cs.group(x:F,…;y:G,…)
Description:
Attach the action of grouping and aggregating records by comparing only adjacent records to a cursor and return the original cursor.
Syntax:
cs.group(x:F,...;y:G,…)
Note:
The function attaches a computation to cursor cs, which groups records in cursor cs according to expression x whose results are values of field F and computes aggregate expression y over each group, whose results are values of field G, and forms a table sequence consisting of F,... G,…. Fields to return to the original cursor cs. The function supports a multicursor.
cs is ordered by x whose values are only compared with their neighbors; and the resulting set won’t be sorted again.
This is a delayed function.
Parameter:
|
cs |
A cursor |
|
x |
Grouping expression |
|
F |
Field name |
|
G |
Aggregation field name |
|
y |
Aggregate expression |
Option:
|
@s |
Cumulative aggregation |
|
@q(x:F,…;x’:F’,…; y:G,…) |
Used when parameter cs is ordered by x,… and only fields after it need to be sorted; support in-memory sorting |
|
@sq(x:F,…;x’:F’,…; y:G,…) |
Only sort without grouping when parameters y:G are absent, and perform cumulative aggregation when the parameters are present; @s works only when @q option is present |
|
@e |
Return a table sequence consisting of results of expression y to the original cursor; grouping expression x is a field of cs and y is function on cs; the result of computing y must be one record of cs; and y only supports maxp, minp and top@1 functions when it is an aggregate expression; When @sev options work together, the function returns a pure table sequence |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
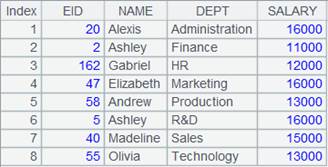
=demo.cursor("select * from SCORES").sortx(CLASS,STUDENTID) |
Return a cursor whose data is ordered by CLASS and STUDENTID fields; below is the content:
|
|
2 |
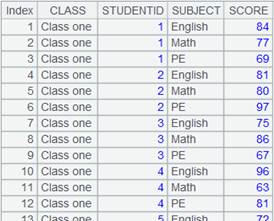
=A1.group(CLASS:Class,STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
Attach a computation to cursor A1, which groups records in the cursor by comparing neighboring CLASS and STUDENTID values and computes total scores, which are made TotalScore field values, in each group, and return the original cursor. |
|
3 |
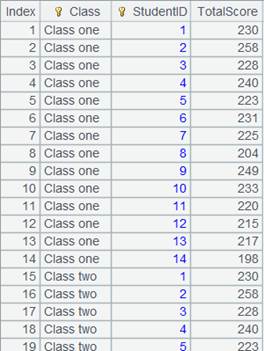
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|
When @q option works:
|
|
A |
|
|
1 |
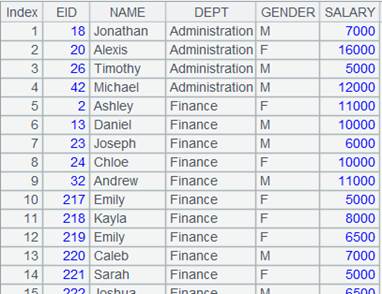
=demo.cursor("select EID,NAME,DEPT,GENDER,SALARY from EMPLOYEE ").sortx(DEPT) |
Return a cursor whose data is ordered by DEPT field; below is the content:
|
|
2 |
=A1.group@q(DEPT;GENDER;~.avg(SALARY):Avg_Salary) |
Attach a computation to cursor A1 that is ordered by DEPT and where only GENDER field needs to be ordered; @q option is used to enable an in-memory sorting, and return the original cursor. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|
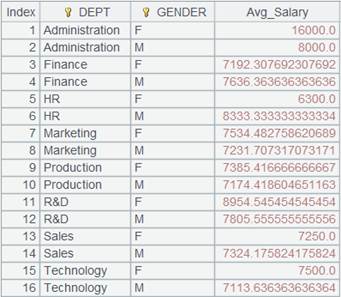
@sq options work to enable sorting without aggregation:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,SALARY from EMPLOYEE ").sortx(DEPT) |
Return a cursor whose data is ordered by DEPT field; below is the content:
|
|
2 |
=A1.group@sq(DEPT;GENDER) |
Attach a computation to cursor A1 ordered only by DEPT; here the function does not specify the aggregate parameter is absent and use @sq options to sort without grouping, and returns the original cursor. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|
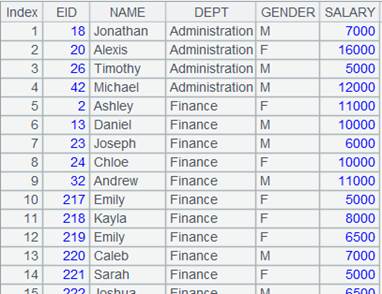
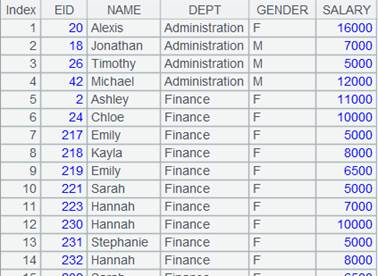
With @e option, return a table sequence consisting of results of expression y to the original cursor:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,SALARY from EMPLOYEE ").sortx(DEPT) |
Return a cursor whose data is ordered by DEPT field; below is the content: |
|
2 |
=A1.group@e(DEPT;~.maxp(SALARY)) |
Attach a computation to cursor A1; the function work with @e option to return the result records of computing maxp(SALARY) to the original cursor. |
|
3 |
=A1.fetch() |
Fetch data from cursor A1 where A2’s computation is executed:
|