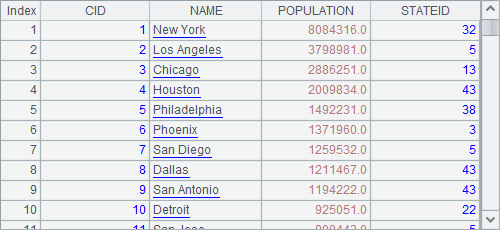
A1 generates a table sequence, which is the one in the above, from a text file. A2 generates a table sequence using SQL, and C1 creates an empty table sequence by specifying the field names. The table sequences in A2 and A3 are as follows:
A great number of algorithms for structured data, such as data querying, data sorting, summing up values, finding average value, and merging duplicate records, can be performed on table sequences. For example:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=A1.select(Amount>=20000 && month(Date)==5) |
|
3 |
=A1.sort(SalesID,-Date) |
|
4 |
=A1.groups(SalesID, month(Date); round(sum(Amount),2), count(~)) |
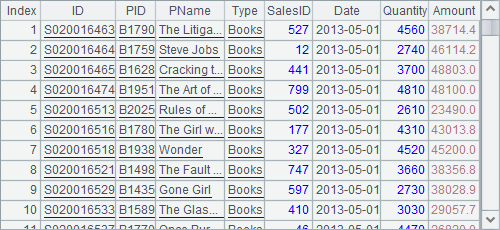
A2 selects records whose Amount is greater than or equal to 20,000 and whose Date falls in the month of May:
A3 sorts the records by SalesID in ascending order and those with the same SalesID by Date in descending order:
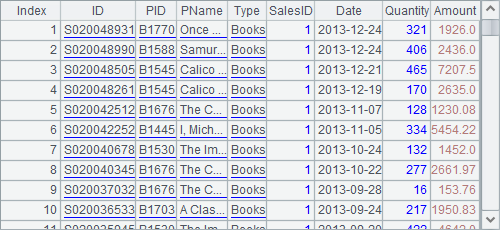
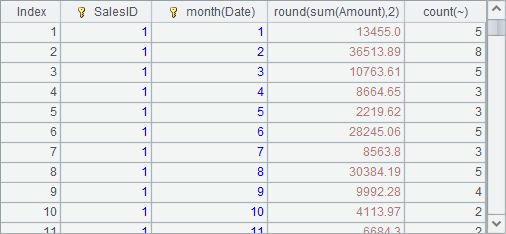
A4 groups the records by SalesID and the month, and then sums up Amount and counts the orders in each group:
A table sequence is still a sequence, so it has the sequence’s features of collectivity and orderliness, and can use sequence-related functions. A table sequence isn’t generic in the sense of a sequence because its members must be records of the same structure. But, the field values of the records can be generic data, which in this sense is another form of genericity. Thanks to these characteristics, a table sequence is conveniently usable in handling complicated computations, compared with the traditional programming languages.
For example, to compute the monthly growth rate of the sales amount, esProc takes advantage of the table sequence’s orderliness to write the following algorithm:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=A1.groups(month(Date); sum(decimal(string(Amount))):TotalAmount, count(~):Count) |
|
3 |
=A2.derive(round(TotalAmount/TotalAmount[-1]-1,4): compValue) |
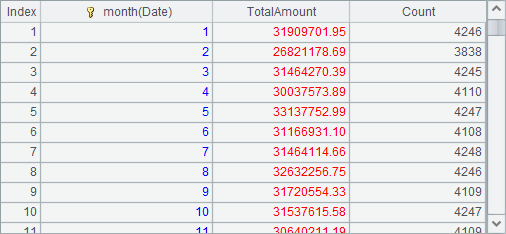
A2 computes the total sales amount in each month:
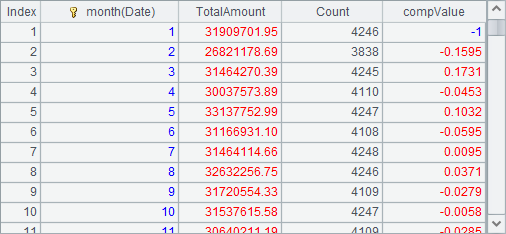
A3 computes the final result:
This instance is based on the collectivity. Assume that in a certain business a big contract is one whose quantity is greater than 1,000 and an important contract is one whose amount is more than 10,000. Please find out: 1. Contracts that are both large and important; 2. The other contracts:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
Big |
=A1.select(Quantity>1000) |
|
3 |
Importance |
=A1.select(Amount>10000) |
|
4 |
=B2^B3 |
=A1\A4 |
B2 selects the big contracts, and then B3 selects the important ones. A4 computes the intersection of the two kinds of contracts, which is the answer to question 1:
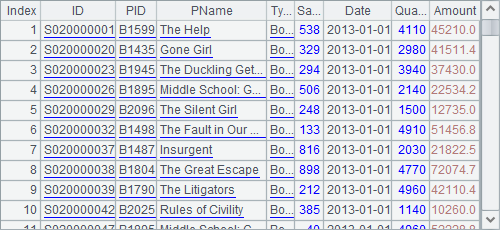
B4 answers question 2 by computing the difference of all orders and the result of question 1:
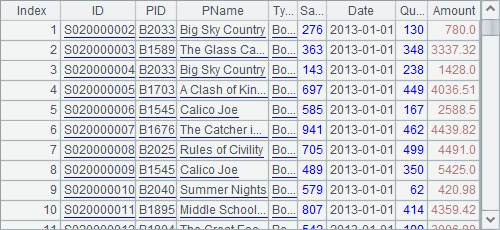
Note: In the above code, A1 contains a table sequence, while, B2, B3, A4 and B4 are all record sequences originating from the table sequence. The difference and relation between the table sequence and the record sequence will be explained in the following section.